Spark组件的benchmark
Spark组件的benchmark
一、 Benchmark 简单介绍
基准测试(benchmark),主要指的是,实现对一类测试对象的某项性能指标进行定量的和可对比的测试。目前主要的测试点是测试负载(workload)的执行时间,传输速率,吞吐量,资源占用率等。
目前在大数据开源组件上,还没有统一的标准,尤其在spark上更是很少,目前IBM,Intel等都自己写了一些benchmark的工具,原理上是生成模拟的数据或使用真实数据,在系统上运行典型负载,进而暴露出系统的瓶颈和性能优势,完成系统评测。
(注:其中spark SQL有标准,目前有TPC-BB比较可靠,这块也有了解放在和hive组一起测的地方写)
二、 IBM的Spark-bench
这个工具是用来分析spark的性能表现,用于帮助spark系统的设计和性能优化。
自带有data_gen可以生成不同数据量的数据,
支持以下典型负载: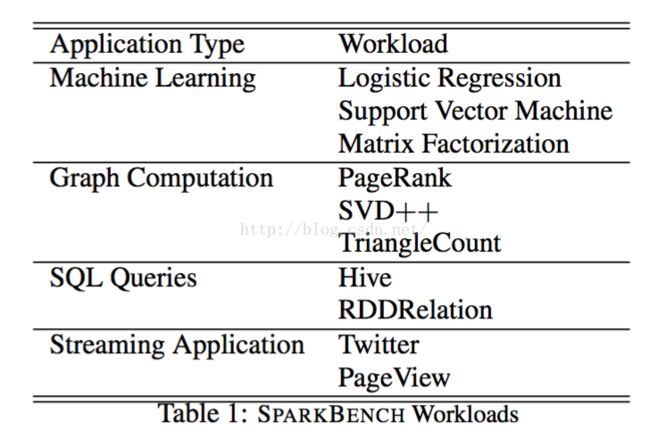
跑出来的测试报告包含以下基准点(metrics)
job execution time, input data size, dataprocess rate
使用的数据源:
目前做的测试:
现在自己的笔记本上试验了一下,环境如下:
mac OS X 10.11.6
java version"1.8.0_60"
hadoop-2.6.4
spark-1.6.0-bin-hadoop2.6
部署的都是单机模式,就一个节点。
使用的大致情况如下,
进入到想测试的负载路径下,
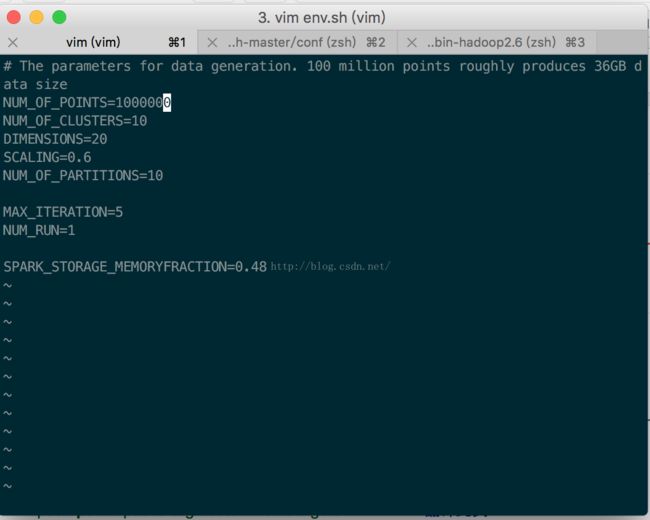
然后
`
`
会在hdfs里面生成输入文件,然后运行完会在Output路径里面输出结果。
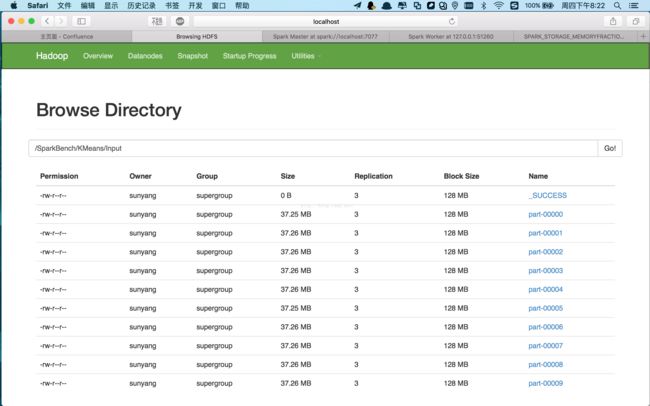
生成报告在num文件夹下的bench_report.dat,会追加到最尾部。
形如
#Apptype,start_ts,duration,size,throughput,resStatus,AppType,nExe,driverMem,exeMem,exeCore,nPoints,nClusters,nPar,nIter,memoryFraction
KMeans,2016-08-11-20:22:58,39.772000,372.570112,9.367648,0,KMeans-MLlibConfig,,,,,1000000,10,10,5,
上面逗号隔开的每一项对应下面,逗号隔开的每一项。但是有几项没有数据,正在研究中。
三、 其他性能的监测
主要是cpu,内存,磁盘i/o,网络,如下实例

这开源工具的readme写的太简陋,里面自带的了论文也是…把上面这种图放上去了,然而从头到尾没说这个数据是怎么得到的。
最后看spark的官方文档,提到用ganglia,又搜索到另一份使用说明才找到,这种监测系统性能方面的工具是另外安装的。
Spark推荐的是ganglia,监测Linux平台比较常用的还有nmon,perf等工具。
在JVM层面上有btrace,Jconsole,JVisualVM,JMap,JStack等
在spark层面上主要是web UI,持久化的历史数据等。
(注:《Spark 官方文档》监控和工具http://ifeve.com/spark-monitor/)
四、 如果使用自己的数据如何测试
基准测试的目的只是测试平台的瓶颈和性能,还可以和不同的组件性能作对比。
如果是要跑自己的数据的话,主要能测得的是在不同配置文件下,不同数据量下的:运行时间,吞吐量,cpu内存网络磁盘的数据。
可以考虑按照该文章搭建一个项目,跑一下用来测试性能。
Spark实战, 第 2 部分:使用 Kafka 和 Spark Streaming 构建实时数据处理系统
http://lib.csdn.net/article/spark/25668
接下来我主要还是研究一下spark应用程序的编写,用idea怎么开发spark程序,还有就是spark自带的监控怎么调用。