Intel视频处理与分析技术栈和架构纵览

面向WebRTC的英特尔协同通信开发套件设计了一个端到端的全流程实时视频流分析系统,帮助开发者使用极简的代码快速实现符合自身需求的高效实时视频流分析应用。本文来自英特尔开源技术中心研发经理 翟磊在LiveVideoStackCon 2018中的演讲,并由LiveVideoStack整理而成。
文 / 翟磊
整理 / LiveVideoStack
大家好,我叫翟磊,来自英特尔开源技术中心。今天我演讲的主题是《基于英特尔架构的实时视频流分析系统的设计与优化》,主要会从以下几个方面进行介绍:首先,背景介绍;其次,我会通过硬件和软件两个层面,来对英特尔视觉云计算平台进行详细的介绍,但主要还是侧重于软件层面。然后,结合我们现在正在做的一个名为Intel Collaboration Suite for WebRTC的项目实践来跟大家讲述一下,如何快速地在英特尔计算平台上构建一个实时、可扩展的实时视频流分析系统,最后,我会做一些总结。

一、背景介绍
当前,我们正在处在一个万物互连的IoT时代。现在通过网络互连的IoT设备,数量上基本已经达到了百亿级,而且这个数字到2020年可以达到超过五百亿的级别。我们通常认为视频是IoT设备对外界进行视觉感知的一个接口。因此,如何通过实时视频分析来帮助IoT设备能够更好地对外界进行视频理解,成为了构建一个智能IoT社会的关键。随着社会和技术的发展,我们也非常高兴的看到,实时视频分析已经深入到了各个行业中。

正因为有了实时视频分析,在生活中的一些险情可以及时的被发现和控制;正因为有了实时视频分析,可以不用亲自跑去银行,在自动柜员机即可开户、销户等;正因为有了实时视频分析,司机可以在自己违章之后的几秒钟或几分钟后,就能够收到短信通知,起到一个很好的提醒作用。此外,实时视频分析还应用在其他的一些领域,比如在自动驾驶、响应式零售、智能制造等领域都发挥了非常重要的作用。
然而,实时视频分析的广泛应用在很大程度上得益于深度学习技术的飞速发展。
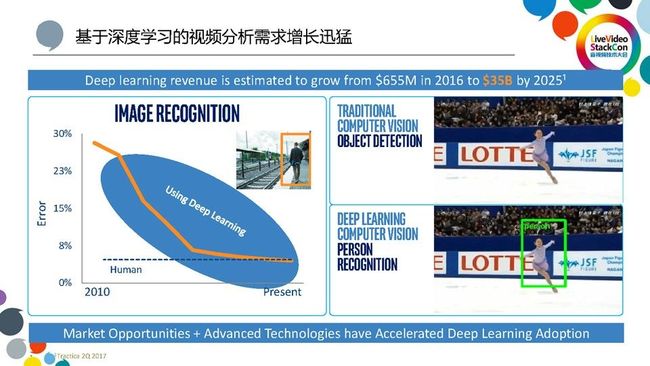
我们不得不说,实时视频分析的广泛应用是与深度学习的技术的发展是离不开的。深度学习作为人工智能的一个主要发展方向,它在特定领域已经奠定了其颠覆式的地位,包括视觉分析和语音分析。有别于传统的视觉分析算法,目前在图像识别领域,深度学习的能力已经达到甚至超过了人类的认知水平。随着深度学习带来的在识别率上的大大提升,同时它也带来了一些挑战。因为深度学习需要大量的计算,我们就需要去更加深入地优化我们的程序,让程序在硬件平台上能够满足深度学习计算的要求。
下面我给大家讲一个典型的例子,一起来看看构建一个实时视频分析流的典型流程。

