论文分享 3D RoI-aware U-Net for Accurate and Efficient Colorectal Tumor Segmentation
3D RoI-aware U-Net for Accurate and Efficient Colorectal Tumor Segmentation
https://github.com/huangyjhust/3D-RU-Net
摘要
从三维磁共振(MR)图像中分割结直肠癌区域是放射治疗的一个关键步骤,传统的放射治疗方法要求精确地描绘肿瘤边界,但要耗费大量的人力、时间和可重复性。虽然基于深度学习的方法在三维图像分割任务中提供了良好的基线,但小的适用切片尺寸限制了有效的感受域,降低了分割性能。此外,大体积三维图像的感兴趣区域(RoIs)定位作为一种先行操作,在速度、目标完整性、减少误报等方面带来了多重好处。与基于滑动窗口或非联合定位分割的模型不同,我们提出了一种新的多任务框架3D-RoI-aware U-Net(3D-RU-Net),用于RoI定位和区域内分割,两个任务共享一个骨干编码器网络。利用编码器得到的RoI,在编码器的区域特征中裁剪出多个层级的RoI,形成一个GPU存储效率高的解码器进行细节保护的分割,从而扩大了适用体积尺寸和有效的感受域。 为了有效地训练该模型,我们为全局到局部的多任务学习过程设计了一个Dice形式的损失函数。基于所提出的方法所证明的效率增益,我们继续集成具有不同接收场的模型,以获得更高的性能,只需花费少量额外的计算费用。随后对64例癌症患者进行了广泛的实验,并进行了四次交叉验证,结果显示在准确性和效率方面明显优于传统的先进框架。综上所述,该方法由于其固有的可推广性,在医学图像三维目标分割中具有巨大的推广潜力。建议方法的代码是公开的。
贡献
- 提出了一种三维联合定位分割框架,包含共享的基于感兴趣区域进行全局理解的Global Image Encoder,和利用设计的区域特征金字塔进行RoI分割的Local Region Decoder。与竞争对手相比,该设计能够充分利用大感受域,实现快速且高效的保留细节的整个体积的分割。
- 考虑到类的自动重新平衡和更好的边界识别,我们提出了一种基于Dice的全局到局部多任务混合损失(MHL)函数,以进一步提高精度。此外,加速框架鼓励我们采用多感受域模型集成策略来抑制误报,并以可接受的速度为代价细化边界细节。
- 对采集到的数据集进行了大量的实验,证明了我们提出的框架的有效性。此外,我们的方法本质上是通用的,可以应用于其他类似的应用。
网络结构

3D RU-Net构建
We input whole image volumes to Global Image Encoder for multi-level feature encoding, employ an
encoder-only RoI locator for RoI localization, crop in-region feature tensors from multi-scale feature maps using RoI Pyramid Layer, and design a Local Region Decoder sub-network to perform multi-level feature fusion for high-resolution cancerous tissue segmentation.
