Learn&Fuzz:Machine Learning for Input Fuzzing
摘要
使用基于神经网络的机器学习技术自动生成符合语法的模糊测试输入
我们讨论(并实验比对)learning和fuzz目标之间的冲突关系:learing想要捕获合语法的输入输出的结构,而fuzz想要打破这种结构,以便覆盖新路径和发现bug。
提出了一种新的learning和fuzz挑战算法,该算法使用学习的输入概率分布来智能地指导fuzz输入的什么位置。
1. 简介
分析程序输入的语法的过程费时费力,而且容易出错。
但基于语法的fuzz是目前已知的最有效的模糊化技术。
与以往的工作相比,本文首次尝试使用基于神经网络的统计学习技术来解决这一问题。具体地说,我们使用RNN来学习同样具有生成性的统计输入模型:它可以用于根据学习模型的概率分布生成新的输入。我们使用无监督学习,全自动,不需要自定义任何特定格式。
讨论了learn&fuzz的挑战:如何学习并生成各种格式良好的输入,以便最大化fuzz解析器代码覆盖率,同时仍然注入足够的格式畸形的输入,以便执行意外的代码路径和错误处理代码。
我们还提出了一种新的学习和fuzz算法,该算法使用学习的输入概率分布来智能地指导fuzz(统计良好)输入的位置。实验结果表明,该算法的性能优于其他基于学习的随机fuzz算法。
2. Object Contents的统计机器学习
用统计学习方法来学习PDF对象的生成模型。主要思想是学习一个生成语言模型,在给定一个大型对象语料库的PDF对象字符集上,使用序列到序列(seq2seq)网络模型。seq2seq模型允许学习任意长度的上下文来预测下一个字符序列,而传统的基于n-gram的方法受到有限长度上下文的限制。
2.1 Sequence-to-Sequence 神经网络模型
由两个RNN组成的序列到序列(seq2seq)模型、一个将可变维输入序列处理为固定维表示的编码器RNN和一个采用固定维输入序列表示并生成可变维输出序列的解码器RNN。
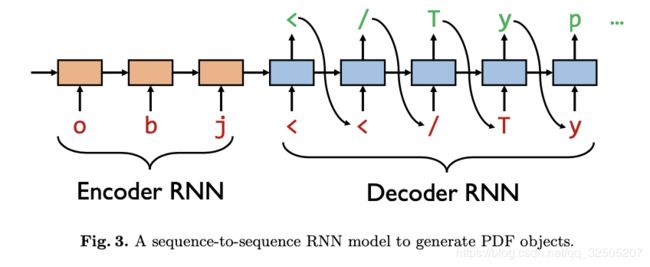
将每个pdf对象视为一个字符序列。先将所有目标文件连接成一个字符序列,再分成多个固定大小的序列训练,每个训练序列的输出序列是向后移动1个位置的输入序列,然后,seq2seq模型被end-to-end地训练,以学习所有训练实例集合上的生成模型。
2.2 生成新的PDF对象
三种不同的采样策略,用于生成新的对象实例。
- NoSample
预测给定前缀的最佳字符,下一个字符的最佳序列是唯一确定的,因此此策略会产生相同的PDF对象。这种限制使得这种策略不能用于模糊化。 - Sample
采样给定前缀序列中的下一个字符(而不是选择顶部预测字符)。该抽样策略通过将模型从训练语料库中的不同对象集合中学习到的各种模式结合起来,能够生成一组不同的新PDF对象。由于采样的原因,生成的PDF对象并不总是保证格式良好,这从模糊的角度来看是有用的。 - SampleSpace
它只在当前前缀序列以空白结尾时Sample以生成下一个字符
非空白字符结尾的前缀NoSample生成下一个字符
2.3 SampleFuzz: Sampling with Fuzzing
我们使用学习的模型生成新的PDF对象实例,但同时引入畸形数据来fuzz错误处理代码。
SampleFuzz算法如算法1所示。它将学习到的分布D(x,θ)、fuzz字符的概率tfuzz和用于决定是否修改预测字符的阈值概率pt作为输入。在生成输出序列seq时,该算法对所学习的模型进行采样,以在特定时间戳t处获得一些下一个字符c及其概率p(c)。如果概率p(c)高于用户提供的阈值pt,即如果该模型确信c可能是序列中的下一个字符,该算法选择另一个不同的字符c′来代替c′在学习分布中具有最小概率p(c′)的位置。这种修改(fuzzing)只在随机抛硬币的结果pfuzz返回高于输入参数tfuzz的概率时发生,这允许用户进一步控制fuzz字符的概率。
算法:
seq := “obj ”
while ¬ seq.endswith(“endobj”) do
c,p(c) := sample(D(seq,θ)) (* Sample c from the learnt distribution *)
pfuzz := random(0, 1) (* random variable to decide whether to fuzz *)
if pfuzz > tfuzz ∧ p(c) > pt then
c := argminc′ {p(c′) ∼ D(seq, θ)} (* replace c by c’ (with lowest likelihood) *)
end if
seq := seq + c
if len(seq) > MAXLEN then
seq := “obj ” (* Reset the sequence *)
end if
end while
return seq
SampleFuzz算法的关键直觉是只在模型高度确定的地方在对象中引入意外字符,以欺骗PDF解析器。
2.4 模型训练
本文使用LSTM模型,它有两个隐藏层,每个层由128个隐藏状态组成。
3. 实验
实验对象:Edge PDF解析器
衡量标准:
- 覆盖率
- 通过率
- bug
一个具有近乎完美通过率的纯学习算法(如SampleSpace)几乎只生成格式良好的对象,并且很少执行错误处理代码。相比之下,一种低通过率的噪声较大的学习算法(如Sample)不仅可以生成许多格式良好的对象,而且还可以生成一些格式错误的对象,从而执行错误处理代码。
覆盖率是一个比通过率更好的fuzz效果指标,而通过率则是一个学习质量指标。
4. 未来工作
未来的工作有几个有趣的方向。虽然本文的重点是学习PDF对象的结构,但值得探讨的是如何尽可能自动地学习PDF文档的高级层次结构,包括交叉引用表、对象体和在其中保持某些复杂不变量的尾部部分。或许,将逻辑推理技术与神经网络结合起来,就足以实现这一目标。另外,我们的学习算法目前对正在测试的应用程序是不可知的。我们正在考虑使用某种形式的强化学习来指导seq2seq模型的学习,并从应用程序中获得覆盖反馈,这可能会更明确地引导学习走向增加覆盖。