YOLOv3精度再次提高4.3%,训练提速40%!PaddleDetection全面升级

喜欢看科幻电影的朋友一定会对这样的画面印象深刻:钢铁侠去解救被恐怖分子挟持的人质时,他的战衣可以快速的从人群之中识别持有武器的恐怖分子,并确定恐怖分子的位置,然后一阵火花带闪电就问题解决了,岂是一个“帅”字可以形容!从发现敌人到发动攻击不超过5秒种,可谓战衣在手,天下我有!令科幻迷们大喊一声:“这样的战衣给我来一打!”

其实让钢铁侠战衣这样的高科技电子设备做出“看”这个动作并不难,只要有摄像头就可以了,但是要识别出图像上哪些是人、哪些是物体,这么多人中哪些是恐怖分子、哪些是人质,恐怖分子在什么位置,可就不那么简单了,也就是说不仅要通过摄像头接收图像,还要识别图像中都有哪些不同种类的元素、在什么位置等等,这就涉及到机器视觉领域的核心技术之一目标检测技术。
目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置。以图1 为例,目标检测技术可以帮助计算机检测出图像中动物的具体位置,并且识别出动物的种类是斑马。

图1 目标检测示意图
如今目标检测已经成为越来越热门的方向,它可以被广泛应用于工业产品检测、智能导航、视频监控等各个应用领域,帮助政府机关和广大企业提高工作效率,实现向科技要人力。工欲善其事,必先利其器!为了能更好的帮助用户使用目标检测技术,飞桨提供了一组强力的目标检测开发套件PaddleDetection。
01
什么是PaddleDetection
PaddleDetection是基于飞桨核心框架构建的目标检测开发套件,其整体结构如图2所示。该开发套件覆盖了主流的目标检测算法并提供丰富的预训练模型,可以帮助用户可以非常方便、快速的搭建出各种检测框架,高质量完成各类目标检测任务,

图2 PaddleDetection结构图
为了能让用户更好的使用PaddleDetection,飞桨的工程师们也在不断的精雕细琢。此次随着飞桨升级到1.7版本,PaddleDetection再次发力,性能得到了进一步提升!
升级后的PaddleDetection模型丰富度再次提高并完整开源了检测模型的压缩方案。以此前飞桨已发布的YOLOv3模型为例,该模型在之前的版本上与同期最优同类产品相比,基于COCO数据集的训练速度超出了40%,验证集精度mAP(mean Average Precision)为38.9%,超出了1%。在本次升级中,飞桨工程师本着精益求精的工匠精神,使该模型得到了进一步强化,COCO数据集mAP高达43.2%,训练速度也提升了40%,并基于YOLOv3开源了多种模型压缩完整方案,使YOLOv3更上一层楼!
那么新版本的PaddleDetection具体都有哪些闪光点呢?下面将为大家详细分解。
02
模块种类与性能全面提升
PaddleDetection采用了模块化设计,解耦了检测常用的组件,便于用户组合和扩展新的算法。经过此次升级优化,1.7版本的PaddleDetection上YOLOv3和BlazeFace性能大幅增强,新增多款IoU(Interp over Union)损失函数、以及多种强力目标检测模型,套件整体丰富度再次提升。
YOLOv3大幅增强,精度提升4.3%,训练提速40%,推理提速21%
在基于COCO数据集的测试中,骨干网络DarkNet作者在其论文中所使用的YOLOv3模型的验证精度mAP为33.0%,而飞桨在之前版本中曾经发布过基于DarkNet53的YOLOv3模型,该模型的验证精度为mAP 38.9%。飞桨又做了如下改进,使得验证精度mAP再次提高到43.2%,并且推理速度提升21%。本次升级还对数据预处理速度持续优化,使得整体训练速度提升40%。
骨干网络更换为ResNet50-VD类型。ResNet50-VD网络相比升级前的DarkNet53网络,在速度和精度上都有一定的优势,且相较于DarkNet53网络,ResNet系列更容易扩展,用户可以针对自己业务场景的特点,灵活选择ResNet18、34、101等不同网络类型作为模型的骨干网络。
引入Deformable Convolution v2(简称DCNv2,可变形卷积)替代原始卷积操作。DCNv2已经在多个视觉任务中广泛验证过其效果,在考虑到速度与精度平衡的前提条件下,本次升级的YOLOv3模型使用DCNv2替换了主干网络中stage5部分的3x3卷积。实验数据表明,使用ResNet50-VD和DCVv2后,模型精度提升了0.2%,提速约为21%。
在FPN部分增加DropBlock模块,提高了模型泛化能力。DropBlock算法相比于Dropout算法,在Drop特征的时候会集中Drop掉某一块区域,更适合应用到检测任务中来提高网络的泛化能力。

