SOLOv 2:实例分割(动态、更快、更强)
SOLOv 2:实例分割(动态、更快、更强)
SOLOv2:
Dynamic, Faster and Stronger

论文链接:
https://arxiv.org/pdf/2003.10152.pdf
代码链接:https://github.com/aim-uofa/AdelaiDet
摘要
在这项工作中,本文的目标是建立一个简单,直接,快速的实例分割框架,具有很强的性能。本文遵循王等人SOLO的原则。“SOLO:按位置分割对象”[33]。重要的是,本文进一步通过动态学习对象分段器的mask头,使得mask头受位置的约束。具体地,将掩模分支分解为掩模核分支和掩模特征分支,分别负责卷积核和卷积特征的学习。此外,本文提出矩阵NMS(非最大抑制)来显著减少由于NMSofmasks引起的推理时间开销。本文的matrix NMS一次完成了并行矩阵运算的NMS,并获得了更好的结果。本文演示了一个简单的直接实例分割系统,在速度和精度上都优于一些最新的方法。一个轻量级版本的SOLOv2以31.3fps的速度运行,产生37.1%的AP。此外,本文在目标检测(从本文的掩模副产品)和全景分割方面的最新结果显示,除了实例分割之外,还可能成为许多实例级识别任务的新的强基线。
- Introduction
通过改进,SOLOv2的AP性能比SOLOv1高出1.9%,而速度提高了33%。Res-50-FPN SOLOv2在具有挑战性的MS-COCO数据集上以18 FPS的速度实现38.8%的掩模AP,在单个V100 GPU卡上进行评估。一个轻量级版本的SOLOv2以31.3FPS的速度执行,产生37.1%的掩模AP。有趣的是,虽然本文的方法彻底消除了bounding box的概念,但是本文的bounding box的副产品,即直接将预测的掩模转换为bounding box,产生42.4%的AP用于bounding box对象检测,它甚至超过了许多最先进、高度工程化的目标检测方法。
- Related Work
而本文的方法是从SOLO[33]发展而来的,直接将原始的掩模预测解耦为核学习和特征学习。不需要锚箱。不需要标准化。不需要边界框检测。本文直接将输入图像映射到所需的对象类和对象掩码。训练和推理都简单得多。因此,本文提出的框架简单得多,但实现了显著的更好的性能(6%的AP以可比的速度更好);本文的最佳模型实现了41.7 AP,而YOLACT的最佳31.2%AP。
在传统的卷积层中,学习的卷积核保持固定并且独立于输入,例如,对于每个图像和图像的每个位置,权重是相同的。以前的一些作品探索了在传统卷积中引入更多灵活性的思想。空间变换网络[15]预测全局参数变换以扭曲特征映射,从而允许网络根据输入自适应地变换特征映射。动态滤波器[16]用于主动预测卷积滤波器的参数。它以一种特定于样本的方式将动态生成的过滤器应用于图像。可变形卷积网络[8]通过预测每个图像位置的偏移量来动态学习采样位置。将动态方案引入到实例分割中,实现了基于位置的实例分割学习。
与以前的方法不同,本文的矩阵NMS同时解决了硬删除和顺序操作的问题。结果表明,该矩阵NMS能够在1ms内完成500个掩模的简单PyTorch实现,与网络评估时间相比可以忽略不计,其AP值比快速NMS高0.4%。

- A Revisit to SOLOv1
SOLOv1框架的核心思想是按位置分割对象。输入图像在概念上分为S×S网格。如果对象的中心落在网格单元中,则该网格单元负责预测语义类别以及分配每像素位置类别。有两个分支:类别分支和掩码分支。类别分支预测语义类别,而掩码分支分割对象实例。具体地说,范畴分支输出S×S×C形张量,其中C是对象类的个数。
