在人类的历史发展中,人们有沟通交流的需求,于是出现了语言和文字,之后又发明了造纸术和印刷术,使得人们的想法可以保存记录并传播开来。
在 iOS 开发中,文字处理可以说是最基础常见的一部分内容,系统控件例如 UILabel、UITextField、UITextView 等帮我们做了很多工作让我们可以很方便地展示一段文本。但是当我们要做更深入的定制展示时,系统提供的这些控件就无法满足需求了,这时候就要深入去了解一下系统是如何处理文本展示的。
以下内容是我在探究 iOS 系统对文字处理时做的一些记录,主要是一些概念性的内容,让大家对 iOS 文字处理有一个大概了解,涉及到具体需求时知道查找哪方便的资料,包括了 Unicode、UIFont、TextKit、CoreText、Unicode双向算法等。
Nsstring 和 Unicode
(一)历史
计算机没法直接处理文本,它只和数字打交道。为了在计算机里用数字表示文本,指定了一个从字符到数字的映射。这个映射就叫做编码(encoding)。最开始的映射是 ASCII 编码,但是能表示的字符有限,因此后来用 Unicode 统一编码。
(二)Unicode概要
Unicode 可以看做是对各编码系统的统一,但不通用,有一些很古老的编码系统无法兼容。
(三)Unicode特性
- Unicode 以抽象的方式代表一个字符,而不规定这个字符如何渲染(render)。
- 组合字符序列,有些字符可以由单一码点或由多个码点组成,虽然外观和意义相同,在 Unicode 语境下并不相等,但符合 canonically equivalent
(四)Unicode格式转换
UTF(Unicode Transformation Formats)
(五)NSString
关于 NSString,最需要记住的是:NSString 代表的是用 UTF-16 编码的文本,长度、索引和范围都基于 UTF-16 的码元。对于这一点要是不注意会有以下一些陷阱:
- 长度
我们经常用 NSString 的 length 方法来获取一个字符串的长度,在大多数情况下这个方法都没有问题,但是当一个字符串中包含 emoji 时,这个返回的长度值并不准确,以下是具体例子:
NSString *s = @"\U0001F30D"; // earth globe emoji
NSLog(@"The length of %@ is %lu", s, [s length]);
// => The length of is 2
以下代码可以获取实际的长度
NSUInteger realLength =
[s lengthOfBytesUsingEncoding:NSUTF32StringEncoding] / 4;
NSLog(@"The real length of %@ is %lu", s, realLength);
// => The real length of is 1
- 随机访问
用 characterAtIndex: 方法以索引方式直接访问 unichar 会有同样的问题。可以用 rangeOfComposedCharacterSequenceAtIndex: 来确定特定位置的 unichar 是不是代表单个字符(可能由多个码点组成)的码元序列的一部分。每当给另一个方法传入一个内容未知的字符串的范围作参数时都应该这样做,确保 Unicode 字符不会被从中间分开。
- 遍历
使用 rangeOfComposedCharacterSequenceAtIndex: 的时候,可以写一个代码套路来正确地循环字符串里所有的字符,但每次要遍历一个字符串时都得这样做太不方便了。幸运的是,NSString 有更好地方式:enumerateSubstringsInRange:options:usingBlock: 方法。这个方法把 Unicode 抽象的地方隐藏了,能让你轻松地循环字符串里的组合字符串、单词、行、句子或段落。你甚至可以加上 NSStringEnumerationLocalized 这个选项,这样可以在确定词语间和句子间的边界时把用户所在的区域考虑进去。要遍历单个字符,把参数指定为 NSStringEnumerationByComposedCharacterSequences:
NSString *s = @"The weather on \U0001F30D is \U0001F31E today.";
// The weather on is today.