1. Global Image Encoder
与构建一个完整的3D版的编码器-解码器架构(如3D FPN)或直接将流行的主干网[49–51]扩展到3D不同,一个名为全局图像编码器(Global Image encoder)的仅编码的紧凑型网络被构建来处理整个图像,而不是像通常的做法那样处理上下文受限的小部分图像。
具体地说,编码器使用ResBlocks[50]和MaxPooling层的堆栈来编码整个卷图像。每个Residual Block具有三个卷积层、三个Instance Normalization Layers[52]、三个ReLU层和一个Skip Connection,以获得更好的梯度流动。在三维分割任务中,如果batchsize=1,则使用Instance Normalization Layers来提高鲁棒性。
2. RoI Locator
RoI定位器是一个模板,可以是任何只包含编码器的进行目标检测的主干网络。由于大量训练样本的长宽比差异,学习精确的边界框回归是很困难的。对于这个特定的三维语义分割任务,我们建议充分利用可用的体素级掩模,如下所述,以实现简单和更稳健的边界框预测。
具体来说,我们避免将体素级标签降级为对象级标签来学习锚点拟合。该定位器以特征映射 F I I I F_{III} FIII为输入,由核大小为1的卷积层和Sigmoid激活函数组成。该模块用于从全局图像中预测下采样的分割掩模。为了解决极不平衡的前景与背景比率问题,定位器不是部分采样,即对前景与背景以固定比例采样或使用OHEM[53],而是针对Dice loss进行训练,这将在第2.2小节中介绍。然后,我们执行一个快速的3D连接性分析来计算所需的边界框,公式为 B b o x I I I = ( z 3 , y 3 , x 3 , d 3 , h 3 , w 3 ) Bbox^{III}=(z^3,y^3,x^3,d^3,h^3,w^3) BboxIII=(z3,y3,x3,d3,h3,w3),其中 ( z 3 , y 3 , x 3 ) (z^3,y^3,x^3) (z3,y3,x3)表示起始坐标, ( d 3 , h 3 , w 3 ) (d^3,h^3,w^3) (d3,h3,w3)表示 B b o x I I I Bbox^{III} BboxIII在特征地图 F I I I F_{III} FIII中的深度、高度和宽度。
3. RoI Pyramid Layer
为了提取检测目标的RoI区域张量金字塔,我们首先从一个给定的边界框 B b o x I I I = ( z 3 , y 3 , x 3 , d 3 , h 3 , w 3 ) Bbox^{III}=(z^3,y^3,x^3,d^3,h^3,w^3) BboxIII=(z3,y3,x3,d3,h3,w3)构造一个边界框金字塔 ( B b o x I , B b o x I I , B b o x I I I ) (Bbox^I,Bbox^{II},Bbox^{III}) (BboxI,BboxII,BboxIII)。具体地,边界框金字塔由如下边界框缩放准则迭代计算: B b o x i − 1 = ( z i × s z i , y i × s y i , x i × s x i , d i × s z i , h i × s y i , w i × s x i ) Bbox^{i-1}=(z^i×s^i_z,y^i×s^i_y,x^i×s^i_x,d^i×s^i_z,h^i×s^i_y,w^i×s^i_x) Bboxi−1=(zi×szi,yi×syi,xi×sxi,di×szi,hi×syi,wi×sxi)(其中 s z i , s y i , s x i s^i_z,s^i_y,s^i_x szi,syi,sxi)表示 M a x P o o l i n g i MaxPooling^i MaxPoolingi的stride参数。在给定边界框金字塔 ( B b o x I , B b o x I I , B b o x I I I ) (Bbox^I,Bbox^{II},Bbox^{III}) (BboxI,BboxII,BboxIII)的情况下,我们从整个图像的特征图 F I , F I I , F I I I F_{I},F_{II},F_{III} FI,FII,FIII中裁剪出原始的RoI张量金字塔 ( f I , f I I , f I I I ) (f^I,f^{II},f^{III}) (fI,fII,fIII),without applying any bin-fitting operation,并为后面的Local Region Decoder分支形成RoI张量金字塔。
4. Local Region Decoder
在给定RoI区域张量金字塔的基础上,利用成功的多级特征融合机制,构造了一个区域内分割子网络,称为Local Region Decoder。解码器的结构与具有跳跃连接的编码器部分大致对称,以融合相应尺度的特征映射,而有益的区别在于解码器分支的特征张量的大小要小得多。由于RoI区域张量金字塔不包含形状失真或尺度归一化,因此该模块可以在不丢失细节的情况下恢复RoI区域的空间维度。如果定位了多个RoI,则使用同一组解码器权重迭代处理不同的RoI。
损失函数
Dice-based Multi-task Hybrid Loss Function
在多任务学习实践中,每一个任务都面临着不同的挑战。在我们的例子中,全局图像编码器主要存在类不平衡的问题,而局部区域解码器则必须关注目标区域的精确边界。因此,我们提出了一个基于Dice的多任务loss(MHL)函数来有效地学习这些任务。
1. Dice Loss

where the sums are computed over the N voxels of the predicted volume p i ∈ P p_i∈ P pi∈P and the ground truth volume g i ∈ G g_i∈ G gi∈G, ϵ \epsilon ϵ is a minimal smoothness term that avoids division by 0 and is set as 1 0 − 4 10^{−4} 10−4.
