Spark ML 构建回归模型
一、数据的加载
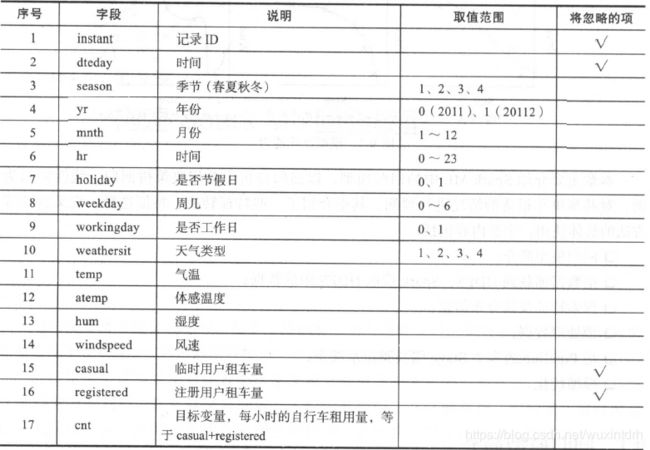
1.1、共享单车数据属性
1.2、加载数据
val rawData = spark.read
.format("csv")
.option("header", true)
.load("C:\\Users\\12285\\Desktop\\hour.csv")
rawData.show(10)
// 查看数据结构
rawData.printSchema()
// 查看主要字段的统计信息
rawData.describe("dteday", "holiday", "weekday", "temp").show()

主要特征的重要程度
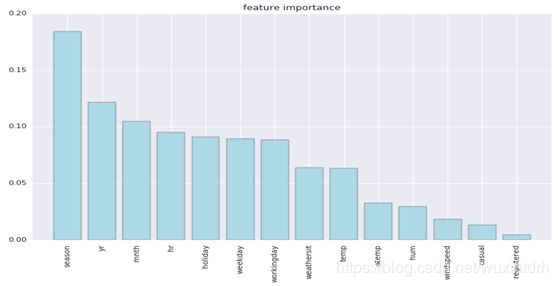
1.4、各特征的重要性
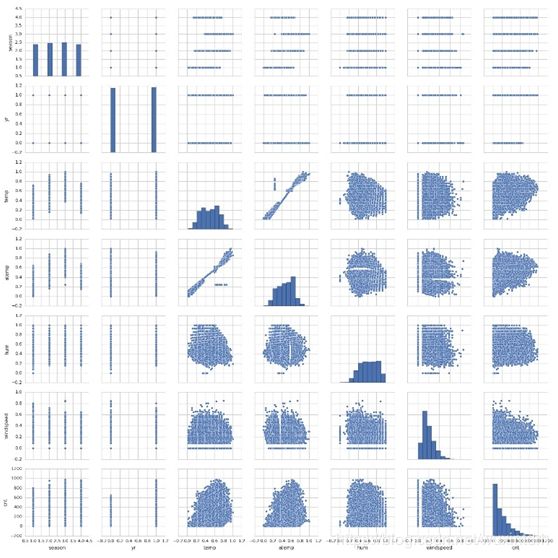
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df=pd.read_csv('/home/hadoop/data/bike/hour.csv',header=0)
sns.set(style='whitegrid',context='notebook')
cols=['season','yr','temp','atemp','hum','windspeed','cnt']
sns.pairplot(df[cols],size=2.5)
plt.show()
二、数据的预处理
2.1、特征的选择
首先将字符型的特征转换为数值类型, 并过滤instant、dteday、casual、registered4个无关或冗余特征。cnt特征作为标志特征。
// 特征选择
val data1 = rawdata.select(
rawdata("season").cast("Double"),
rawdata("yr").cast("Double"),
rawdata("mnth").cast("Double"),
rawdata("hr").cast("Double"),
rawdata("holiday").cast("Double"),
rawdata("weekday").cast("Double"),
rawdata("workingday").cast("Double"),
rawdata("weathersit").cast("Double"),
rawdata("temp").cast("Double"),
rawdata("atemp").cast("Double"),
rawdata("hum").cast("Double"),
rawdata("windspeed").cast("Double"),
rawdata("cnt").cast("Double").alias("label"))
data1.show(10)
2.2、将原数据组合成特征向量
// 生成一个存放以上预测特征的特征向量
val featuresArray = Array("season", "yr", "mnth", "hr", "holiday",
"weekday", "workingday", "weathersit", "temp", "atemp", "hum", "windspeed")
// 把源数据组合成特征向量features
val assembler = new VectorAssembler().setInputCols(featuresArray).setOutputCol("features")
三、特征转换
这些特征大部分大部分是分类特征, 有些值是连续型 如气温、湿度等特征, 使用决策数据回归时, 技术上可以通过给定类别个数的最大值(如24),自动识别那些特征作为类别特征,那些作为连续性特征。这里把不同值小于或等于24的特征作为类别特征,大于24的视为连续性特征,并对分类特征索引化或数值化。
3.1、使用决策树回归算法前,我们对类别特征进行索引化或数值化。
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(24)
3.2、如果使用线性回归算法,我们需要对类别特征使用OneHotEncoder, 把它们转化为二元向量, 对前8个类别字段或特征转换为二元向量
// 对前8个类别字段或特征转换为二元向量。
val data2= new OneHotEncoder().setInputCol("season").setOutputCol("seasonVec")
val data3= new OneHotEncoder().setInputCol("yr").setOutputCol("yrVec")
val data4= new OneHotEncoder().setInputCol("mnth").setOutputCol("mnthVec")
val data5= new OneHotEncoder().setInputCol("hr").setOutputCol("hrVec")
val data6= new OneHotEncoder().setInputCol("holiday").setOutputCol("holidayVec")
val data7= new OneHotEncoder().setInputCol("weekday").setOutputCol("weekdayVec")
val data8= new OneHotEncoder().setInputCol("workingday").setOutputCol("workingdayVec")
val data9= new OneHotEncoder().setInputCol("weathersit").setOutputCol("weathersitVec")
3.2.1、因OneHotEncoder不是Estimator,这里我们对采用回归算法的数据另外进行处理,先建立一个流水线,把以上转换组装到这个流水线上。