NSRange fullRange = NSMakeRange(0, [s length]);
[s enumerateSubstringsInRange:fullRange
options:NSStringEnumerationByComposedCharacterSequences
usingBlock:^(NSString *substring, NSRange substringRange, NSRange enclosingRange, BOOL *stop)
{
NSLog(@"%@ %@", substring, NSStringFromRange(substringRange));
}];
- 比较
有些字符可以由单一码点或由多个码点组成,虽然外观和意义相同,在 Unicode 语境下并不相等。isEqual: 和 isEqualToString: 这两个方法都是一个字节一个字节地比较的。如果希望字符串的合成和分解的形式相吻合,得先自己正规化:
NSString *s = @"\u00E9"; // é
NSString *t = @"e\u0301"; // e + ´
BOOL isEqual = [s isEqualToString:t];
NSLog(@"%@ is %@ to %@", s, isEqual ? @"equal" : @"not equal", t);
// => é is not equal to é
// Normalizing to form C
NSString *sNorm = [s precomposedStringWithCanonicalMapping];
NSString *tNorm = [t precomposedStringWithCanonicalMapping];
BOOL isEqualNorm = [sNorm isEqualToString:tNorm];
NSLog(@"%@ is %@ to %@", sNorm, isEqualNorm ? @"equal" : @"not equal", tNorm);
// => é is equal to é
NSString *s = @"ff"; // ff
NSString *t = @"\uFB00"; // ff ligature
NSComparisonResult result = [s localizedCompare:t];
NSLog(@"%@ is %@ to %@", s, result == NSOrderedSame ? @"equal" : @"not equal", t);
// => ff is equal to ff
上面这些内容可以点击这里了解更多。
TextKit
下图列出了 iOS 系统下和文字处理相关的组件,其中 TextKit 是从 iOS7 开始引入的,旨在帮助开发者实现更多的文本定制。
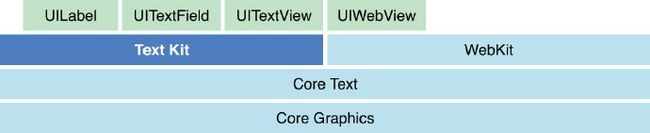
Text Kit is a set of classes and protocols that provide high-quality typographical services which enable apps to store, lay out, and display text with all the characteristics of fine typesetting, such as kerning, ligatures, line breaking, and justification.
以上引用了一段官网对 Text Kit 的介绍,翻译过来就是:
Text Kit 是一系列类和协议,这些类和协议提供了高性能的排版服务,这个服务可以让应用以很好的排版形式存储、布局和展示所有的字符,比如字间距、连笔、断行、两端对齐。
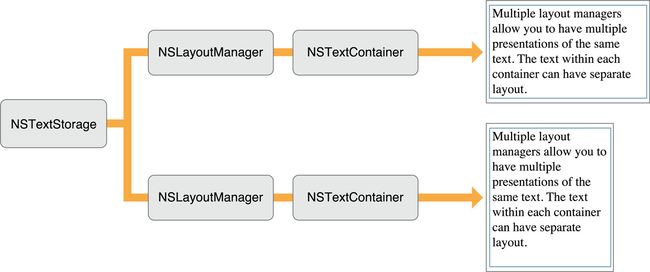
Text Kit 中有几个关键的组件,如下图所示,
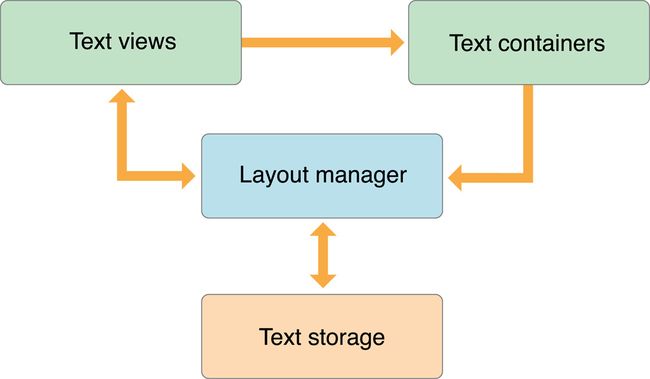
layoutManager 将 textStorage 存储的内容根据 textContainers 定义的区域布局到 textViews(UITextView)里。
在 MVC 中,textStorage 和 textContainers 相当于 M,textViews 相当于 V,leyoutManager 相当于 C。
An NSLayoutManager object orchestrates the operation of the other text handling objects. It intercedes in operations that convert the data in an NSTextStorage object to rendered text in a view’s display area. It maps Unicode character codes to glyphs and oversees the layout of the glyphs within the areas defined by NSTextContainer objects.