2. Dice Loss for Global Localization
为了解决全局图像RoI定位任务的类不平衡问题,我们采用了上述的Dice Loss:
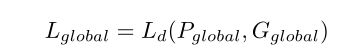
where P g l o b a l P_{global} Pglobal and G g l o b a l G_{global} Gglobal denotes predictions of the localization top and down-sampled annotations.
3. Dice-based Contour-aware Loss for Local Segmentation
与定位任务相比,区域内分割分支需要多个约束才能获得更好的边界敏感分割结果。在语义分割实践中,模糊边界是最难学习的,但却没有引起足够的重视。借鉴前面[43]增加辅助轮廓感知任务的探索,我们进一步利用Dice Loss来构造辅助任务,以帮助解决三维空间中轮廓标签的极端稀疏性。实际操作中,我们在分割分支的输出端增加一个由Sigmoid函数激活的1×1×1卷积层来预测轮廓体素,并与区域分割任务并行训练。考虑到辅助任务,分割分支 L l o c a l L_{local} Llocal的损失函数通过汇总加权损失表示如下:

where λ c = 0.5 λc= 0.5 λc=0.5, denoting the auxiliary task weight to ensure that the region segmentation task dominates while other tasks take effects.
最后,总体损失函数为:

where β = 1 0 − 4 β = 10^{−4} β=10−4 denotes the balance of weight decay term and W denotes the parameters of the whole network.
Multiple Receptive Field Model Ensemble
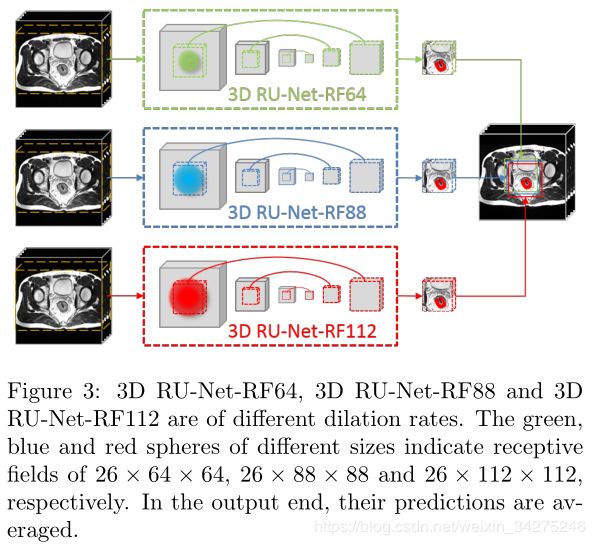
由于单个模型的精度有限,多模型集成被认为是一种有效的鲁棒推理方法,在实际应用中得到了广泛的应用,但代价是计算量大。在这种显著加速的框架下,本文提出采用多感受域模型集成策略,融合结构相同但感受域设置不同的模型。这是对文献[48]中提出的多分辨率策略的一种推广,该策略将相同的感受域应用于具有不同空间分辨率的图像,实际上是形成不同的空间感受域。这样的推广消除了细节丢失采样,使每个模型对边界细节的贡献相等。具体来说,如表1所示,我们首先构造了一个感受域26×64×64的原始3D RU-Net,命名为3D RU-Net-RF64。接下来,我们将ResBlock3的dilation rate调整为2,将感受野扩展为26×88×88,并建立了3D RU-Net-RF88;进一步将ResBlock2、ResBlock3和ResBlock4的dilation rate调整为2,构建了一个26×112×112的3D RU-Net,命名为3D RU-Net-RF112。在推理阶段,如图3所示,对三个网络的输出进行平均以生成最终预测。主要投票产生相似的分数,因此不讨论。