达芬奇 - 构建数据查询API的框架
达芬奇 - 基于"Serverless"的数据查询API框架
- 此文背景
- 我们要解决什么样的问题?
- 系统要求
- 系统设计
- 访问控制列表及其使用
- 过滤器以及其语法
- Serverless 和 API Gateway
- Serverless 无服务器计算
- API Gateway 云网关
- Lambda 执行步骤
- REP(报表接口组件)管理
此文背景
目前,诸多企业拥有各种软件业务系统,随即产生了大量的生产数据,但是这些数据却“散落”在不同的“地方”。如何将这些数据进行统一的管理,或者进行快速地查询以便深度挖掘数据的潜力是很多开发者面临的问题。因此,根据我们在数据平台工作的一些经验,提出一个基于”云原生“的构建数据查询API的框架,来解决一些这样的问题。
我们要解决什么样的问题?
- 数据平台作为信息处理者,需要快速,有效地向用户提供相关的最新信息。
- 但是,此信息存储在许多不同的数据存储库中。今天,我们的数据存储在Redshift和Snowflake等数据仓库,S3中的数据湖,NoSQL数据库以及我们的内部会计和ERP系统中,例如Salesforce和Intacct。我们还需要通过调用合作伙伴的外部API来访问数据。
- 这些信息必须准确,尽可能最新,并易于呈现以方便消费。必须构建跨越这些不同系统的查询是一项艰巨的任务。此外,随着我们业务的发展,对新型数据查询和数据存储库的需求将继续增长。因此,我们的工程团队退后一步,问:“我们该怎么做才能减轻向用户提供有用数据所带来的开发痛苦?”这样,我们还能加快交付新类型数据报表的时间吗? “报表”一词在这里被宽松地使用。它涵盖了用户或系统可能感兴趣的任何信息(查找分散的数据或聚合数据,交易流水数据或统计数据,或历史信息数据)
- 另一个重要问题是数据安全性和隐私性。我们需要确保我们拥有适当的访问控制,以便用户只能看到被允许查看的信息。我们如何提出表达和执行这些访问控制规则的统一方法?
系统要求
我们很快意识到我们必须构建一个满足以下要求的系统:
- 允许开发人员轻松贡献和支持新的报表查询接口(API)(在部署过程中产生最小的冲突)
- 轻松添加新的数据源和数据仓库,并将数据从它们中提取并显示给用户
- 使用通用语言创建和更新对数据的访问控制
- 有一种统一的方式供用户表达查询过滤条件(无论数据是使用SQL或NoSQL的数据库)

我们构建的系统被称为“达芬奇”(DaVinci)(以纪念这位天才500周年诞辰),它是一项无所不包的服务,可实现信息检索(报表)API的创建,管理和执行。在此强调,它不是数据处理平台,因为它已经假设要检索的数据已先后由其他系统(例如ETL管道和其他数据处理应用程序)转换和管理。
系统设计
在设计达芬奇时,我们分析了数据报表API接口的“解剖”,并仔细查看了对应接口周围的元数据。有没有一种方法可以使接口的描述形式化,以便我们可以自动创建和维护接口,从而减轻开发人员的负担?答案是肯定的: 一个查询API接口始终具有以下特征:
- URL路径
- 所有可能的字段及其元数据(包括名称,类型和访问控制)的集合
- 要返回的默认字段
- 可返回的最大行数
- 访问控制(允许谁调用此接口?)