这是一个人脸识别的系统。第一步,需要构建一个pipeline,包括从摄像头读取到数据,然后进行CSC转换和缩放,再把它送入到第一个深度学习框架FaceDetection。在识别出所有的人脸之后,我们对在原图上的所有人脸都进行分割,分割出来的可能会有若干个,再把分割之后的图像送到第二个深度学习网络FaceRecognition进行识别。在深度识别出来之后,可以将识别出的一些属性进行存储,也可以按照需要在原图上进行标注。我们可以把合成视频直接送去显示,或者Encode后准备进一步深入处理。以上看到的人脸识别的程序并不简单,在这里我们需要用到传统的视觉计算方法,包括对图像的前处理、后处理,包含了编解码、图像转换,同时也融合了深度学习的一些方法,包括人脸识别和检测。
二、Intel视觉计算平台介绍
对于开发者来讲,我们需要的是一个在硬件平台上一站式的工具,利用这个工具既能够做传统的视觉计算,也可以做一些深度学习的计算。这样一来,开发者很快就可以构建出一个pipeline。Intel视觉计算平台就是为了给开发者提供一个一站式的工具,在这里也面临有很多的难题。首先,在构建一个pipeline的同时,还需要将其放在硬件上去跑。目前来讲,能够进行视觉计算的平台有很多,如CPU、GPU、硬件加速器VPU等等。但因为每个平台的特性和接口都不一样,为了适应不同终端用户的场景,是不是需要为每个硬件都提供的一个程序来进行优化呢?其次,上述的pipeline只是单个的摄像头输入,如果要构建一个实时视频流处理的服务,如何应对大容量或高并发的访问请求呢?为了构建一个好的计算平台,复杂性、性能和扩展性都是摆在我们面前的问题。
一个好的计算平台从硬件、软件上应该能够提供一种便利性,来帮助开发者能够快速的构建一个深度学习和视觉计算的应用。为了达到这样的目标,英特尔平台从平台工具、框架、函数库、硬件都提供了一个全站式的支持。
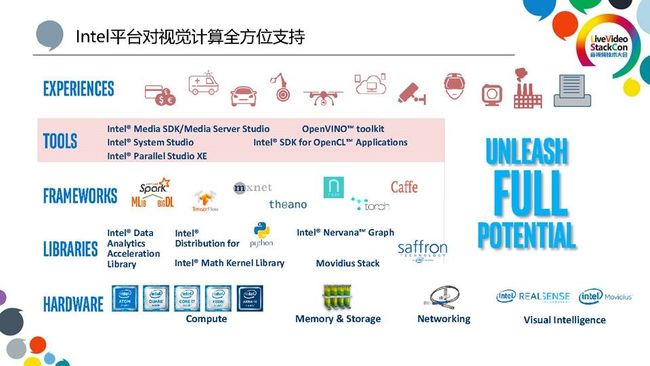
首先,在硬件层面上,我们有CPU、集成显卡、FPGA和VPU之类等等。大家可能对硬件有个误区,比如说对于深度学习,有人可能觉得我们更多的是用一些专用的加速卡来处理,而CPU在这方面就没有什么作用。其实不然,在数据中心里面CPU依然对深度学习应用发挥着非常大的作用。包括在训练的时候,你可以用现有的CPU集群进行分布式的训练。特别是对于推导来讲,CPU依然是数据中心里面做推导的主流平台,因为推导的运算要求比训练低不少。如果说确实有些特殊的场合计算量特别大导致必须要加速,我们英特尔也是提供了一些加速器。对于推导的过程,我们提供有集成显卡、FPGA以及低功耗的Movidius VPU,Movidius VPU在很多嵌入式领域有着非常广泛的应用,包括谷歌、大华等都使用得非常好。对于训练的过程,我们也会陆续推出新的硬件来进行加速。在软件层面上,我们有一些自己的函数库,同时也会对一些比较流行的第三方框架和函数库进行优化,使其在英特尔平台上能够达到一个更好的效果,比如对一些函数核心库、深度学习框架TensorFlow、Caffe等都有比较好的优化。在工具层上,我们也是推出了很多自研的工具包能够加速开发。
今天我想重点讲的就是今年发布并且开源的英特尔OpenVINO工具包。
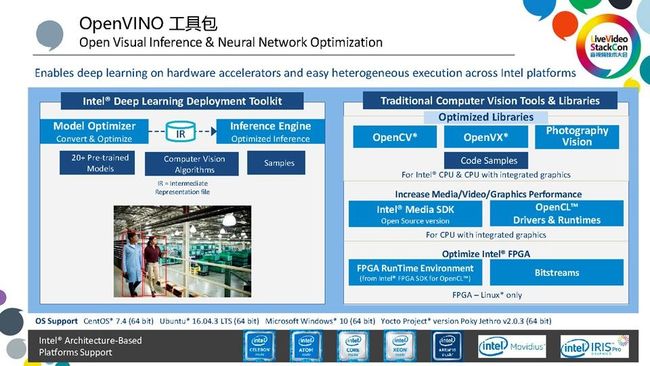
