STL
文章目录
- 1.vetcor
- 2.list双向链表
- 3.deque双向队列
- 3.1.stack()堆
- 3.2.queue队列
- 4.红黑树RB-tree
- 4.1 set、multiset
- 4.2 map、multimap
- 5 hashtable
- hashtable(哈希表)
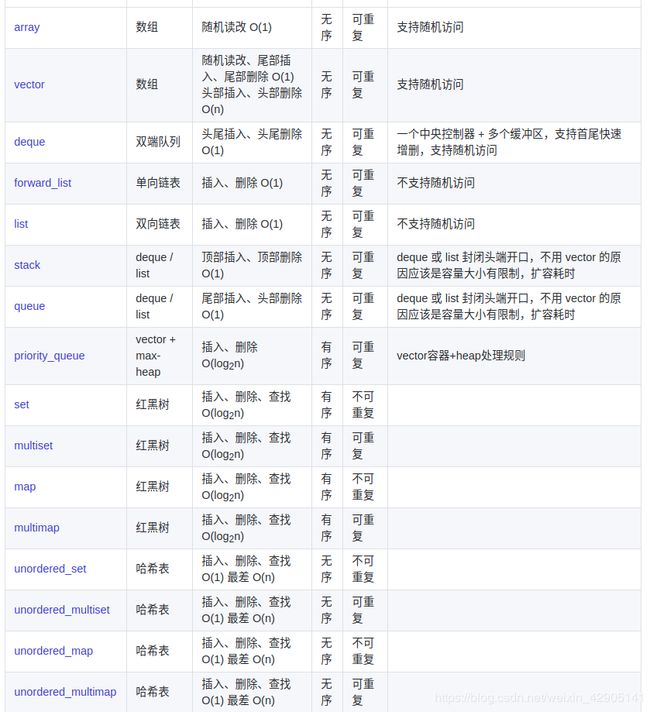
1.vetcor
vetcor维护连续线性空间
protected:
iterator start;
iterator finish;
iterator end_of_storage;
如果备用空间容量不足,容量会扩充至2倍
动态扩容是只分配原来大小两倍的新空间,然后将源数据拷贝到新空间,再将新空间构造新元素,最后释放元空间,指向原vector的所有迭代器指针失效。
2.list双向链表
底层数据结构为双向环形链表,支持快速增删。插入和删除一个元素,就配置一个或删除一个元素空间,插入和删除,常数时间。
链表进行排序,不能使用STL的sort函数,必须使用自己。
STL算法sort()函数只接受RamdonAccesslterator
3.deque双向队列
双向开口的数据结构,可以在两端进行插入和删除操作。deque表象连续,内部不连续,
中控器map提供多个缓冲区(节点),每个缓冲区有3个迭代器指针
first指向缓冲区的头
end 指向缓冲区的尾
cur 指向缓冲区所指的现行元素
map前端与尾端节点的备用空间不足,引发缓冲区重新配置
push_back()
push_front()
pop_back()
pop_front()
clear()//deque最初状态保留一个缓冲区
erase()
3.1.stack()堆
先进先出,以容器deque()为底层结构,封闭其头部端口形成一个stack,没有迭代器,也补允许遍历
pop()
push()
top()
empty()
size()
3.2.queue队列
先进先出的数据结构,底端加入,顶端删除,不允许遍历
以deque()或list()为底层结构,封闭底部出口,顶部的入口,形成queue
queue<Type>M 定义一个queue的变量
M.empty() 查看是否为空范例 是的话返回1,不是返回0;
M.push() 从已有元素后面增加元素
M.size() 输出现有元素的个数
M.front() 显示第一个元素
M.back() 显示最后一个元素
M.pop() 清除第一个元素
4.红黑树RB-tree
二叉搜索树
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结构的值
- 若它的右子树不空 ,则右子树上所有结点的值均大于它的根结点的值
- 它的左、右子树也分别为二叉排序树
通过中序遍历即可得出有序的序列, 构造一棵二叉搜索树的目的,其实并不是为了排序,而是为了提高查找和插入删除关键字的速度
红黑树是一颗二叉搜索树,它在每个节点增加了一个存储位记录节点的颜色,可以是红色和黑色
4.1 set、multiset
set/multiset以rb_tree为底层结构,具有自动排序特性,排序依据是key,set/multiset元素的value和key合一,value就是key
-
set不允许键值重复,插入操作采用的是底层RB-tree的insert_unique()
-
multiset允许键值重复,插入操作采用的是底层RB-tree的insert_equal()
begin()--返回指向第一个元素的迭代
end()--返回指向最后一个元素的迭代器
clear()--清除所有元素
size()--集合中元素的数目
max_size()--返回集合能容纳的元素的最大限值
empty()--如果集合为空,返回true
swap()--交换两个集合变量
insert()--在集合中插入元素