图3 Dropout和Dropblock对比图
YOLOv3作为一阶段检测网络,在定位精度上相比Faster RCNN、Cascade RCNN等网络结构有着其天然的劣势,增加IoU Loss分支,可以一定程度上提高边界框的定位精度,缩小一阶段和两阶段检测网络的差距。
使用Objects365数据集训练得到的模型作为COCO数据集上的预训练模型。Objects365数据集包含约60万张图片、365种类别,高达1000万框数,与COCO数据集相比,Objects365数据集具有5倍的图像数量、4倍的类别数量、以及10倍以上标注框数量,可以进一步提高YOLOv3预训练模型的精度。

人脸检测模型BlazeFace压缩3倍,提速122%
PaddleDetection中包含了两种轻量化的人脸检测算法,即Faceboxes和BlazeFace。其中Faceboxes提出时号称CPU上实时人脸检测器,而BlazeFace是Google Research发布的人脸检测模型,它轻巧并且性能良好,专为移动GPU推理量身定制,在嵌入式部署方面有很大的优势。
在PaddleDetection中,飞桨重新实现并优化了BlazeFace模型,同时还开源了许多变种模型,并且已经开始应用到实际业务场景中。

本次升级,飞桨针对BlazeFace模型完整开源了基于硬件延时条件的神经结构搜索方法(Neural Architecture Search,简称NAS)。其具体过程如图4所示。
(1)首先在端上硬件测试单个算子的时延,得到延时表
(2)在模型搜索过程中,Controller端和定义的搜索空间负责生成模型结构,利用延时表快速获得当前模型结构在该硬件上的总耗时(latency)。
(3)总耗时和模型的精度(accuracy)一起作为当前模型结构的得分回传给Controller端,生成下一个模型结构,开始新一轮循环。
使用硬件延时搜索的目的是为了加快搜索速度并且更容易搜索到在硬件上加速明显的模型网络。实验数据表明,搜索得到的模型结构,相比于原版模型,在FDDB评测集上的离散ROC曲线AP值(DistROC AP)几乎不变的情况下,体积仅有240KB,压缩了3.3倍。在高通骁龙855 ARMv8处理器上单线程测试加速1.22倍。
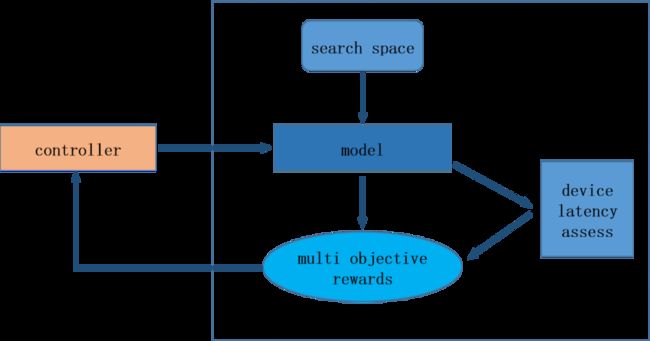
图4 BlazeFace的NAS版本硬件延时搜索过程
新增IoU损失函数,精度再提升1%,不增加预测耗时
PaddleDetection新增IoU(Interp over Union)系列损失函数及相关模型。IoU是论文中十分常用的指标,它对于物体的尺度并不敏感,在之前的检测任务中,常使用Smooth L1计算边框损失,但是该种方法计算出来的损失函数一方面无法与最终的指标直接对应,同时也对检测框的尺度较为敏感,因此有学者提出将IoU作为回归的损失函数。
本次升级的1.7版本中,PaddleDetection增加了GIoU(Generalized IoU),DIoU(Distance IoU)、CIoU(Complete IoU)损失函数,使用他们分别替换传统的Smooth L1 loss损失函数后,在使用Faster RCNN的ResNet50-vd-FPN模型和,COCO val2017数据集测评后,精度mAP分别增长1.1%、0.9%、1.3%,并且没有带来任何预测耗时的损失。
新增基于COCO数据集的精度最高开源模型CBNet,高达53.3%