OpenVINO的全称是开放式的视觉推导和神经网络优化,它是一个一站式的工具包。OpenVINO除了包含传统的计算机视觉工具,如OpenCV、 OpenVX,以及传统视频编解码的处理优化,如Intel Media SDK,之外,还特别地加入了对Deep Learning的支持。我们推出了Deep Learning部署工具包,Deep Learning部署工具包主要分两部分:一个是Model Optimizer模型优化器,另一个就是Inference Engine推导引擎。
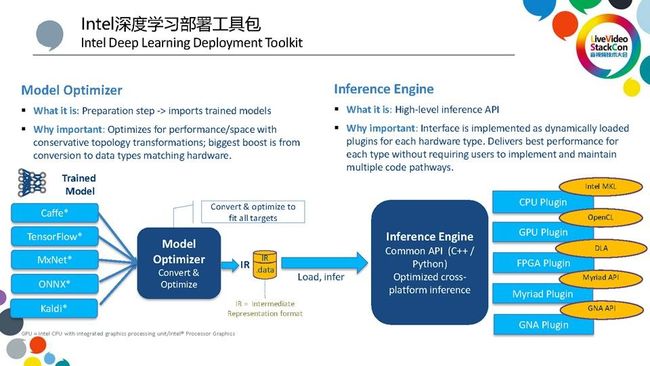
首先,模型优化器会将第三方框架训练出来的模型转化到一个中间表现形式,我们称这个中间表现形式为IR。然后,推导引擎会加载这个IR,并在相应的目标硬件上进行处理。由于硬件多种多样,包括CPU、GPU、FPGA和VPU等等,而推导引擎能够提供同一个接口把程序加载到对应的硬件上进行正确处理,它提供了对英特尔全平台硬件(异构硬件)的通用支持。也就是说,用户只需要写一份Code,就能够统一执行,在英特尔各个平台上完成优化。此外,为了方便用户开发,我们还提供了很多预训练的模型和算法来帮助大家快速上手,包括一些比较通用的人脸检测识别、车牌和车型检测等等,目前大概有超过20个模型可以供大家进行选用。
下面,我再深入讲一下英特尔的深度学习部署工具包是如何工作的。
第一,Model Optimizer模型优化器,目前可以支持Caffe、TensorFlow 、MxNet等比较流行的第三方框架,它能够将从第三方框架训练出来的模型导入并转化为到一个中间表示形式。同时,它还支持ONNX开放式的标准,最近还加入了Kaldi框架模型,从而将OpenVINO从视觉计算拓展到了语音计算,可以进行语音识别。此外,由于从第三方训练出来的网络不一定是最简网络,我们在导入的过程中它会对网络进行一些优化,包括对冗余层的去除和节点的合并。举例说明,我们在训练的时会加入一个Dropout层, Dropout层可以使得局部的神经元失效,从而避免模型参数陷入到一个局部最小值,达不到最优的效果。但是, Dropout层在推导的过程中是不需要的,因此,Model Optimizer能够智能将类似的不需要的层次自动删除,同时也会对一些可以合并的层进行合并。除了以上这些通用网络优化,Model Optimizer还会针对特定硬件进行模型优化。比如说针对某个特定的VPU或集成显卡,它会把网络模型里面的具体数据类型转化到能够跟相应的硬件进行适配,从而带来最大的硬件优化。与此同时,它还支持可定制化。我们在写TensorFlow网络的时候,可以加入一些用户自己定义的网络层,那么如何将自定义的网络层加载到OpenVINO呢?我们只需要把它注册到Model Optimizer里面,Model Optimizer会识别这些网络层并进行相应的转换和优化。
第二,Inference Engine推导引擎,它提供了统一的编程接口,这个编程接口可以是针对C++或Python的。然后,用户只需要写一套推导程序,就可以在跨英特尔几乎所有的适合于深度学习计算的平台上进行统一的处理。当然,在后台肯定是会需要做一些工作的,所以我们为不同的硬件类型CPU、GPU、FPGA、Myriad均开发了独有的插件,这个插件也是特别针对平台进行相应的优化。同时,英特尔还开发了GNA Plugin,一个针对超低功耗的语音识别的芯片,可以用来集成到嵌入式的环境里面做语音分析。总之,所有的插件都是对相应的硬件进行优化的。