NSLayoutManager 将 Unicode 字符转换成 glyphs(字形),并在 NSTextContainer 定义的范围内布局这些字形。
The layout manager performs the following actions:
- Controls text storage and text container objects
- Generates glyphs from characters
- Computes glyph locations and stores the information
- Manages ranges of glyphs and characters
- Draws glyphs in text views when requested by the view
- Computes bounding box rectangles for lines of text
- Controls hyphenation
- Manipulates character attributes and glyph properties
layout manager 会做如下一系列操作:
- 控制 text storage 和 text container
- Unicode 字符转换成 glyphs(字形)
- 计算字形的位置信息并保存起来
- 管理字符的范围信息
- 将字形绘制到视图上
- 计算每一行的矩形包裹信息
- 处理断字
- 处理文字的属性,例如字体、颜色、下标
Text Kit handles three kinds of text attributes:
- character attributes, paragraph attributes, and document attributes.
- Character attributes include traits such as font, color, and subscript, which can be associated with an individual character or a range of characters.
- Paragraph attributes are traits such as indentation, tabs, and line spacing. Document attributes include documentwide traits such as paper size, margins, and view zoom percentage.
- Character attributes:字体、颜色、下标
- Paragraph attributes:缩进、制表符、行距
- Document attributes:页数、页间距、页缩放比例
下面列出了一些 Text Kit 的常见用法,

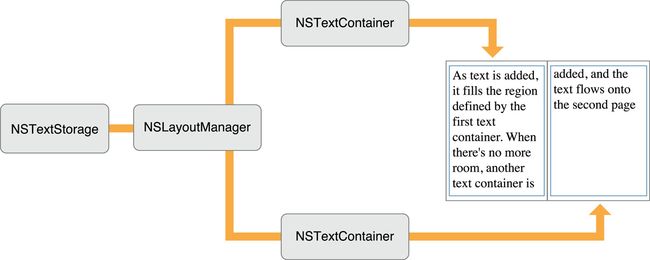
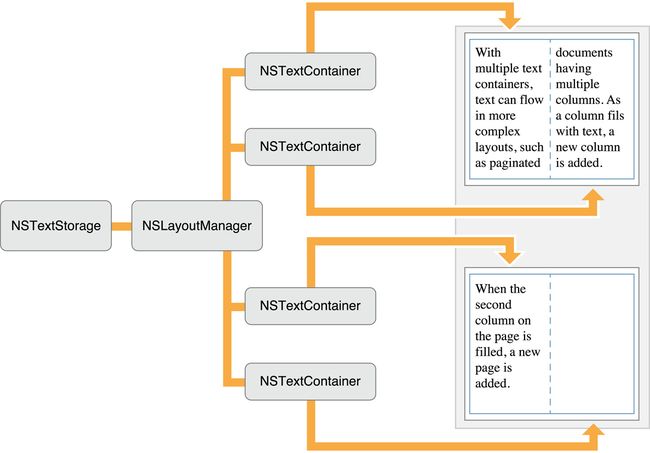
UIFont
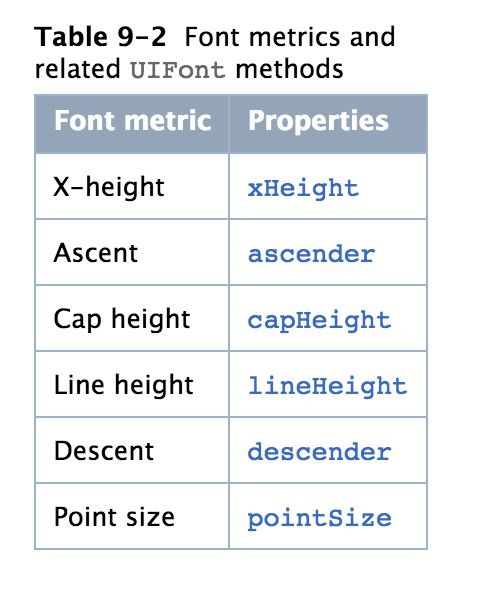
我们可以通过设置不同的字体来改变字符渲染到页面上的样式,UIFont 里有一些度量信息(metrics),如下图所示,

这些信息在 UIFont 里都能获取到,以下是它们的对应关系
UIFont 的 metrics 有一个具体应用,比如我们想让一个区域最多显示6行的文本,如果使用 UILabel,我们可以指定 numberOfLines 属性,在不使用 UILabel 的情况下,我们就可以用到 UIFont 的 lineHeight 属性了,用法如下:
+ (float)calculateContentHeight:(NSString *)content{
