参考自:http://www.cnblogs.com/end/archive/2012/08/13/2636645.html
Hadoop2.7.2之集群搭建(单机)
一、安装Linux操作系统
VMware+Ubuntu安装详细过程 : http://blog.csdn.net/chongxin1/article/details/68951393
ubuntu-16.04.2-desktop-amd64.iso百度网盘下载地址 : http://pan.baidu.com/s/1bOHsmi
二、在Ubuntu下创建hadoop用户组和用户
这里考虑的是以后涉及到hadoop应用时,专门用该用户操作。用户组名和用户名都设为:hadoop。可以理解为该hadoop用户是属于一个名为hadoop的用户组,这是linux操作系统的知识,如果不清楚可以查看linux相关的书籍。
Ctrl+Alt+T : 打开终端的快捷键
1、创建hadoop用户组
- sudo su //进入管理员root用户
- sudo addgroup hadoop

2、创建hadoop用户
- sudo adduser –ingroup hadoop hadoop

重新输入密码


3、给hadoop用户添加权限,打开/etc/sudoers文件
- sudo gedit /etc/sudoers

按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL

三、在Ubuntu下安装JDK
- 由于下面使用的是hadoop2.7.3,所以此处至少安装JDK1.7
- 记得先切换成hadoop用户
在Ubuntu下安装JDK图文解析 : http://blog.csdn.net/chongxin1/article/details/68957808
四、修改机器名
每当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。
1、打开/etc/hostname文件
- sudo su
- sudo gedit /etc/hostname
![]()
2、将/etc/hostname文件中的yangcx-virtual-machine改为你想取的机器名
回车后就打开/etc/hostname文件了,将/etc/hostname文件中的yangcx-virtual-machine改为你想取的机器名。这里我取“serverOne“。重启系统后才会生效。


解决:sudo: 无法解析主机:serverOne: 连接超时
- sudo gedit /etc/hosts
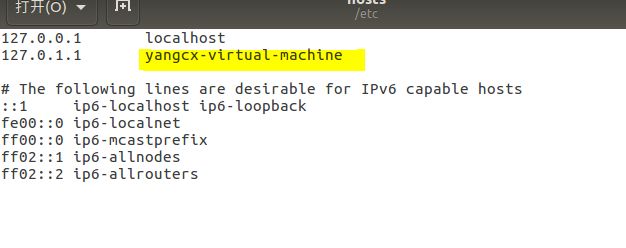
把/etc/hosts文件中的yangcx-virtual-machine修改为serverOne

为了后面在windows系统中调用linux系统的hadoop服务,所以应该把127.0.0.1修改为实际IP地址,如:192.168.168.200

五、安装ssh服务
此处采用在线安装方法,所以首先要保证Ubuntu系统能够上网。
VMware Ubuntu如何连接互联网 : http://blog.csdn.net/chongxin1/article/details/68959150
1、更新源列表
打开"终端窗口",输入"sudo apt-get update"-->回车-->"输入当前登录用户的管理员密码"-->回车,就可以了。
- sudo apt-get update

2、安装ssh
打开"终端窗口",输入"sudo apt-get install openssh-server"-->回车-->输入"y"-->回车-->安装完成。
- sudo apt-get install openssh-server


3、查看ssh服务是否启动
打开"终端窗口",输入"sudo ps -e |grep ssh"-->回车-->有sshd,说明ssh服务已经启动,如果没有启动,输入"sudo service ssh start"-->回车-->ssh服务就会启动。
- sudo ps -e |grep ssh

六、建立ssh无密码登录本机
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1、创建ssh-key,,这里我们采用rsa方式
- ssh-keygen -t rsa -P "" //(P是要大写的,后面跟"")

(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2、进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的
- cd ~/.ssh
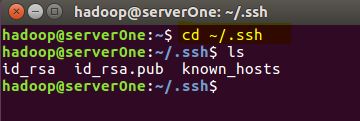
- cat id_rsa.pub >> authorized_keys
![]()
完成后就可以无密码登录本机了。
3、登录localhost
- ssh localhost

( 注:当ssh远程登录到其它机器后,现在你控制的是远程的机器,需要执行退出命令才能重新控制本地主机。)
4、执行退出命令
- exit

七、下载hadoop
hadoop百度网盘下载地址:http://pan.baidu.com/s/1pKQsHJ1
官网下载地址:http://hadoop.apache.org/
下载步骤一:
找到"Getting Started" ----->"Download Hadoop from the release page"

