Hadoop大数据平台搭建与环境配置
Hadoop完全分布式平台搭建:
集群机器
三台机器:一个作为master,另外两个作为slave
1。分别执行ifconfig命令获取每台机器的IP地址
2。执行
sudo vim /etc/hostname修改主机名,主机修改为master,另外两个分别修改为slave1,slave2。当然这只是为了方便,其实也可以不用修改
3。三台机器分别执行
sudo vim /etc/hosts修改host文件
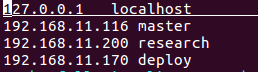
4。如果三台主机的用户名不一样,又不想修改,可以在master主机上执行
sudo vim ~/.ssh/config
Host 表示 主机名,user表示用户名
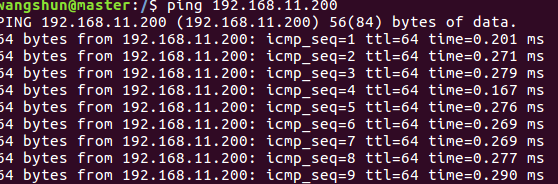
5。测试三台主机的网络连通性
从master主机上ping其他两台slave主机
ping 192.168.11.200如下表示联通
配置ssh无密码登录本机和访问集群机器
1。三台主机执行命令ssh localhost

否则执行
sudo apt-get openssh-server
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys生成公钥
2。让master主机免密码登录另外两台slave主机:在master主机上执行如下命令,将master上的id_rsa.pub文件传送给两个slave主机
scp ~/.ssh/id_rsa.pub research@192.168.11.200:/home/
scp ~/.ssh/id_rsa.pub research@192.168.11.170:/home/接着分别在两台slave主机上执行
cat /home//id_rsa.pub >> ~/.ssh/authorized_keys
rm /home/id_rsa.pub执行
ssh deploy
即可登录salve主机名为deploy的主机
JDK和Hadoop安装配置
分别在master主机和slave主机上安装JDK和Hadoop,并加入环境变量。
安装JDK
分别在master主机和slave主机上执行安装JDK的操作
执行
wget http://download.oracle.com/otn-pub/java/jdk/8u144-b01/090f390dda5b47b9b721c7dfaa008135/jdk-8u144-linux-x64.tar.gzsudo tar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/lib/jvm/编辑~/.bashrc文件,添加如下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
接着让环境变量生效,执行如下代码:
source ~/.bashrc执行:
java -version
执行:
echo $JAVA_HOME![]()
安装Hadoop
先在master主机上做安装Hadoop,暂时不需要在slave主机上安装Hadoop.稍后会把master配置好的Hadoop发送给两个slave主机
在master主机~/Downloads/目录下执行如下操作:
wget http://apache.stu.edu.tw/hadoop/common/hadoop-2.8.1/hadoop-2.8.1.tar.gz
sudo tar -zxvf ~/Downloads/hadoop-2.8.1.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.8.1/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R wangshun ./hadoop # 修改文件权限编辑~/.bashrc文件,添加如下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin接着让环境变量生效,执行如下代码:
source ~/.bashrcHadoop集群配置
修改master主机修改Hadoop如下配置文件,这些配置文件都位于/usr/local/hadoop/etc/hadoop目录下。
-
slaves
这里把DataNode的主机名写入该文件,每行一个。这里让master节点主机仅作为NameNode使用。researchdeploy -
core-site.xml
hadoop.tmp.dir file:/usr/local/hadoop/tmp Abase for other temporary directories. fs.defaultFS hdfs://master:9000 -
hdfs-site.xml
dfs.replication 3 -
mapred-site.xml(复制mapred-site.xml.template,再修改文件名)
mapreduce.framework.name yarn -
yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname master
chomd 777 ./hadoop
scp -r ./hadoop research:/usr/local/
scp -r ./hadoop deploy:/usr/local/启动hadoop集群
在master主机上执行如下命令:
cd /usr/local/hadoop
bin/hdfs namenode -format
./sbin/start-all.sh运行后,在master,slave运行jps命令,查看:
jps


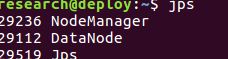
启动成功