// 因OneHotEncoder不是Estimator,这里我们对采用回归算法的数据另外进行处理,
// 先建立一个流水线,把以上转换组装到这个流水线上。
val pipeline_en = new Pipeline().setStages(Array(data2, data3, data4, data5, data6, data7, data8, data9))
val data_lr = pipeline_en.fit(data1).transform(data1)
3.2.2、把原来的4个及转换后的8个二元特征向量,拼接成一个feature向量。
val assembler_lr = new VectorAssembler()
.setInputCols(Array("seasonVec", "yrVec", "mnthVec", "hrVec", "holidayVec", "weekdayVec", "workingdayVec", "weathersitVec", "temp", "atemp", "hum", "windspeed"))
.setOutputCol("features_lr")
四、组装
4.1、决策树
def testDT() = {
// 把源数据组合成特征向量features
val assembler = new VectorAssembler().setInputCols(featuresArray).setOutputCol("features")
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(24)
//对data1数据集进行随机划分,这份数据用于决策模型
val Array(trainingData, testData) = data1.randomSplit(Array(0.7, 0.3), 12)
// 设置决策树回归模型
val dt = new DecisionTreeRegressor()
.setLabelCol("label")
.setFeaturesCol("indexedFeatures")
.setMaxBins(64)
.setMaxDepth(15)
// 把决策树回归模型涉及的特征转换及模型训练组装在一个流水线上。
val pipeline = new Pipeline().setStages(Array(assembler,featureIndexer, dt))
//训练决策树回归模型
val model = pipeline.fit(trainingData)
//预测决策树回归的值
val predictions = model.transform(testData)
// RegressionEvaluator.setMetricName可以定义四种评估器:rmse(缺省)、 mse、r^2、mae。
val evaluator =new RegressionEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("rmse")
//决策树模型评估指标
val rmse = evaluator.evaluate(predictions)
//rmse: Double = 61.62409114645229
}
4.2、线性回归
def testLinearR() = {
// 对前8个类别字段或特征转换为二元向量。
val data2 = new OneHotEncoder().setInputCol("season").setOutputCol("seasonVec")
val data3 = new OneHotEncoder().setInputCol("yr").setOutputCol("yrVec")
val data4 = new OneHotEncoder().setInputCol("mnth").setOutputCol("mnthVec")
val data5 = new OneHotEncoder().setInputCol("hr").setOutputCol("hrVec")
val data6 = new OneHotEncoder().setInputCol("holiday").setOutputCol("holidayVec")
val data7 = new OneHotEncoder().setInputCol("weekday").setOutputCol("weekdayVec")
val data8 = new OneHotEncoder().setInputCol("workingday").setOutputCol("workingdayVec")
val data9 = new OneHotEncoder().setInputCol("weathersit").setOutputCol("weathersitVec")
// 因OneHotEncoder不是Estimator,这里我们对采用回归算法的数据另外进行处理,先建立一个流水线,把以上转换组装到这个流水线上。
val pipeline_en = new Pipeline().setStages(Array(data2, data3, data4, data5, data6, data7, data8, data9))
val data_lr = pipeline_en.fit(data1).transform(data1)
// 把原来的4个及转换后的8个二元特征向量,拼接成一个feature向量。
val assembler_lr = new VectorAssembler()
.setInputCols(Array("seasonVec", "yrVec", "mnthVec", "hrVec", "holidayVec", "weekdayVec", "workingdayVec", "weathersitVec", "temp", "atemp", "hum", "windspeed"))
.setOutputCol("features_lr")