新增CBNet模型,该模型是对已有的结构进行联结,生成新的骨干网络,以ResNet结构为例,级联个数为2时,称为Dual-ResNet,级联个数为3时,称为Triple-ResNet。本次新增的CBNet基础模型使用的是AHLC(Adjacent Higher Level Composition)组网方式,在论文中的几种组网联结方式中性能最好。此外除了新增基础模型外,还发布了单尺度检测模型CascadeRCNN-CBR200-vd-FPN-dcnv2-nonlocal,该模型在经过COCO val2017验证集验证后,其精度高达53.3%。
新增Libra-RCNN模型,精度提升2%
新增的Libra R-CNN模型。检测模型训练大多包含候选区域生成与选择、特征提取、类别分类和检测框回归等多个任务的训练与收敛。在两阶段目标检测任务中存在样本(sample level)、特征(feature level)以及目标级别(objective level)三个层面的不均衡现象,这些不均衡现象会限制模型的性能。LibraR-CNN模型从这三个层面分别进行了优化。最终与FasterRCNN-ResNet50vd-FPN相比,在COCO两阶段目标检测任务中,LibraR-CNN模型精度超出2%,效果十分明显。
新增Open Images V5目标检测比赛最佳单模型
本次升级开源了Open Images V5目标检测比赛中的最佳单模型,该模型是百度自研模型,并结合了当前较优的检测方法。其模型结构图如图5所示,它将ResNet200-vd作为检测模型的骨干网络,并结合了CascadeClsAware RCNN、Feature Pyramid Networks、Non-local和Deformable V2等方法。
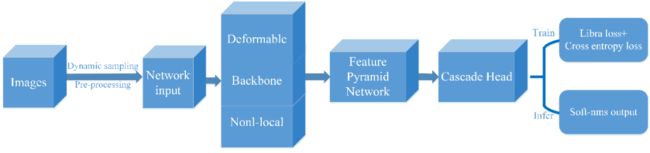
图5 Open Images V5最佳单模型结构图
训练策略方面,该模型融合了Libra Loss作为边框回归损失;针对数据集类别不均衡的现象,在训练时使用动态采样策略去选择样本;此外,由于Objects365数据集和Open Images V5数据集有大约189个类别是重复的,因此使用了Objects365数据集去扩充训练数据集。并且在测试时使用SoftNMS方法进行后处理。最终该模型单尺度测试的Public/Private Score为0.62690/0.59459,多尺度测试的结果为0.6492/0.6182。
PaddleSlim助力PaddleDetection,化学反应,势不可挡!
目标检测模型在实际部署时,由于耗时和内存占用,仍然存在很大挑战。模型压缩通常是解决速度和内存占用的有效手段。飞桨框架的压缩工具PaddleSlim提供了多种非常有效的模型压缩方法,推动PaddleDetection性能达到新高度。
使用蒸馏模型压缩方案提升验证精度2%
模型蒸馏是将复杂网络中的有用信息提取出来,迁移到一个更小的网络中去,从而达到节省计算资源的目的。通过蒸馏实验可以发现同一种蒸馏方法不一定适用所有数据集,由于Pascal VOC和COCO数据集的任务难度不同,PaddleDetection对YOLOv3模型在PascalVOC和COCO数据采用了不同的蒸馏方案,实验表明,蒸馏后的MobileNet-YOLOv3模型在Pascal VOC数据集上,验证集精度mAP 提高了2.8%,在COCO数据集上,验证集精度mAP提高了2.1%。