总结下来,OpenVINO工具包充分集成了深度学习,然后极大的提高了性能,并且加快了开发速度,同时还支持创新和可定制化。从集成深度学习和加快性能这方面来举一个案例,曾经在美国某公司,他在他的后台数据中心集群上,开发了一套图像分类神经网络,它是从TensorFlow框架训练出来的网络模型。一开始,用集群进行CPU推导时,它的性能达不到要求,该公司原本计划采购一些离散显卡来进行加速。后来在英特尔的帮助下,他们采用了OpenVINO工具包进行优化,最终在CPU集群上达到了10倍以上的优化速率。所以,只要能够找到相应合适的工具包做足相关的优化,CPU用来做推导是完全可以信任的,不一定需要花额外的经费再去购买一些离散显卡。
下面,我再介绍一个OpenVINO工具包里的传统视觉计算工具Intel media SDK。

在Server平台上,我们一般称之为Intel Media Server Studio。它在英特尔平台上提供了一整套的视频编解码加速的接口,它支持广泛的媒体Codec,包括H.265、H.264、VP9、MPEG-2等等。此外,对于图像处理,它支持图像的缩放、转换、合成以及降噪等等,整个媒体处理的功能是非常全面的。

Intel Media Server Studio在英特尔集成显卡的加速下,它能达到一个比较好的性能。在单核的英特尔E3-1500 v5的 CPU处理器上,它能达到四路4K的AVC的转码速度,也可以达到两路4K的HEVC的转码速度。
三、Intel CS for WebRTC实时视频流分析系统实践
在这一部分,我会结合现在项目组正在开发的一个项目,来跟大家介绍我们是如何构建实时的视频流分析系统的。
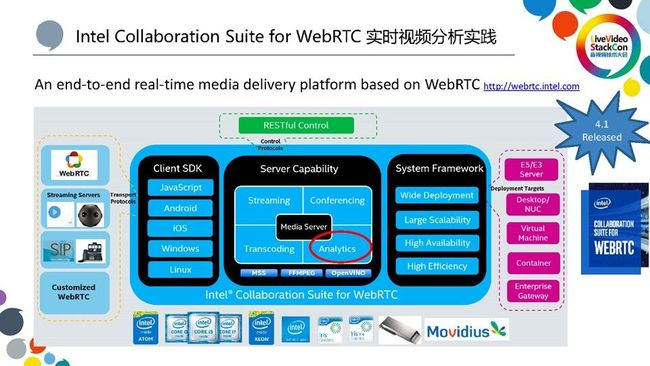
我们将这个Intel Collaboration Suite for WebRTC简称为ICS,它是一个基于WebRTC的协同通讯解决方案,主要功能包括Streaming、Conferencing、Transcoding以及最近发布支持的视频分析Analytics功能。整个系统是基于微服务架构来实现的,它支持广泛的分布式部署,整个系统的模块包括接入、媒体处理、录制、转码和分析都是以微服务的形式存在的。它支持部署在广泛的英特尔平台上,支持高并发和高可用,对英特尔整个平台也进行了丰富的优化。另外,它有丰富的Client SDK来与跟Server端进行配合,从而充分的适应因特网,帮助大家可以把自己的应用程序集成到Server端。举例说明,我们把一个视频会议的功能集成到一个远程教育的场景中去,除了对WebRTC支持之外,支持是非常广泛的,支持一些传统的Streaming Server,也支持一些IP摄像头接入到会议里面,还有也支持接入传统的SIP终端和一些定制化的WebRTC设备。我们的系统大概是从2014年开始发布第一个版本,在最新的 4.1版本中,我们加入了实时视频分析功能。
如图中所示,我们的产品在视频会议、医疗、远程教育、自动驾驶、互动直播、社交媒体等等各个方面得到了广泛的应用。
那么,我们为什么在最近的这个版本里加入实时视频分析的功能呢?这个源自于客户的一些需求。做远程教育的客户希望能减少一些人工的工作,比如,在做远程课堂时会需要一些助教和后台的导播,他们希望能够加入一些智能助教和智能导播的功能。智能助教可以在远程课堂实现智能点名,智能导播可以自动识别嘉宾,并在屏幕下方自动加上他们的人物介绍。在得到了类似的需求之后,我们在两个多月的时间里面,利用英特尔计算平台快速开发了一套实时视频流分析的系统来满足客户的需求。
