基于Netty的四层和七层代理性能方面的一些压力测试
本文我们主要是想测试和研究几点:
基于Netty写的最简单的转发HTTP请求的程序,四层和七层性能的差异
三种代理线程模型性能的差异,下文会详细解释三种线程模型
池和非池化ByteBuffer性能的差异
本文测试使用的代码在:github.com/JosephZhu1983/
在代码里我们实现了两套代理程序:
测试使用的机器配置是(阿里云ECS):

一共三台机器:
server 服务器安装了nginx,作为后端
client 服务器安装了wrk,作为压测客户端
proxy 服务器安装了我们的测试代码(代理)
Nginx后端
nginx 配置的就是默认的测试页(删了点内容,减少内网带宽):
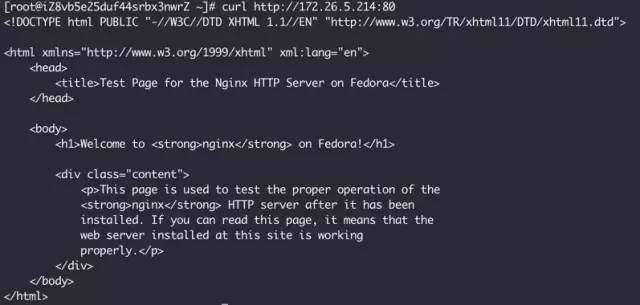
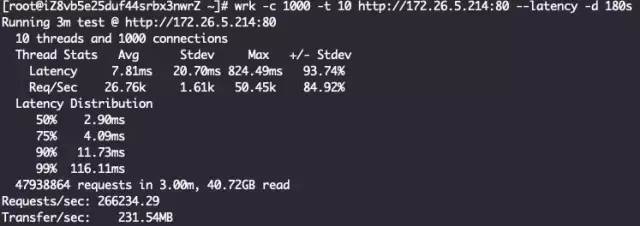
直接对着nginx压测下来的qps是26.6万:
有关四层和七层
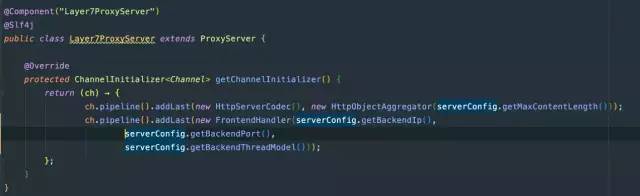
四层的代理,我们仅仅是使用Netty来转发ByteBuf。 七层的代理,会有更多额外的开销,主要是Http请求的编码解码以及Http请求的聚合,服务端:
客户端:

这里我们可以想到,四层代理因为少了Http数据的编解码过程,性能肯定比七层好很多,好多少我们可以看看测试结果。
有关线程模型
我们知道作为一个代理,我们需要开启服务端从上游来获取请求,然后再作为客户端把请求转发到下游,从下游获取到响应后,返回给上游。我们的服务端和客户端都需要Worker线程来处理IO请求,有三种做法;
A:客户端Bootstrap和服务端ServerBootstrap独立的线程池NioEventLoopGroup,简称IndividualGroup
B:客户端和服务端共享一套线程池,简称ReuseServerGroup
C:客户端直接复用服务端线程EventLoop,简称ReuseServerThread
以七层代理的代码为例:

接下去的测试我们会来测试这三种线程模型,这里想当然的猜测是方案A的性能是最好的,因为独立了线程池不相互影响,我们接下去看看结果
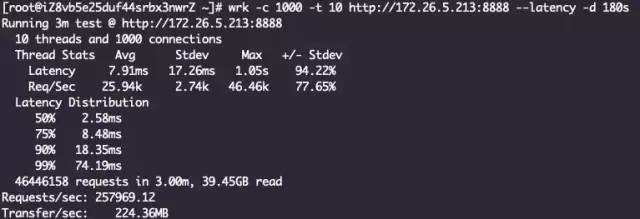
四层代理 + ReuseServerThread线程模型
Layer4ProxyServer Started with config: ServerConfig(type=Layer4ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
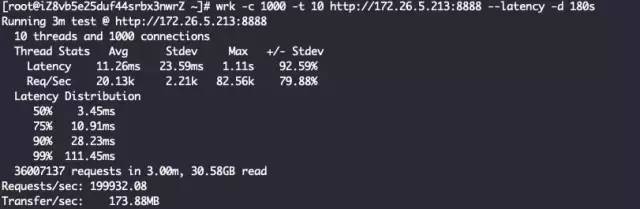
四层代理 + IndividualGroup线程模型
Layer4ProxyServer Started with config: ServerConfig(type=Layer4ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=IndividualGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
四层代理 + ReuseServerGroup线程模型
Layer4ProxyServer Started with config: ServerConfig(type=Layer4ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)

