大数据实验一——Hadoop
实验步骤:
- VMWare 12安装
- CentOS7安装
- SecureCRT安装
- 打开SecureCRT连接虚拟机
- 解压并配置JDK、Hadoop
vi /etc/profile文件添加:
export JAVA_HOME=/opt/module/jdk1.8.0_121
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/module/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
Esc :wq!保存并退出
source /etc/profile配置生效
javac 、hadoop检验是否成功
5、本地模式配置hadoop -env.sh
vi /opt/module/hadoop-2.7.3/etc/hadoop/hadoop-env.sh文件修改
显示行号 Esc :set number 取消行号Esc :set nonumber
修改第25行export JAVA_HOME=/opt/module/jdk1.8.0_121
Esc :wq!保存并退出
6、配置以下文件:.core-site.xml、hdfs-site.xml,mapred-site.xml,
①.core-site.xml
②hdfs-site.xml
③mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
yarn-site.xml
格式化: hdfs namenode -format
启动: start-all.sh
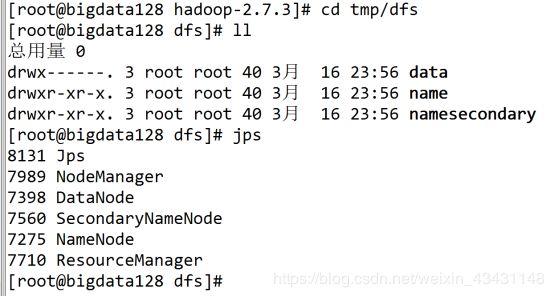
7、完全分布式配置
共3个虚拟机,前述伪分布式的bigdata128作为master,克隆另外两个虚拟机slaves:bigdata129、bigdata131,克隆机自带安装JDK、Hadoop及配置文件。
3个虚拟机都修改slaves,添加两个子节点:
vi /opt/module/hadoop-2.7.3/etc/hadoop slaves
bigdata128
bigdata129
bigdata131
3个虚拟机都修改\etc\hosts,注释已有内容,添加集群3个虚拟机的ip及对应主机名:
192.168.163.128 bigdata128
192.168.163.129 bigdata129
192.168.163.131 bigdata131
3个虚拟机各自修改\etc\hostname,添加各自的主机名bigdata128或者bigdata129或者bigdata131。
重启全部虚拟机,主机名生效。
3个虚拟机都删除\opt\module\hadoop-2.7.3\d的tmp、logs目录:
rm –rf \opt\module\hadoop-2.7.3\tmp rm –rf \opt\module\hadoop-2.7.3\logs
格式化master: hdfs namenode -format
启动master: start-all.sh

启动正常jps显示3台主机如上如下
