GCD源码解析
在我们开发过程中,我们使用到多线程的时候,最多的应该是使用GCD,因为它使用起来非常的简洁,简单。
平常中,我们使用最多的,
dispatch_queue_create,
dispatch_get_global_queue,
dispatch_sync,
dispatch_async,
dispatch_group_create,
dispatch_once等。可是,我们是否知道这些背后是做了什么事情,它和我们的内部线程到底是什么关系,或者,他们直接是否有直接的关系?我依次来做解答
dispatch_sync
dispatch_sync和dispatch_async是相对的,一个是同步任务,需要等待任务完成,一个异步不等待任务完成就返回。两种不同的方式,首先我们先介绍dispatch_sync.
dispatch_sync: 它一般情况下是不会重启一个新的线程,而是在当前线程执行,注意,这里说的是当前线程,而不是主线程。当然里面有特殊的存在get_main_queue,它是在主线程执行的。当我们调用dispatch_sync,也就是同步任务的时候,是分两种队列的,一种就是串行队列,一种是并发队列。在我们解析dispatch_sync源码的之前,我们先写几个例子,并且,把调用栈给写出来,这样更加有利于我们分析源码。
// 串行队列同步执行
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_SERIAL);//创建的是串行队列
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
});
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
// 下面是运行结果
myDemo[41725:1739115] current thread = {number = 1, name = main}
myDemo[41725:1739115] 111
myDemo[41725:1739115] current thread = {number = 1, name = main}
myDemo[41725:1739115] 222
首先我们把此demo的堆栈贴出来

通过这个demo,就是按照我们所理解的串行执行,线程也是在主线程,因为我们本身就是默认在主线程运行,就像上面讲的:dispatch_sync只是在当前线程执行
// 并行队列的同步执行
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_CONCURRENT);
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
[NSThread sleepForTimeInterval:5];
});
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
// 运行结果
myDemo[82272:3241865] current thread = {number = 1, name = main}
myDemo[82272:3241865] 111
myDemo[82272:3241865] current thread = {number = 1, name = main}
myDemo[82272:3241865] 222
堆栈队列

通过这个demo,我可以看到,即便是用的并行队列,依然还是在主线程,并没有重启一个新的线程,并且是串行执行。
说明,我一开始总结的是对的,执行dispatch_sync,并没有重启线程,即便是并行队列。下面再看其他的demo
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_SERIAL);// 创建串行队列
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
});
// 此处就会死锁造成crash.
// 我们来看另外一个例子
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_CONCURRENT);// 创建并行队列
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
});
// 执行结果
myDemo[84905:3394929] current thread = {number = 1, name = main}
myDemo[84905:3394929] 111
myDemo[84905:3394929] current thread = {number = 1, name = main}
myDemo[84905:3394929] 222
// 执行结果依然在主线程
通过这两个例子的比较,只有在同步执行,串行队列的情况下,才会造成死锁。使用并行队列的时候,同步执行,依然没问题,并且依然在主线程。下面,我们上面那个例子的堆栈信息截屏下来
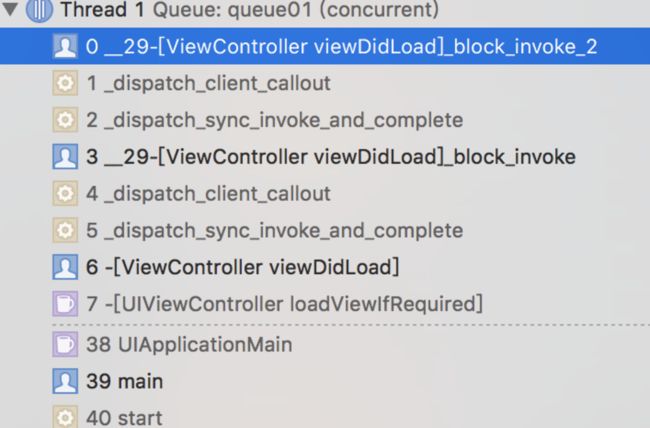
// 不是通过create queue的方式,创建全局的并行队列
dispatch_queue_t queue01 = dispatch_get_global_queue(0, 0);
dispatch_sync(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
// 执行结果
myDemo[1637:4224206] current thread = {number = 1, name = main}
myDemo[1637:4224206] 222
这种方式执行的是_dispatch_sync_function_invoke
堆栈:

我根据上面3中堆栈信息,来分析dispatch_sync源码执行,解答为什么如此执行
dispatch_sync(dispatch_queue_t dq, dispatch_block_t work)
{
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_private_data(dq, work, 0);
}
dispatch_sync_f(dq, work, _dispatch_Block_invoke(work));
}
DISPATCH_NOINLINE
void
dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func)
{
if (likely(dq->dq_width == 1)) {
// 串行队列执行到这里
return dispatch_barrier_sync_f(dq, ctxt, func);
}
// Global concurrent queues and queues bound to non-dispatch threads
// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dq))) {
// 通过下面的堆栈,当创建全局并行队列的时候,才会执行到此方法
return _dispatch_sync_f_slow(dq, ctxt, func, 0);
}
_dispatch_introspection_sync_begin(dq);
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dq, ctxt, func, 0);
}
// 通过上面并行队列堆栈发现dispatch_queue_create创建的并且队列,会调用此方法
_dispatch_sync_invoke_and_complete(dq, ctxt, func);
}
DISPATCH_NOINLINE
void
dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_tid tid = _dispatch_tid_self();
// The more correct thing to do would be to merge the qos of the thread
// that just acquired the barrier lock into the queue state.
//
// However this is too expensive for the fastpath, so skip doing it.
// The chosen tradeoff is that if an enqueue on a lower priority thread
// contends with this fastpath, this thread may receive a useless override.
//
// Global concurrent queues and queues bound to non-dispatch threads
// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dq, tid))) {
return _dispatch_sync_f_slow(dq, ctxt, func, DISPATCH_OBJ_BARRIER_BIT);
}
_dispatch_introspection_sync_begin(dq);
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dq, ctxt, func, DISPATCH_OBJ_BARRIER_BIT);
}
// 串行队列的时候,执行此方法
_dispatch_queue_barrier_sync_invoke_and_complete(dq, ctxt, func);
}
通过上面串行队列的堆栈,我看到执行到此方法_dispatch_queue_barrier_sync_invoke_and_complete
DISPATCH_NOINLINE
static void
_dispatch_queue_barrier_sync_invoke_and_complete(dispatch_queue_t dq,
void *ctxt, dispatch_function_t func)
{
// 首先先执行此方法
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
if (unlikely(dq->dq_items_tail || dq->dq_width > 1)) {
return _dispatch_queue_barrier_complete(dq, 0, 0);
}
// Presence of any of these bits requires more work that only
// _dispatch_queue_barrier_complete() handles properly
//
// Note: testing for RECEIVED_OVERRIDE or RECEIVED_SYNC_WAIT without
// checking the role is sloppy, but is a super fast check, and neither of
// these bits should be set if the lock was never contended/discovered.
const uint64_t fail_unlock_mask = DISPATCH_QUEUE_SUSPEND_BITS_MASK |
DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_DIRTY |
DISPATCH_QUEUE_RECEIVED_OVERRIDE | DISPATCH_QUEUE_SYNC_TRANSFER |
DISPATCH_QUEUE_RECEIVED_SYNC_WAIT;
uint64_t old_state, new_state;
// similar to _dispatch_queue_drain_try_unlock
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
new_state = old_state - DISPATCH_QUEUE_SERIAL_DRAIN_OWNED;
new_state &= ~DISPATCH_QUEUE_DRAIN_UNLOCK_MASK;
new_state &= ~DISPATCH_QUEUE_MAX_QOS_MASK;
if (unlikely(old_state & fail_unlock_mask)) {
os_atomic_rmw_loop_give_up({
return _dispatch_queue_barrier_complete(dq, 0, 0);
});
}
});
if (_dq_state_is_base_wlh(old_state)) {
_dispatch_event_loop_assert_not_owned((dispatch_wlh_t)dq);
}
}
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_sync_function_invoke_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_thread_frame_s dtf;
_dispatch_thread_frame_push(&dtf, dq);
// 在我们的串行队列中,最终执行到此方法
_dispatch_client_callout(ctxt, func);
_dispatch_perfmon_workitem_inc();
_dispatch_thread_frame_pop(&dtf);
}
并行队列串行执行的时候,会执行_dispatch_sync_invoke_and_complete
DISPATCH_NOINLINE
static void
_dispatch_sync_invoke_and_complete(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func)
{
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
_dispatch_queue_non_barrier_complete(dq);
}
最终依然会执行到_dispatch_client_callout
通过上面的源码的分析,在执行dispatch_sync的时候,并不会创建新的线程。
dispatch_async
dispatch_async运用了底层线程池,会在和当前线程不同的线程上处理任务。同一个串行队列在异步执行,会在同一个线程中。不同的串行队列,异步执行,才会重启一个线程。但是并行队列,每次都会重启一个线程。
首先,我依然还是通过几个例子,还看看什么效果,并且调出他们的堆栈.
// 串行队列异步执行
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
});
// 执行结果
myDemo[38842:5876694] current thread = {number = 3, name = (null)}
myDemo[38842:5876694] 111
调用堆栈:

// 异步队列异步执行
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
});
// 执行结果
myDemo[39184:5895013] current thread = {number = 3, name = (null)}
myDemo[39184:5895013] 111
调用堆栈:

// 创建全局异步队列
dispatch_queue_t queue01 = dispatch_get_global_queue(0, 0);
dispatch_async(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
});
// 执行结果
myDemo[39245:5898319] current thread = {number = 3, name = (null)}
myDemo[39245:5898319] 111
调用堆栈:

通过上面的代码显示,无论是我们创建的时候串行队列,还是异步队列,或者是全局队列,只要异步执行,都会创建新的线程,只不过调用堆栈,有些许不同,后面,我们讲解代码的时候,会根据堆栈来讲解。
下面,我来看一下,其他的情况:
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue01, ^{
sleep(5);
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
});
dispatch_async(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
// 执行结果
myDemo[39545:5914239] current thread = {number = 3, name = (null)}
myDemo[39545:5914239] 111
myDemo[39545:5914239] current thread = {number = 3, name = (null)}
myDemo[39545:5914239] 222
同一个串行队列异步执行,会在同一个异步线程中,串行执行
dispatch_queue_t queue01 = dispatch_queue_create("queue01", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue01, ^{
sleep(5);
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
});
dispatch_async(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
// 执行结果
myDemo[39642:5919537] current thread = {number = 3, name = (null)}
myDemo[39642:5919537] 222
myDemo[39642:5919535] current thread = {number = 4, name = (null)}
myDemo[39642:5919535] 111
同一个并行队列,异步执行,会分别生成两个不同的线程。相当于是每一次的并行队列,异步执行,都会重启一个线程执行
// 全局队列
dispatch_queue_t queue01 = dispatch_get_global_queue(0, 0);
dispatch_async(queue01, ^{
sleep(5);
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"111");
});
dispatch_async(queue01, ^{
NSLog(@"current thread = %@", [NSThread currentThread]);
NSLog(@"222");
});
// 执行结果
myDemo[39753:5926161] current thread = {number = 3, name = (null)}
myDemo[39753:5926161] 222
myDemo[39753:5926162] current thread = {number = 4, name = (null)}
myDemo[39753:5926162] 111
可以上面的是同样的结果。
异步源码的分析
通过上面的串行队列异步执行的堆栈,我们清楚分别执行:
_dispatch_queue_push->start_wqthread->_dispatch_call_block_and_release
#ifdef __BLOCKS__
void
dispatch_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DISPATCH_OBJ_CONSUME_BIT;
_dispatch_continuation_init(dc, dq, work, 0, 0, dc_flags);
_dispatch_continuation_async(dq, dc);
}
持续更新。。。。
GitHub地址:https://github.com/BernardChina/BCStudy/blob/master/GCD%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90.md