- 要返回的数据的检索逻辑(即数据获取器)
- 如果用户未指定,则应用的默认查询过滤器
于是,我们提出了JSON语法来定义报表接口的元数据,并将其称为报表接口组件(Reporting Endpoint Package: REP)。基本上看起来像这样:
{
"rep_name": "xxxx", //组件名称
"category": "xxxx", //目录名称
"display_name": "xxxxxx", //显示名称(我们将它考虑前端展示使用)
"description": "xxxxxxxx", //此接口的描述
"endpoint": "/sample-api", // URL 定义, 例如 diva-qa.marqeta.com/fraud_score
"maxrows": 2000, // 默认返回最大行数
"csv_download": false,
"default_filter": "{ \"column\" : \"xxxxx\", \"operator\" : \"xxxx\", \"value\": xxx }", // 默认的过滤器
"data_getter_type": "SQL", //数据获取的种类 SQL或NoSQL,或者API
"data_getter_data_source": "Athena",
"data_getter_template": "SELECT @columns@ FROM xxxxx @where@", //数据获取的模板
"acl_endpoint": "{\"xxxxxx\":[\"xxxxxx\"]}", //访问控制模块的接口定义
"acl_columns": "{\"acting_user_token\": [\"departments\":[\"Risk\"]}", // 访问控制的字段查询
"columns": [ // 字段定义
{
"column_name": "acting_user_token",
"column_type": "string",
"display_name": "Acting User Token",
"description": "A unique string that identifies a card holder",
"filterable": true,
"return_by_default": true,
"pii": true
},
{
"column_name": "amount",
"column_type": "float",
"display_name": "Amount",
"description": "Transaction Amount",
"filterable": true,
"return_by_default": true,
"pii": false
},
...
]
}
达芬奇的基础基于其自己的DSL之上,报表接口组件和Serverless计算(AWS Lambda)的概念。下图显示了高级架构:
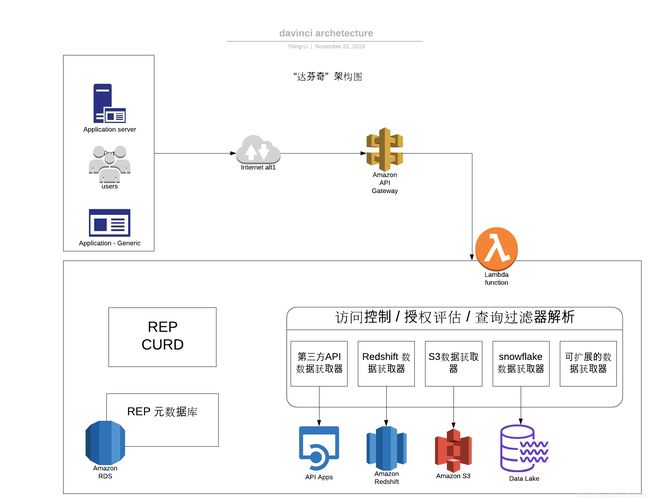
因为Marqeta所有的基础设施都基于AWS(亚马逊云计算服务),所以我们也选择“云原生”的理念来建立应用,我们主要用到的AWS 服务以及重要概念为:
- AWS API Gateway
- AWS Lambda Function
- AWS RDS (PostgreSQL)
- AWS Athena
- AWS S3
- Snowflake
- CURD
同样,我们也能在阿里云上找到上述类似的服务。比如:
- 函数计算
- 对象储存OSS
- Data Lake Analytics
访问控制列表及其使用
我们使用了单独的访问控制服务,其本身也是一个面对内部服务的API,用于管理公司内部数据系统(包括数据应用程序和API)的安全性。其提供服务包括:管理组织机构及其用户的操作,用户身份验证以及API访问令牌的管理。
具体来说,访问控制API包含的服务有如下:
- 建立组织,机构或者部门
- 获取所有组织,机构或者部门
- 获取一个特定组织,机构或者部门
- 禁用组织,机构或者部门
- 启用组织,机构或者部门
- 建一个用户和关联的配置文件(包含电子邮件,名字,姓氏,部门,角色和补充信息)
- 更新用户的个人资料
- 获取用户
- 获取组织,机构或者部门的用户