该层可视为S2类。每一类都是负责对是否属于该位置类别的像素进行分类。如在[33]中所讨论的,由于在大多数情况下对象在图像中稀疏地定位,所以预测M有点多余。这意味着只有一小部分的S2类在一次推理中起作用。解耦合SOLO[33]通过将S2分类分离为两组S分类来解决这个问题,分别对应于S水平和S垂直位置类别。因此,输出空间从H×W×S2减小到H×W×2S。从另一个角度看,由于输出M是冗余的,特征F是固定的,为什么不直接学习卷积核G呢?这样,本文可以简单地从预测的S2分类中选择有效的分类,并动态地进行卷积。模型参数的数目也减少了。此外,由于预测的内核是根据输入动态生成的,因此它具有灵活性和自适应性。此外,每个S2分类都取决于位置。它符合按位置分割对象的核心思想,并且通过按位置预测分割器而更进一步。本文在第4.1节中说明了详细的方法。
- SOLOv2
在本节中,本文将详细介绍提议的SOLOv2设计。
4.1. Dynamic Instance Segmentation
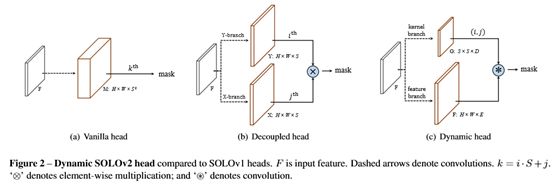
本文继承了SOLOv1的大部分设置,例如网格单元、多级预测、CoordConv[24]和损失函数。在此基础上,提出了将原掩模分支解耦为掩模核分支和掩模特征分支,分别预测卷积核和卷积特征的动态方案。本文在图2中显示了与SOLOv1的比较。
4.1.1 Mask Kernel Branch
掩码核分支与语义类别分支一起位于预测头中。头部工作在由FPN[21]生成的特征地图金字塔上。头部的两个分支由4个用于特征提取的conv和最后一个用于预测的conv组成。头部的权重在不同的特征图级别上共享。本文将空间功能添加到核分支,通过给予第一个对标准化坐标的卷积访问,即连接两个额外的输入通道。对于每个网格,核分支预测维度输出指示预测的卷积核权重,其中是参数的数量。对于生成与E个输入通道的1×1卷积的权重,D等于E。对于3×3卷积,D等于9E。这些生成的权重取决于位置,即网格单元。如果将输入图像划分为S×S网格,则输出空间为S×S×D,对输出没有激活作用。
4.1.2 Mask Feature Branch
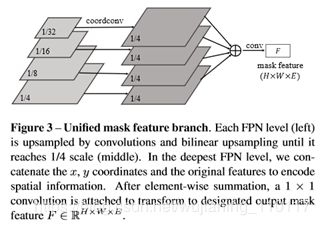
由于掩模特征和掩模核是分离和预测的,因此有两种方法来构造掩模特征分支。本文可以把它和核分支一起放到头部。这意味着本文可以预测每个FPN级别的掩模特性。或者,预测所有FPN级别的单一掩模特征表示。本文通过实验比较了第5.1.3节中的两种实现。最后,本文采用后者的有效性和效率。为了学习单一的高分辨率掩模特征表示,本文在文[17]的语义分割的基础上,引入特征金字塔融合。经过3×3conv、群范数[34]、ReLU和2×双线性上采样的重复阶段,FPN特征P2到P5被合并成1/4尺度的单个输出。元素求和后的最后一层由1×1卷积、群范数和ReLU组成。细节如图3所示。值得注意的是,在卷积和双线性上采样之前,本文将归一化像素坐标馈送到最深的FPN水平(1/32比例)。所提供的准确位置信息对于实现位置敏感和预测实例感知特征非常重要。
4.1.3 Forming Instance Mask
总的来说,每个预测级别最多有S2个掩码。最后,本文使用所提出的矩阵NMS来获得最终的实例分割结果。
4.1.4 Learning and Inference
标签分配和丢失函数与SOLOv1相同。训练损失函数定义如下: L=Lcate+λL mask,(2)其中Lcate是语义类别分类的常规焦点损失[23],Lmask是掩模预测的冰损失。有关更多细节,请参阅[33]。