UIFont *font = [UIFont systemFontOfSize:13];
CGFloat lineHeight = font.lineHeight;
int height = 0;
float max_width = SCREEN_WIDTH-30;
float max_height = ceil(lineHeight)*6;
CGSize content_size = [content sizeWithFont:font constrainedToSize:CGSizeMake(max_width, MAXFLOAT) lineBreakMode:NSLineBreakByWordWrapping];
height = ceil(content_size.height);
if (content.length == 0) {
return 0;
}
height = MIN(max_height, height);
return height;
}
CoreText
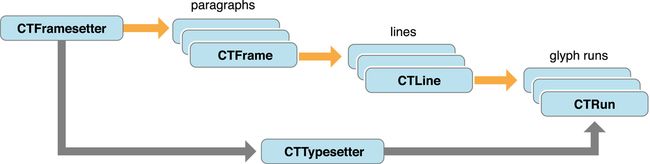
CTFramesetter生成CTFrame,每一个CTFrame代表一个段落。一个CTFrame可以只是一行很长的CTLine或者包含多个CTLine,一个CTLine代表一行文本。
Unicode双向算法
双向文字是指同时包含了两种书写方向的文字,也就是从左到右和从右到左的文字同时存在,默认根据第一个字符的 Unicode 属性定义全局方向。
书写方向与文字相关,与语言的关系不大。一种语言可能有多种文字,使用英语时从左到右书写,使用阿拉伯语时使用从右到左书写。

这些被加入文字中的 Unicode 控制字符在显示界面上是不可见的,也不占用任何显示空间。它们只是在默默地影响着双向文字的显示。
Unicode 控制字符又可以分为两类,
第一类为隐性双向控制字符:
- U+200E: LEFT-TO-RIGHT MARK (LRM)
- U+200F: RIGHT-TO-LEFT MARK (RLM
简单来说,您可以将这类的控制字符看成是不会显示出来的强字符,LRM 为从左到右的强字符,而 RLM 为从右到左的强字符。
而第二类当然就是显性双向控制字符:
- U+202A: LEFT-TO-RIGHT EMBEDDING (LRE)
- U+202B: RIGHT-TO-LEFT EMBEDDING (RLE)
- U+202D: LEFT-TO-RIGHT OVERRIDE (LRO)
- U+202E: RIGHT-TO-LEFT OVERRIDE (RLO)
- U+202C: POP DIRECTIONAL FORMATTING (PDF)
这类控制字符需要成对使用,列表中的前四个为开始字符,而最后一个为结束字符。当双向算法遇到 LRE 时,接下来文字片段内的方向开始变为从左到右。当双向算法遇到 RLE 时,接下来文字片段内的方向开始变为从右到左。当遇到 LRO 时,双向算法会将后面所有文字的双向属性视为从左到右强字符。当遇到 RLO 时,双向算法会将后面所有文字的双向属性视为从右到左强字符。如果一旦遇到 PDF 字符,双向属性的状态就会恢复到最后一个 LRE、RLE、LRO 或 RLO 之前的状态。
更多资料参考
http://www.ibm.com/developerworks/cn/web/1404_xiayin_bidihtml/
http://www.iamcal.com/understanding-bidirectional-text/
总结
以上总体描述了 iOS 系统处理文字时用到的知识点,每一部分都没有深入说明,只是让大家有个整体概念,在每一部分的后面都贴上了我在查找资料时觉得比较好的参考资料,可以再深入了解一下。
欢迎大家关注我们团队的公众号,不定期分享各类技术干货