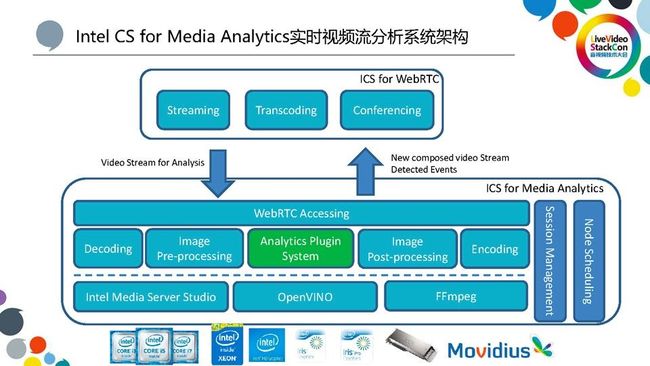
这个视频流分析系统的架构与上面讲的ICS是分离的系统。这个独立系统的流程如下:首先,构建一条媒体处理的pipeline,包括接入、解码、前处理、后处理等等,它的接入是从ICS媒体服务器上拉流,然后进入pipeline进行处理。我们的框架与传统的媒体视频分析的pipeline相比,进一步帮助用户隐藏了接入、接出、前处理、后处理,用户在这个系统上只需要开发自己的分析Plugin系统即可。一般每个公司基本上都会有自己的深度学习算法,包括人脸检测与识别等等,这些自研的、比较适合他的应用的算法可以通过写Plugin来把算法集成进去,这些算法模型的执行逻辑可以基于OpenVINO来写。而分析系统会根据Plugin配置,自动生成完整的pipeline。这样一来,用户可以以最小的时间代价来实现自己的应用。此外,我们系统考虑到分布式的高并发访问需求,也是采用的微服务的架构,并且集成了智能的节点调度,也能支持容错。
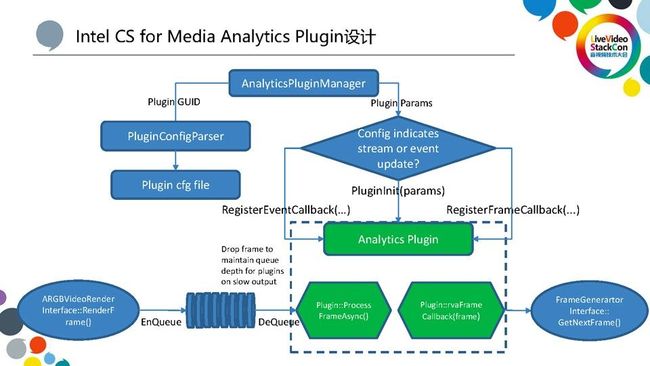
上图是一个分析系统Plugin设计,用户只需要把自己的Plugin写一些配置文件,并且实现我们提供的相应接口。根据配置文件,系统会自动加载Plugin,并把Plugin提供的接口函数实现注册到Framework里。最后,根据它的配置,Plugin分析产生的事件和视频帧进行相应的处理以后就可以送入到后处理系统里,再送回ICS媒体处理系统。
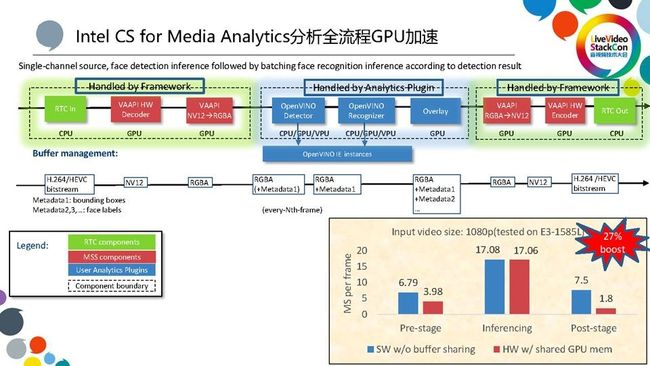
关于加速部分,因为我们框架的前处理和后处理,都是框架的自动完成的,用户不需要去考虑怎么写前处理、后处理以及怎么对它进行优化。框架的前处理和后处理都会自动检测底层硬件,不同的硬件也会采用不同的执行方法。如果有集成显卡,则会充分利用硬件加速,经过GPU加速优化过的pipeline,在inference推导的这个时间类似的情况之下,前处理和后处理时间可以大大缩短,整个pipeline能够提高27%的fps的吞吐率,可以大大的提高的用户的体验。
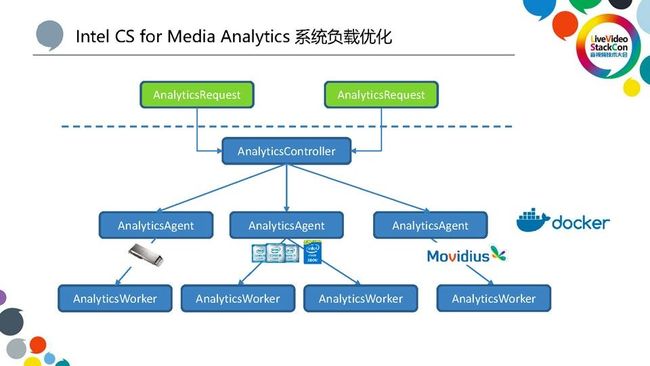
这部分是专门为整个系统负载进行的优化。为了能够支持大容量的并发,基于微服务的架构,我们有一个AnalyticsController来对外提供微服务。同时会有智能的调度系统,我们的AnalyticsAgent是可以分布式的部署到不同的节点上与不同的英特尔硬件进行配合,有的是插的加速卡,比如有的是直接用CPU来算、有的是用VPU进行加速,系统会根据相应运行节点的负载来进行相应的调度。然后,如果最终用到的每个节点上的Worker出现了一些故障,它会智能的报告给AnalyticsController来通知客户去做相应的处理。我们的系统既可以是说独立部署成一个分布式的系统,也可以是说以微服务的单个节点形式挂接到更加高层的一个分布式的调度系统里。整个系统为了适应当前比较流行的计算环境,我们也做了比较好的Docker支持,用户只需要在相应的硬件平台上做比较小的改动,就可以在Docker上进行部署,充分利用到底层硬件的加速能力。
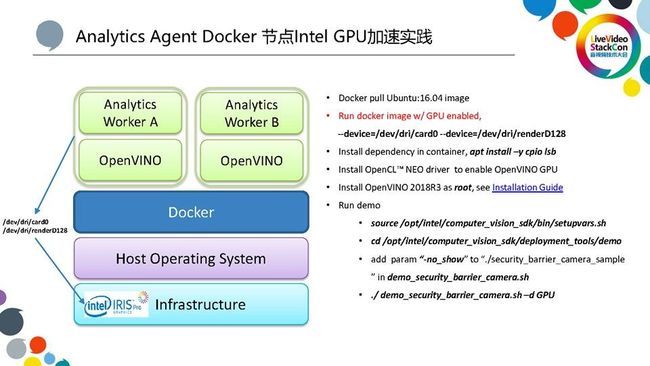
关于具体加速方法,大家可以参见PPT或者ICS的产品说明文档。
最后,在我们第一版发布的过程中,我们提供了这样一个示例来让用户进行试用。