本文首先使用0.1的置信阈值来过滤低置信度的预测。然后使用相应的预测掩模核对掩模特征进行卷积。使用sigmoid操作时,本文使用0.5的阈值将预测的软掩码转换为二进制掩码。最后一步是矩阵NMS。
4.2. Matrix NMS
动机
本文的矩阵NMS是由softms[1]驱动的。软NMS以重叠的单调递减函数(iou)衰减其他检测分数。通过递归地根据IoUs衰减分数,以最小分数阈值消除较高的IoU检测。然而,这类过程与传统的贪婪网络管理系统一样是顺序的,不能并行实现。
图4显示了Pytorch样式的矩阵NMS的伪代码。在本文的代码库中,矩阵NMS比传统NMS快9倍,而且更精确(表7)。结果表明,矩阵NMS在精度和速度上均优于传统的NMS,可以很容易地集成到最新的检测/分割系统中。


5. Experiments
为了对SOLOv2算法进行评价,本文在MS-COCO上进行了实例分割、目标检测和全景分割三个基本任务的实验[22]。本文还介绍了最近提出的LVIS数据集的实验结果,该数据集有超过1K个类别,因此具有相当大的挑战性。
5.1. Instance segmentation
例如分割,本文通过评估COCO 5K val 2017分割来报告损伤和敏感性研究。本文还报告了COCO mask AP的test dev split,它是在评估服务器上评估的。 训练详情
利用随机梯度下降(SGD)对SOLOv2进行训练。本文使用同步SGD超过8 GPU,每个小批量总共16个图像。除非另有说明,否则所有模型均为36个阶段(即3×)训练,初始学习率为0.01,然后在第27个阶段除以10,在第33个阶段再次除以10。权重减为0.0001,动量为0.9。所有模型都由ImageNet预先训练的权重初始化。本文使用比例抖动,其中较短的图像侧随机采样从640到800像素。
5.1.1 Main Results
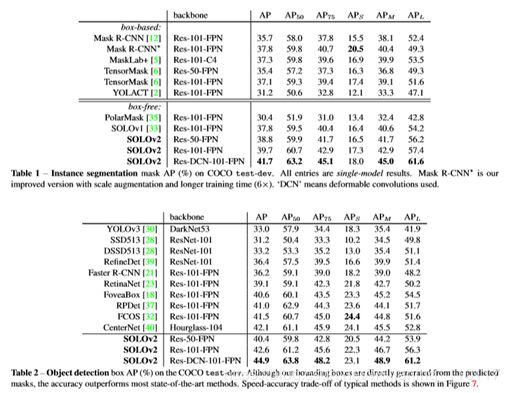
本文比较了SOLOv2和最新的方法在MS-COCO-test-dev上的实例分割,见表1。使用ResNet-101的SOLOv2实现了39.7%的掩模AP,这比SOLOv1和其他的状态实例分割方法要好得多。本文的方法尤其在大型物体(如+5.0apl)上显示了它的优越性。本文还提供了COCO上的速度精度权衡,以与一些主要的实例分割进行比较(图1)。本文展示了ResNet-50、ResNet-101、ResNet-DCN-101和第5.1.3节中描述的两个轻量级版本的模型。所提出的SOLOv2在精度和速度上都优于一系列最先进的算法。运行时间在本文的本地机器上进行测试,只有一个V100 GPU、Pytorch 1.2和CUDA 10.0。本文下载代码和预先训练的模型,在同一台机器上测试每个模型的推理时间。
5.1.2 SOLOv2 Visualization
本文从两个方面对SOLOv2的学习进行了可视化:掩模特征行为和动态学习卷积核卷积后的最终输出。本文将掩模特征分支的输出可视化。为了便于可视化,本文使用了一个有64个输出通道的模型(即,对于掩码预测之前的最后一个特征映射,e=64)。这里本文绘制64个通道中的每一个(回想一下通道空间分辨率是H×W),如图5所示。
主要有两种模式。首先,也是最重要的,掩模特征是位置感知的。它表现出明显的水平和垂直扫描图像中的物体的行为。有趣的是,它确实符合分离头部独奏中的目标:根据独立的水平和垂直位置类别分割对象。另一个明显的模式是,一些特征映射负责激活所有前景对象,例如,白框中的对象。最终输出如图8所示。不同的物体是不同的颜色。本文的方法在不同的场景中显示出很有希望的结果。值得指出的是,边界处的细节分割得很好,特别是对于大型物体。在图6中,本文比较了Mask R-CNN的对象细节。本文的方法显示出很大的优势。