看到这里其实已经有结果了,ReuseServerThread性能是最好的,其次是ReuseServerGroup,最差是IndividualGroup,和我们猜的不一致。
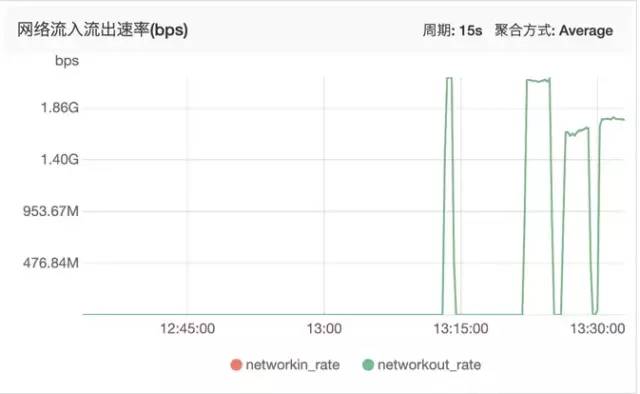
四层系统监控图
从网络带宽上可以看到,先测试的ReuseServerThread跑到了最大的带宽(后面三个高峰分别代表了三次测试):
 从CPU监控上可以看到,性能最好的ReuseServerThread使用了最少的CPU资源(后面三个高峰分别代表了三次测试):
从CPU监控上可以看到,性能最好的ReuseServerThread使用了最少的CPU资源(后面三个高峰分别代表了三次测试):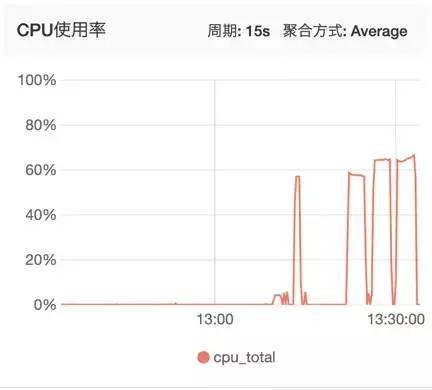
七层代理 + ReuseServerThread线程模型
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
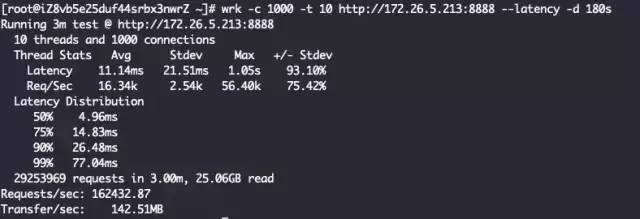
七层代理 + IndividualGroup线程模型
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=IndividualGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
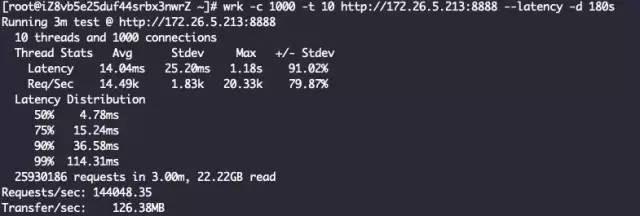
七层代理 + ReuseServerGroup线程模型
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
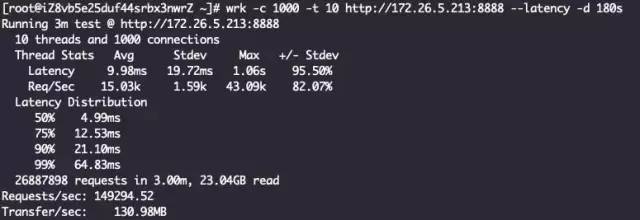
结论一样,ReuseServerThread性能是最好的,其次是ReuseServerGroup,最差是IndividualGroup。我觉得是这么一个道理:
复用IO线程的话,上下文切换会比较少,性能是最好的,后来我也通过pidstat观察验证了这个结论,但是当时忘记截图
复用线程池,客户端有机会能复用到服务端线程,避免部分上下文切换,性能中等
独立线程池,大量上下文切换(观察下来是复用IO线程的4x),性能最差
七层系统监控图
下面分别是网络带宽和CPU监控图:
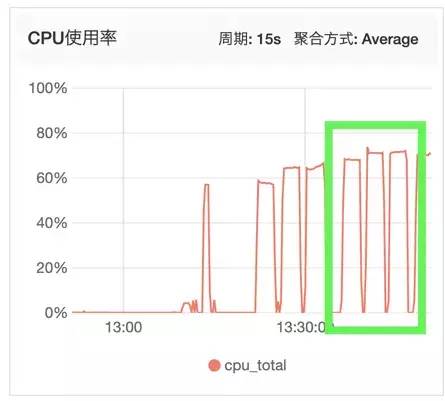
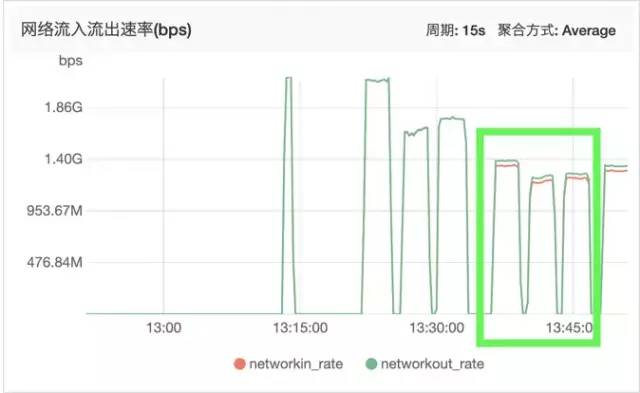
可以看到明显七层代理消耗更多的资源,但是带宽相比四层少了一些(QPS少了很多)。 出流量比入流量多一点,应该是代码里多加的请求头导致:
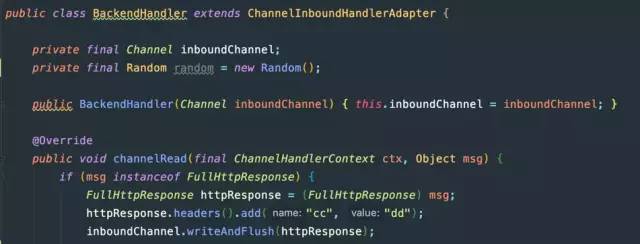
试试HttpObjectAggregator设置较大maxContentLength
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Pooled, maxContentLength=100000000)