使用裁剪模型压缩方案大幅降低FLOPs
裁剪策略可以通过分析各卷积层的敏感度得到各卷积核的适宜裁剪率,通过裁剪卷积层通道数来减少卷积层中卷积核的数量,实现减小模型体积,降低模型计算复杂度的作用。实验表明以ResNet50vd-dcn-YOLOv3为例,在COCO数据集上FLOPS降低了8.4%,mAP提高了0.7%;MobileNet-YOLOv3在COCO数据集上FLOPS降低了28.54%,mAP提高了0.9%;在Pascal VOC数据集上FLOPs降低了69.57%,mAP提高了1.4%。
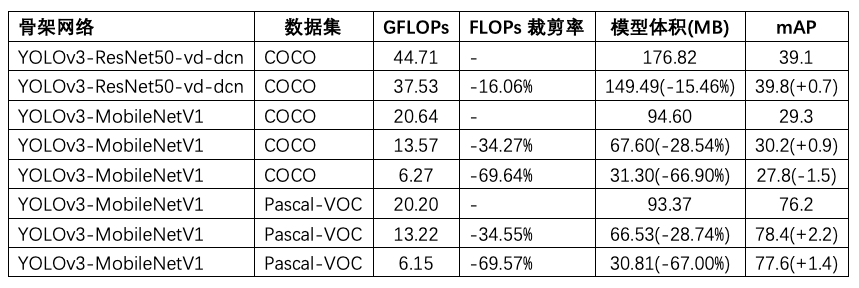
蒸馏+裁剪,基于COCO数据集的测试可以加速2.3倍
裁剪和蒸馏两种策略可以相互结合,并能够取得不错的效果。通过输入608x608图片进行测试,部分耗时测试数据如下表所示。当裁剪的FLOPs减少超过50%时,在手机上的耗时减少57%,即加速2.3倍,裁剪的模型在GPU上也有一定的收益。

03
部署流程无缝衔接
PaddleDetection为用户提供了从训练到部署的端到端流程,并提供一个跨平台的图像检测模型的C++预测部署方案。用户在训练完模型后,即可获取现成的C++预测代码,可以直接使用完成预测操作,并且仅通过一定的配置以及少量代码,就可以把模型集成到自己的服务中,完成相应的图像检测任务。预测部署方案拥有如下四大特点:
1. 跨平台。支持在 Windows和Linux 完成编译、开发和部署。
2. 可扩展性。支持用户针对新模型开发自己特殊的数据预处理等逻辑。
3. 高性能。除了飞桨自身带来的性能优势,我们还针对图像检测的特点对关键步骤进行了性能优化。
4. 支持常见的检测模型。如YOLOv3、SSD、Faster-RCNN等,用户通过少量配置即可加载模型完成常见检测任务。
04
实际应用案例
目前PaddleDetection已在武汉精测电子工业质检、创赢科技垃圾分类项目、南方电网指针类表计读数解决方案、电网巡检等多个项目中得到了实际应用,且取得了良好的效果。
以电网巡检为例,电网巡检主要是发现电网设备附近是否存在施工机械、山火、烟雾、异物等安全隐患并上报。传统电网设备巡检方式是人工和智能分析设备相结合的方式,但是人工方式存在工种缺员率高,成本大,时效性低,且多为事后报警等问题,即使发现了,也已经造成了重大损失,例如火灾或大型挖掘机触碰到高压电网,等人工发现时重大隐患已经发生了一段时间,对电网已经造成重大损失。此外,已有智能设备存在准确率不足,分析耗时长的问题。
为了解决上述问题,百度打造了电网智能巡检解决方案。该方案中使用了PaddleDetection的目标检测模型YOLOv3,并使用了YOLOv3的压缩方案进行部署,可以实现定时拍照、数据收集、智能分析、自动上报等功能。不仅可以通过AI技术弥补人力不足问题,而且可以快速准确检查电网设备附近是否存在施工机械、山火、烟雾、异物等安全隐患。通过PaddleDetection提供的模型压缩方案,YOLOv3模型整体准确率提升1.8%,硬件CPU内存占用节省近3倍,速度提升80%,报警响应速度从小时级降低至分钟级,使企业资产和业务得到安全保障。目前已完成1000台电网巡检设备的实际部署。

图6 电网巡检方案效果图
如果您加入官方QQ群,您将遇上大批志同道合的深度学习同学。官方QQ群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨PaddleDetection项目地址:
https://github.com/PaddlePaddle/PaddleDetection
飞桨核心框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