这个是典型的智能课堂里面的一个场景,其中也利用了英特尔OpenVINO里面提供的预训练的模型,来进行人脸检测和人脸识别。

这个场景与一般的人脸识别是不太一样的。一般的人脸识别基本上是一个图片里只有几张脸,可以直接基于原图进行处理,但是在课堂里面,由于人比较多,人的图像相对比较小,所以需要进行相应的处理。由于直接进行缩放送进人脸检测的网络,人脸的精度是达不到要求,我们处理的方法是将画面先进行分割,然后把每个分割的图像都送进人脸检测的网络。但是,分割也存在人脸被分割线分成好几半的问题,所以在分析完每一个分片之后要对边缘进行处理,我们要保证让边缘图片能够进行识别。此外,还要保证不会有多数和漏数,因此人脸检测好了之后,可以把分割好的人脸再进一步送入到OpenVINO中预先训练好的人脸识别网络里,再对每个人脸进行识别。最后,在原图上进行标注。
四、总结

总结一下,英特尔会持续的在软件的和硬件两个层面对视觉计算、深度学习做更多的工作,推出更多的硬件、软件和工具来帮助大家加速开发的过程,达到一个最好的用户体验。与此同时,英特尔也是非常重视软件开源来推动技术发展,正在内部推动建立专门的开源社区,将所有视觉计算相关的软件、函数库、编解码Codec、上层的工具包都进行开源,和开源社区一起来推动基于深度学习视觉计算的进步。

点击【阅读原文】或扫描图中二维码了解更多LiveVideoStackCon 2019 上海 音视频技术大会 讲师信息。