下载步骤二:
找到"Download the release hadoop-X.Y.Z-src.tar.gz from a mirror site

下载步骤三:

选择stable,表示是稳定的版本。
下载步骤四:


八、安装Hadoop
1、假设hadoop-2.7.3.tar.gz在桌面,将它复制到安装目录 /usr/local/下1
- sudo cp hadoop-2.7.3.tar.gz /usr/local
![]()
2、解压hadoop-2.7.3.tar.gz
- cd /usr/local/
- sudo tar -zxf hadoop-2.7.3.tar.gz
![]()
![]()

3、将解压出的文件夹改名为hadoop
- sudo mv hadoop-2.7.3 hadoop

4、将该hadoop文件夹的属主用户设为hadoop
- sudo chown -R hadoop:hadoop hadoop
![]()
5、打开hadoop/etc/hadoop/hadoop-env.sh文件
- cd hadoop/etc/hadoop
- sudo gedit hadoop-env.sh
![]()
6、配置hadoop/etc/hadoop/hadoop-env.sh(找到#export JAVA_HOME=...,去掉,然后加上本机jdk的路径)
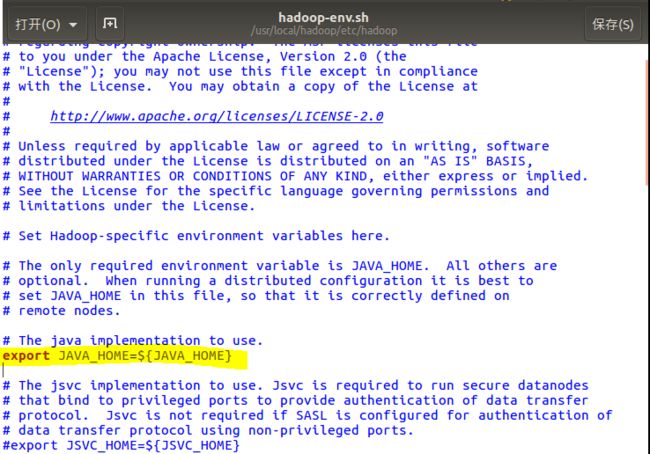
把 ${JAVA_HOME} 修改为本机JDK实际的路径

7、打开hadoop/etc/hadoop/core-site.xml文件,编辑如下:
- sudo gedit core-site.xml
![]()

-
fs.default.name -
hdfs://192.168.168.200:9000
192.168.168.200 : 本机IP地址,此处不用localhost,为了在windows能够访问
9000:默认端口

8、打开hadoop/etc/hadoop/mapred-site.xml文件,编辑如下:
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。
- //复制并重命名
- cp mapred-site.xml.template mapred-site.xml
- //编辑器打开此新建文件
- sudo gedit mapred-site.xml
![]()
![]()
-
-
mapred.job.tracker -
localhost:9001

9、打开hadoop/etc/hadoop/hdfs-site.xml文件,编辑如下:
- sudo gedit hdfs-site.xml
![]()
-
-
dfs.name.dir -
/usr/local/hadoop/namenode -
-
dfs.data.dir -
/usr/local/hadoop/datanode -
-
dfs.replication -
1

