Android为什么推荐使用SparseArray来替代HashMap?
SparseArray也许你没听过,那正好今天就来学习一下咯,这也是Android官方推荐使用的,所以我们需要了解一下他的优势和劣势在哪些地方。
首先SparseArray用来和HashMap做比较,在安卓项目中,你新建一个HashMap对象,注意下面会有下划线,里面有提示

翻译成白话文的意思就是建议使用SparseArray替代HashMap来获得更好的表现。我们都知道HashMap在java中很常用,并且也很吃香,面试官经常会问到HashMap源码实现,既然HashMap的表现都这么牛逼了,那么为什么Android官方会推荐使用SparseArray呢?不要急,慢慢来~
首先来了解一下SparseArray,翻译过来称为“稀疏数组”,所谓稀疏数组就是数组中大部分的内容值都未被使用(或都为零),在数组中仅有少部分的空间使用。因此造成内存空间的浪费,为了节省内存空间,并且不影响数组中原有的内容值,我们可以采用一种压缩的方式来表示稀疏数组的内容。
下面有网上举例子的两张图,我挪过来了,如果涉及侵权问题,请联系我删除哈,毕竟自己照猫画虎重新画一个,浪费时间,没有必要:

可以看出来这是一个9*7的数组,它所占用的空间为63个,但是如图只有5个空间使用了,其他的都是浪费,浪费是可耻的,所以按照稀疏数组的整理,就变成了下面这张图所示
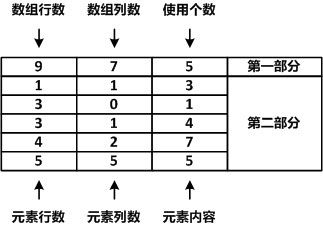
大家应该都能看懂吧,二维数组对应的值,那么这么一来所占空间仅仅为3*6=18个了,相比起来是否节省很多,所以这就是为什么Android官方推荐使用SparseArray的原因了,我们稍后来验证。
下面我们来写一段程序来看看SparseArray和HashMap在处理数据上面的性能情况。
- HashMap正向插入数据
HashMap map = new HashMap();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
map.put(i, String.valueOf(i));
}
long memory = Runtime.getRuntime().totalMemory();
long end = System.currentTimeMillis();
long usedTime = end - start;
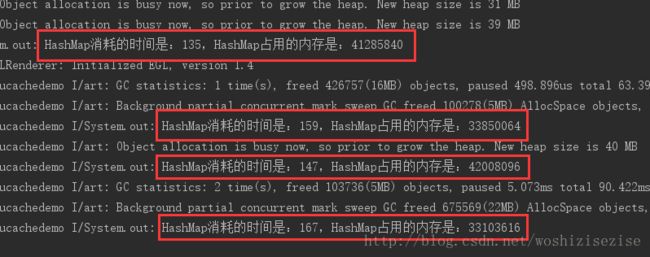
System.out.println("HashMap消耗的时间是:" + usedTime + ",HashMap占用的内存是:" + memory); 输出结果:

- SparseArray正向插入数据
SparseArray sparse = new SparseArray<>();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
sparse.put(i, String.valueOf(i));
}
long memory = Runtime.getRuntime().totalMemory();
long end = System.currentTimeMillis();
long usedTime = end - start;
System.out.println("SparseArray消耗的时间是:" + usedTime + ",SparseArray占用的内存是:" + memory); 输出结果:

公平起见,这两段代码我都是分别运行在Android程序中的,一次说明不了什么结果,所以我重复启动了几次项目,这个时候再做对比就很明显了,这四次结果SpaseArray的内存占用都是明显低于HashMap的内存占用的,消耗的时间好像也是这样的,但是Android官方并没有提到效率这个问题,我们之前分析SpaseArray的内存结果也没有发现这个现象,那么这是为什么呢?不要急,下面我们反向来插入一次数据再做一次比较。
- HashMap反向插入数据
HashMap<Integer, String> map = new HashMap<Integer, String>();
long start = System.currentTimeMillis();
for (int i=100000-1;i>=0;i--) {
map.put(i, String.valueOf(100000-i-1));
}
long memory = Runtime.getRuntime().totalMemory();
long end = System.currentTimeMillis();
long usedTime = end - start;
System.out.println("HashMap消耗的时间是:" + usedTime + ",HashMap占用的内存是:" + memory);输出结果:
- SparseArray反向插入数据
SparseArray sparse = new SparseArray<>();
long start = System.currentTimeMillis();
for (int i=100000-1;i>=0;i--) {
sparse.put(i, String.valueOf(100000-i-1));
}
long memory = Runtime.getRuntime().totalMemory();
long end = System.currentTimeMillis();
long usedTime = end - start;
System.out.println("SparseArray消耗的时间是:" + usedTime + ",SparseArray占用的内存是:" + memory); 输出结果:
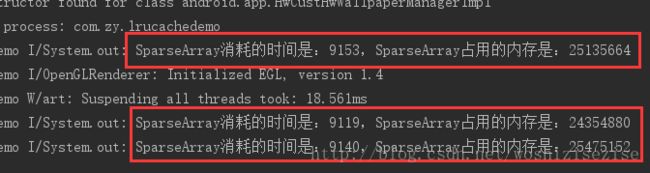
运行了三次以后我都不好意思再运行了,可以看到倒入的情况下,消耗时间表现非常糟糕,并且页面这个时候处于卡顿状态,但是仍然有一点,那就是SparseArray占用的内存依然比HashMap优秀的多,由于SparseArray每次在插入的时候都要使用二分查找判断是否有相同的值被插入.因此这种倒序的情况是SparseArray效率最差的时候。
源码分析
打开SparseArray源码,我们先看看左边的结构视图有哪些方法:

- 看看开头定义的变量
private static final Object DELETED = new Object();
private boolean mGarbage = false;
private int[] mKeys;
private Object[] mValues;
private int mSize;很直接的可以看到有两个数组,并且他们的命名都那么的直接,一个存放key,一个存放value,还有一个大小。
- 看看构造函数
public SparseArray() {
this(10);
}
public SparseArray(int initialCapacity) {
if (initialCapacity == 0) {
mKeys = EmptyArray.INT;
mValues = EmptyArray.OBJECT;
} else {
mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);
mKeys = new int[mValues.length];
}
mSize = 0;
}默认的构造函数也会调用重载方法并给初始容量设为10。
- 看看插入方法put
/**
* Adds a mapping from the specified key to the specified value,
* replacing the previous mapping from the specified key if there
* was one.
*/
//注释已经说明了如果key不存在,则插入key和value,如果key存在,则替换原来的value
//所以这个方法也可以当作修改
public void put(int key, E value) {
//通过二分法查找key
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
//如果i>0,说明之前已经存在了这个key,所以直接覆盖原来的value
mValues[i] = value;
} else {
//如果i<0,说明key不存在,所以i肯定是负数,所以我们要取相反数
i = ~i;
//如果i在mSize范围之内并且之前的值被删除了,那么直接进行赋值即可
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
//如果大小超过了keys的长度,说明存在无效的数据,这个时候需要回收了
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
//回收完后引用可能改变了,所以需要对key重新二分法查找并取反
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}- 看看插入方法append
/**
* Puts a key/value pair into the array, optimizing for the case where
* the key is greater than all existing keys in the array.
*/
public void append(int key, E value) {
if (mSize != 0 && key <= mKeys[mSize - 1]) {
put(key, value);
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
}
mKeys = GrowingArrayUtils.append(mKeys, mSize, key);
mValues = GrowingArrayUtils.append(mValues, mSize, value);
mSize++;
}可以看出来,append方法其实很简单,它也是调用了put方法完成键值对的插入,并且调用回收的逻辑也是一样的。
- 看看删除的4种方法
1.delete(int key)
/**
* Removes the mapping from the specified key, if there was any.
*/
public void delete(int key) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
if (mValues[i] != DELETED) {
mValues[i] = DELETED;
mGarbage = true;
}
}
}如果通过二分法能找到key,就将对应的索引对应的value设置为DELETED常量,并且标识mGarbage = true。
2.remove(int key)
public void remove(int key) {
delete(key);
}直接调用delete方法
3.removeAt(int index)
public void removeAt(int index) {
if (mValues[index] != DELETED) {
mValues[index] = DELETED;
mGarbage = true;
}
}原理和delete方法一样
4.clear()
public void clear() {
int n = mSize;
Object[] values = mValues;
for (int i = 0; i < n; i++) {
values[i] = null;
}
mSize = 0;
mGarbage = false;
}这个方法顾名思义,将数组内容全部清空置为null。
- 看看修改的方法setValueAt(int index, E value)
public void setValueAt(int index, E value) {
if (mGarbage) {
gc();
}
mValues[index] = value;
}如果标记为垃圾的话,先进行一次垃圾回收,然后再将指定的值设置到对应的索引上。
- 看看获取方法get()、get(int key, E valueIfKeyNotFound)
public E get(int key) {
return get(key, null);
}
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}其实最终调用的都是get(int key, E valueIfKeyNotFound)方法,只不过第一个找不到key对应的value时返回的是null,第二个方法则可以由我们自己指定的默认值。
总结
大家一定要注意,我们插入的key并不是索引的角标,不要以为是int型就是角标了,那就错了,其实和map一样,都是通过key来查找value,我们传入key通过二分法生成一个index,这个index才是角标。
注意内存二字很重要,因为它仅仅提高内存效率,而不是提高执行效率,所以也决定它只适用于android系统(内存对android项目有多重要,地球人都知道)
最后引用别人总结的比较好的一段话来结束这篇文章:
SparseArray有两个优点:1.避免了自动装箱(auto-boxing),2.数据结构不会依赖于外部对象映射。我们知道HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置,存放的都是数组元素的引用,通过每个对象的hash值来映射对象。而SparseArray则是用数组数据结构来保存映射,然后通过折半查找来找到对象。但其实一般来说,SparseArray执行效率比HashMap要慢一点,因为查找需要折半查找,而添加删除则需要在数组中执行,而HashMap都是通过外部映射。但相对来说影响不大,最主要是SparseArray不需要开辟内存空间来额外存储外部映射,从而节省内存。