试试PooledByteBufAllocator
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Pooled, maxContentLength=2000)
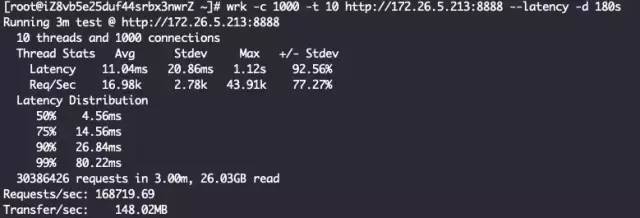
可以看到Netty 4.1中已经把默认的分配器设置为了PooledByteBufAllocator

总结
这里总结了一个表格,性能损失比例都以第一行直接压Nginx为参照:

结论是:
Nginx很牛,其实机器配置不算太好,在配置比较好的物理机服务器上跑的化,Nginx单机百万没问题
Netty很牛,毕竟是Java的服务端,四层转发仅损失3% QPS
不管是七层还是四层,复用线程的方式明显性能最好,占用CPU最少
因为上下文切换的原因,使用Netty开发网络代理应该复用IO线程
七层的消耗比四层大很多,即使是Netty也避免不了,这是HTTP协议的问题
PooledByteBufAllocator性能比UnpooledByteBufAllocator有一定提升(接近3%)
HttpObjectAggregator如果设置较大的最大内容长度,会略微影响点性能
之所以写这个文章做这个分析的原因是因为最近在做我们自研网关的性能优化和压力测试 github.com/spring-avengers/tesla 。 我发现有一些其它开源的基于Netty的代理项目并不是复用连接的,可能作者没有意识到这个问题,我看了下Zuul的代码,它也是复用的。