九、在单机上运行hadoop
1、格式化hdfs文件系统
进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作
- cd /usr/local/hadoop
- bin/hadoop namenode -format
![]()
当你看到下图时,就说明你的hdfs文件系统格式化成功了:
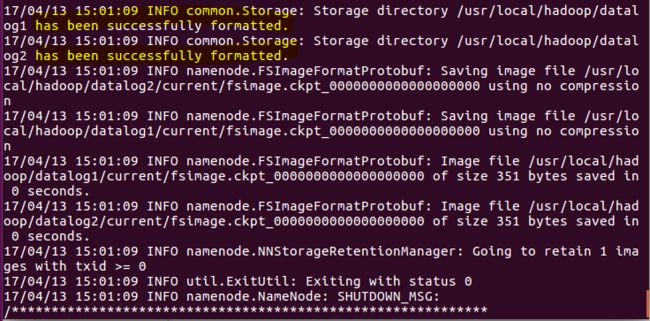
注意:由于hadoop2.7.3需要JDK1.7以上版本,JDK版本低于1.7就会报错。【java.lang.UnsupportedClassVersionError】版本不一致出错。
2、启动hdfs
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh
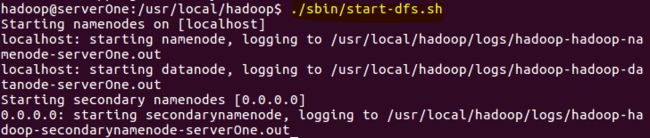
- jps
看到如下效果表示成功:
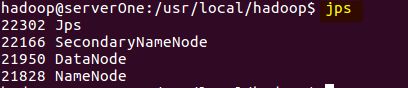
3、快捷启动配置
- //配置hadoop环境变量
- sudo gedit /etc/profile
- export HADOOP_HOME=/usr/local/hadoop
- export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
- export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

之后即可直接调用start-dfs.sh启动hadoop,无需进入hadoop的安装目录。

4、停止hdfs
- ./sbin/stop-dfs.sh
十、测试hadoop是否安装成功
1、测试用浏览器访问: http://localhost:50070 或者 http://192.168.168.200:50070
效果如下:

2、上传文件测试
创建一个words.txt 文件并上传
vi words.txt
- Hello World
- Hello Tom
- Hello Jack
- Hello Hadoop
- Bye hadoop
将words.txt上传到hdfs的根目录1
- bin/hadoop fs -put words.txt /

可以通过浏览器访问:http://192.168.168.200:50070,选择“Browse the file system”:

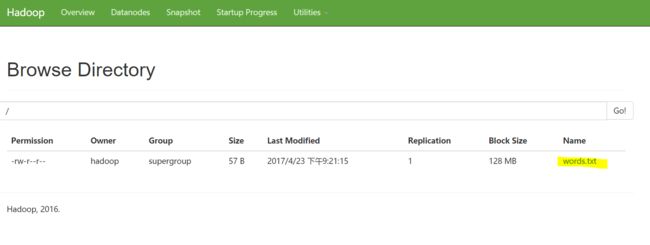
这里的words.txt就是我们上传的words.txt

3、配置启动YARN

从上图看看出我们的MapReduce是运行在YARN上的,而YARN是运行在HDFS之上的,我们已经安装了HDFS现在来配置启动YARN,然后运行一个WordCount程序。
①配置etc/hadoop/mapred-site.xml:
- mv mapred-site.xml.template mapred-site.xml
![]()
-
-
mapreduce.framework.name -
yarn
②配置etc/hadoop/yarn-site.xml:
![]()
-
-
yarn.nodemanager.aux-services -
mapreduce_shuffle
③YARN的启动与停止
- //启动
- ./sbin/start-yarn.sh

测试用浏览器访问:http://192.168.168.200:8088

- 停止
- ./sbin/stop-yarn.sh
现在我们的hdfs和yarn都运行成功了,我们开始运行一个WordCount的MP程序来测试我们的单机模式集群是否可以正常工作。
4、运行一个简单的MP程序
我们的MapperReduce将会跑在YARN上,结果将存在HDFS上:
- ./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
- wordcount hdfs://localhost:9000/words.txt hdfs://localhost:9000/out
![]()
用hadoop执行一个叫 hadoop-mapreduce-examples.jar 的 wordcount 方法,其中输入参数为 hdfs上根目录的words.txt 文件,而输出路径为 hdfs跟目录下的out目录,运行过程如下:

我们通过浏览器访问和下载查看结果:



这里下载的时候会跳转到另一个地址如下:
http://serverone:50075/webhdfs/v1/out/_SUCCESS?op=OPEN&namenoderpcaddress=localhost:9000&offset=0
1、需把serverone换成192.168.168.200
http://192.168.168.200:50075/webhdfs/v1/out/_SUCCESS?op=OPEN&namenoderpcaddress=localhost:9000&offset=0
2、需开放50075端口。
下载下来结果如下:

说明我们已经计算出了,单词出现的次数。
至此,我们Hadoop的单机模式搭建成功。
Linux下的快捷键:
Ctrl+Alt+T:弹出终端
Ctrl+空格:中英文输入法切换