//对data2数据集进行随机划分,这份数据用于回归模型
val Array(trainingData_lr, testData_lr) = data_lr.randomSplit(Array(0.7, 0.3), 12)
// 设置线性回归模型的参数
val lr =new LinearRegression()
.setFeaturesCol("features_lr")
.setLabelCol("label")
.setFitIntercept(true)
.setMaxIter(20)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// 把线性回归模型涉及的特征转换、模型训练组装载一个流水上线。
val pipeline_lr= new Pipeline().setStages(Array(assembler_lr,lr))
//训练线性回归模型
val lrModel = pipeline_lr.fit(trainingData_lr)
//预测线性回归模型的值
val predictions_lr = lrModel.transform(testData_lr)
// RegressionEvaluator.setMetricName可以定义四种评估器:rmse(缺省)、 mse、r^2、mae。
val evaluator =new RegressionEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("rmse")
//决策树模型评估指标
val rmse_lr = evaluator.evaluate(predictions_lr)
// rmse_lr: Double = 102.05406408259029
}
从以上使用不同模型情况看来,决策树性能稍好与线性回归,但这仅是粗糙的比较,下面使用模型选择中介绍的一些方法,对线性模型进行优化。
五、模型优化
// 模型的优化
// 从图9-3可知,temp特征与atemp特征线性相关,而且从图9-2可知,atemp的贡献度较小,所以我们将过滤该特征。
val assembler_lr1 = new VectorAssembler()
.setInputCols(Array("seasonVec","yrVec","mnthVec","hrVec", "holidayVec","weekdayVec","workingdayVec","weathersitVec","temp","hum","windspeed"))
.setOutputCol("features_lr1")
// 对label标签特征进行转换,使其更接近正态分布,这里我们SQLTransformer转换器,
// 对特征label进行SQRT运行
val sqlTrans = new SQLTransformer().setStatement(
"SELECT *, SQRT(label) as label1 FROM __THIS__")
// 这里我们利用训练验证划分法对线性回归模型进行优化,对参数进行网格化,将数据集划分为训练集、验证集和测试集。
// 建立模型,预测label1的值,设置线性回归参数。
val lr1 = new LinearRegression()
.setFeaturesCol("features_lr1")
.setLabelCol("label1")
.setFitIntercept(true)
// 建立模型,预测label1的值,设置线性回归参数。
val pipeline_lr1 = new Pipeline().setStages(Array(assembler_lr1,sqlTrans,lr1))
// 建立参数网格
val paramGrid = new ParamGridBuilder()
.addGrid(lr1.elasticNetParam, Array(0.0, 0.8, 1.0))
.addGrid(lr1.regParam,Array(0.1,0.3,0.5))
.addGrid(lr1.maxIter, Array(20, 30))
.build()
// 选择(prediction, label1),计算测试误差。
val evaluator_lr1 =new RegressionEvaluator()
.setLabelCol("label1")
.setPredictionCol("prediction")
.setMetricName("rmse")
//利用交叉验证方法
val trainValidationSplit = new TrainValidationSplit()
.setEstimator(pipeline_lr1)
.setEvaluator(evaluator_lr1)
.setEstimatorParamMaps(paramGrid)
.setTrainRatio(0.8)
// 训练模型并自动选择最优参数。
val lrModel1 = trainValidationSplit.fit(trainingData_lr)
// 查看模型全部参数
lrModel1.getEstimatorParamMaps.foreach { println } //参数组合
lrModel1.getEvaluator.extractParamMap() //查看评估参数
lrModel1.getEvaluator.isLargerBetter
// 用最好的参数组合,做出预测。
val predictions_lr1 = lrModel1.transform(testData_lr)
val rmse_lr1 = evaluator_lr1.evaluate(predictions_lr1)
//rmse_lr1: Double = 3.1354674045018514
// 显示转换后特征值的前5行信息
predictions_lr1.select("features_lr1","label","label1","prediction").show(5)