5.1.3 Ablation Experiments
本文研究并比较了以下四个方面:(a)用于对掩模特征进行卷积的核形状;(b)用于掩模核分支和掩模特征分支的坐标变换;(c)统一的掩模特征表示和(d)矩阵NMS的有效性。
内核形状
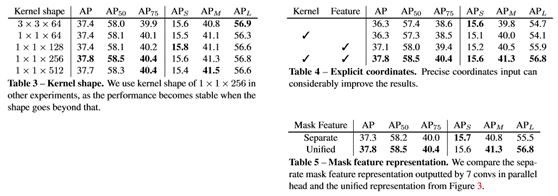
本文从两个方面来考虑核的形状:输入通道的数目和核的大小。比较结果见表3。1×1conv的性能相当于3×3conv,将输入通道数从128个增加到256个,AP增益为0.4%。当它超过256时,性能变得稳定。在这项工作中,本文将所有其他实验中的输入通道数设置为256个。
坐标的有效性
由于本文的方法是按位置分割对象,或者按特定位置学习对象分割器,因此位置信息非常重要。例如,如果掩码内核分支不知道位置,则具有相同外观的对象可能具有相同的预测内核,从而导致相同的输出掩码。另一方面,如果掩模特征分支不知道位置信息,它就不知道如何按照与掩模核匹配的顺序将像素分配给不同的特征通道。如表4所示,该模型在没有显式坐标输入的情况下获得36.3%的AP。结果相当好,因为CNNs可以隐式地从常用的零填充操作中学习绝对位置信息,如[14]所示。本文的掩模特性分支中的金字塔零填充应该有很大的贡献。然而,隐式学习的位置信息是粗糙和不准确的。当通过级联额外的坐标通道使卷积访问自己的输入坐标时,本文的方法获得1.5%的绝对AP增益。
单一遮罩功能
对于掩模特征学习,本文有两种选择:分别在每个FPN层的头部学习特征,或者构造一个统一的表示。对于前者,本文实现为SOLOv1,并使用7个3×3conv来预测掩模特征。对于后者,详细的实现如图3所示。本文在表5中比较了这两种实现。如图所示,统一的表示方法取得了更好的效果,特别是对于中大型对象。这很容易理解:在SOLOv1中,大尺寸对象被分配到低空间分辨率的高级特征映射,从而导致粗略的边界预测。
已解耦的Dynamicvs
动力头和解耦头都是单头的有效变体。本文比较了表6中的结果。所有设置都是相同的,除了头部类型,这意味着对于动态头部,本文使用上述单独的功能。动态头比解耦头的AP值高0.7%。本文认为增益来自于动态方案,该方案根据输入动态地学习核权重。矩阵可以完全并行地实现。表7给出了硬NMS、软NMS、快NMS和本文的矩阵NMS的速度和精度比较。由于所有方法都需要计算IoU矩阵,因此本文预先计算IoU矩阵以进行公平比较。这里报告的速度是仅NMS进程的速度,不包括计算IoU矩阵。硬NMS和软NMS在当前的目标检测和分割模型中有着广泛的应用。不幸的是,这两种方法都是递归的,并且花费了大量的时间预算(22ms)。 本文的矩阵NMS只需要<1 ms,几乎是免费的!在这里,本文还展示了快速NMS的性能,它利用矩阵运算,但有性能损失。综上所述,本文的矩阵NMS在速度和精度上都显示了它的优势。
实时设置本文为不同的目的设计了两个轻量级模型。
1)速度优先,预测头中的卷积层数减少到2层,输入较短侧为448。
2)精度优先,预测头中的卷积层数减少到3层,输入较短侧为512层。此外,可变形卷积[8]被用于预测头的主干和最后一层。本文用3×时间表训练两个模型,从[352512]中随机抽取较短的边。结果见表8。SOLO不仅可以推动最先进的技术,而且已经为实时应用做好了准备。
5.2. Bounding-box Object Detection