- 通过Google Oauth对用户进行身份验证
- 通过Authy对用户进行身份验证
- 为用户生成一个Zion令牌
- 撤销给定用户的Zion令牌
- 验证Zion令牌
- 获取用户令牌
通过单独的访问权限控制,我们可以严格的限制使用API的权限,以及针对不同组织机构或者用户类型返回不同的可查询字段。
过滤器以及其语法
“过滤器”的基本概念其实是需要针对每个请求执行的查询。为了扩展灵活性,我们提出了”过滤器“协议,将嵌套的JSON结构转换为SQL语法。这种灵活的过滤器允许用户按需定制查询语句。 “过滤器”的背后是一个简单的DFS,用于解析JSON对象,因此,为了使其工作,它需要开发人员定义的数个关键词。
- JSON关键字
"single" : "代表有且只有一个查询条件",
”AND/OR“:”类似于SQL逻辑运算符“,
- 条件声明
{"column": "字段名称", "operator": ">,<, !=, ==, >=, <= 运算符", "value": "在此限制条件的值"}
以下,我们举例说明过滤器的使用方法:
- 过滤器可以很简单,
SELECT 消费额 from 账单表 WHERE 消费额 > 20.00
在"过滤器"中格式为:
filter = {
"single": {"column": "消费额", "operator": ">", "value": 20.00},
}
- 或更复杂的查询条件,例如:
SELECT 测试字段1,测试字段2,测试字段3 from 测试表 WHERE (测试字段1 > 20.0 or 测试字段2 > 30.0 or ((测试字段2 > 10.0 and 测试字段3 = 'sqr') and 测试字段1 > 40.0))
在"过滤器"中格式为:
filter = {
"or": [
{"column": "测试字段1", "operator": ">", "value": 20.00},
{"column": "测试字段2", "operator": ">", "value": 30.00},
{
"and": [
{"and": [
{"column": "测试字段2", "operator": ">", "value": 10.00},
{"column": "测试字段3", "operator": "=", "value": "sqr"}
]},
{"column": "测试字段1", "operator": ">", "value": 40.00}
]
}
]
}
在我们的设计中,由于过滤器是高度可定制的,并且不绑定与某一个数据源,所以我们不直接处理查询语法的检查,而是由相应数据源(例如,MySQL)来处理它或者返回相应错误代码。
Serverless 和 API Gateway
Serverless 无服务器计算
我们构建"达芬奇"的目的是替换Marqeta旧的数据报表API系统,以使其具有可扩展性。我们决定将基础架构迁移到"Serverless"架构中,主要是因为有以下四个好处:
- 无需服务器管理,但这并不意味着没有真正的服务器在运行我们的代码,只是我们将DevOp的工作外包给了AWS,GCP等第三方云提供商
- 内置可伸缩性,Lambda 负责自动根据用量扩展应用
- 请求响应时间和速度的提升
- 代码 / 责任的细分
API Gateway 云网关
AWS API Gateway 官方文档有详细的工作原理和使用优势,能够无缝集成 Lambda
Lambda 执行步骤
因为Serverless 为事件驱动型架构,下图通过请求一个报表API的事件,举例说明了Lambda Function(a.k.a Serverless)响应的执行步骤。
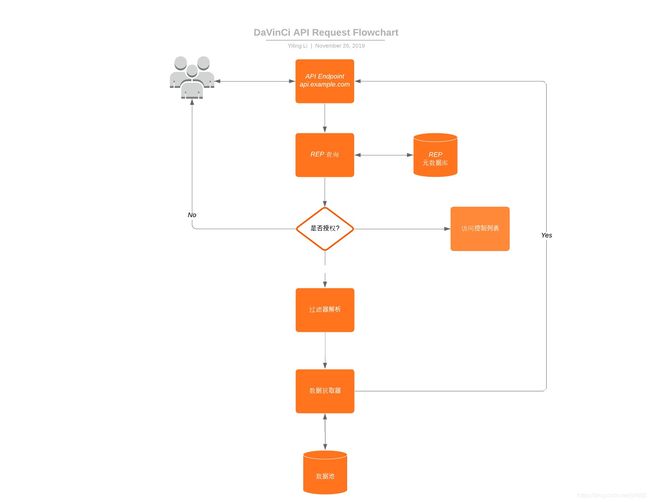
REP(报表接口组件)管理
在设计达芬奇的过程中,我们运用了Configuration as a Service的思想 - 无需更改代码即可动态更改软件系统行为的能力。这样的好处是显而易见的,之前对于一个API接口的维护和管理,通常需要完成需求确定,新增代码,审核测试,到部署这一系列为期2周左右的流程。REP 组件作为达芬奇的核心基础,我们提供了组件的全周期管理【增,删,查,改】,并且可以通过 ,以及通过API Gateway 动态增加或更改URL Path,将这取消一大部分这样的流程。