erase()--删除集合中的元素
find()--返回一个指向被查找到元素的迭代器
count()--返回某个值元素的个数
lower_bound()--返回指向大于(或等于)某值的第一个元素的迭代器
upper_bound()--返回指向小于(或等于)某值的第一个元素的迭代器
equal_range()--返回集合中与给定值相等的上下限的两个迭代器
4.2 map、multimap
map/multimap以rb_tree为底层结构,根据元素的键值key自动排序,所有的元素都是pair,都具有实值value和键值key。pair<键值,实值>
map
-
下标取值的算法是先查找是否有此key,没有就插入一个默认值作为该key的value
-
使用find函数对键进行查找,返回指向键的迭代器,若不存在,则返回map的尾端
数组和链表优缺点
- 数组:固定长度,减小内存浪费,方便遍历(通过下标存取),删除操作后面依次前移,插入操作依次后移
- 链表:动态分配存储,方便增减\插入\删除操作、遍历通过指针依次进行,堆分配空间
5 hashtable
STL源码剖析——hashtable
二叉搜索树具有对数平均时间,但这样的表现构造在一个假设上:输入数据有足够的随机性
hashtable(散列表)的数据结构,插入、删除、搜寻等操作具有常数平均时间
hashtable(哈希表)
基本原理是:使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数,也叫做散列函数),使每个元素的关键字都与一个函数值(即数组下标,hash值)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照关键字为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方,称为桶
了避免哈希表太大,需要用到某种映射函数,将大数映射为小数,这种函数称为散列函数hash function。但hash function会带来碰撞问题,即不同的元素被映射到相同位置。
线性探测:在哈希表的连续空间上,当发生冲突的时候,向后存储。
hashtable存取过程
hash_map,首先分配一大片内存,形成许多桶。是利用hash函数,对key进行映射到不同区域(桶)进行保存。其插入过程是:
- 得到key
- 通过hash函数得到hash值
- 得到桶号(一般都为hash值对桶数求模)
- 存放key和value在桶内。
hashtable 中桶子的大小一般设计为一个质数,至于为什么大家需要自行百度,这里我讲不明白。SGI STL 中先把 28 个质数准备好,以备随时访问,同时提供一个函数,用来查询在这 28 个质数之中,“最接近某数并大于某数” 的质数:
*当桶内的元素总个数大于桶子个数时,就会使桶子个数增长到其两倍附近的质数,所以桶子数一定比元素个数多。例子中为97,然后所有元素再执行H=hashcode%桶子数*
SGI STL中 hashtable容器的内部实现就是使用的【开链】方法。
其中键值序列,使用的是vector,而vector的大小,取的是一个质数集合,一共28个常数,大于53,且相邻质数的关系为:2的倍数中最接近的质数。
如果传入的键大小为50,那么hashtable建立的时候,就会取出__stl_prime_list的53,并建立vector。

- hashtable的迭代器没有后退操作,也没有逆向迭代器。
- 桶子维护的linked list(可单向可双向),并不是标准库中的list,而是自行维护hash table node
哈希函数构造主要有以下几种:
1:直接寻址法;
2:取模法;
3:数字分析法;
4:折叠法;
5:平方取中法;
6:除留余数法;
7:随机数法。
处理冲突主要方法有:
1:开地址法
- 线性探测再散列
- 二次探测再散列
- 伪随机再散列
2:链地址法
3:再散列法
4:建立一个公共溢出区