虽然本文的实例分割解决方案消除了Bounding-box预测的依赖性,但是本文能够从每个实例掩码中生成4D对象Bounding-box。在表2中,本文将生成的盒子检测性能与COCO上的其他对象检测方法进行了比较。所有模型均在2017数据子集上进行训练,并在测试开发上进行测试。如表2所示,本文的检测结果优于大多数方法,特别是对于大规模对象,证明了SOLOv2在对象盒检测中的有效性。类似于实例分割,本文还绘制了图7中不同方法的速度/精度折衷曲线。本文用ResNet-101和上面描述的两个轻量级版本展示本文的模型。结果表明,SOLOv2的Bounding-box性能在精度和速度上均优于最新的目标检测方法。这里本文强调,本文的结果是直接从现成的实例掩码生成的,没有任何基于框的监督培训或工程。图7的观察结果如下。如果本文不太关心掩码注释和边界框注释之间的成本差异,那么在本文看来,没有理由在下游应用中使用框检测器,因为本文的SOLOv2在精度和速度上都优于大多数现代检测器。
5.3. Panoptic Segmentation
提出的SOLOv2可以很容易地扩展到全景分割中,加入语义分割分支,类似于掩模特征分支。本文使用COCO 2018全景分割任务的注释。所有车型均在2017年列车子集上接受训练,并在2017年val2017上进行测试。本文使用与全景FPN中相同的策略来组合实例和语义结果。如表10所示,本文的方法获得了最新的结果,并且在很大程度上优于其他最近的无框方法。列出的所有方法都使用相同的主干(ResNet50FPN),除了SSAP(ResNet101)和Panoptic DeepLab(exception-71)。
5.4. Results on the LVIS dataset
LVIS[11]是最近提出的一个用于长尾目标分割的数据集,它有1000多个对象类别。在LVIS中,每个对象实例都用一个高质量的掩码分割,这个掩码超过了相关COCO数据集的注释质量。由于LVIS是新的,只有Mask R-CNN的结果是公开的。因此,本文只将SOLOv2与掩模R-CNN基线进行比较。表9报告了稀有(1∼10个图像)、常见(11∼100)和频繁(>100)子集以及整个AP的性能。本文的SOLOv2比基线方法的性能提高了1%左右。对于大型对象(APL),SOLOv2的AP改进率为6.7%,这与COCO数据集的结果一致。



- Conclusion
在这项工作中,本文从三个方面对SOLOv1实例分割进行了显著的改进。
•本文建议学习用于掩模预测磁头的自适应动态卷积核,并根据位置进行调整,从而实现更紧凑但更强大的磁头设计,并通过减少触发器获得更好的结果。
•本文重新设计了掩模功能,如图3所示,它预测了更精确的边界。特别是对于中、大尺寸目标,与SOLOv1相比,得到了更好的掩模ap。
•此外,与目标检测中的box NMS不同,例如,分割在推理效率方面的瓶颈是NMSofmasks。以前的工作要么使用box-NMS作为代理,要么通过近似加速它,从而导致对mask-AP的损害。本文设计了一种简单而快速的NMS策略,称为矩阵NMS,用于掩模的NMS处理,而不需要对掩模AP进行破坏。
本文在microsoftco和LVIS数据集上的实验表明,所提出的SOLOv2在精度和速度方面都具有优越的性能。作为多功能的实例级识别任务,本文表明,在没有对框架进行任何修改的情况下,SOLOv2在全景分割方面具有竞争力。由于它的简单性(无提案、无锚、类FCN),在准确性和速度上都有很强的性能,并且有可能解决许多实例级的任务,本文希望SOLOv2能够成为一种强基线的实例识别方法,并激励未来的工作,使其充分的潜力可以利用,因为本文认为,还有很大的改进空间。