疯狂Hadoop之HDFS应用开发(四)
HDFS基本原理
Namenode概述
namenode是HDFS核心
namenode也称为master
namenode仅存储HDFS的元数据,文件系统中所有文件的目录树,并跟踪整个集群中的文件
namenode不存储实际数据或数据集。数据本身实际存储在datanode中
namenode知道HDFS中任何给定文件的块列表及其位置,使用此信息namenode知道如何从块中构建文件
namenode并不持久化存储每个文件中各个块所在的Datanode的位置信息,这些信息会在系统启动时从数据节点重建
namenode对于HDFS至关重要,当namenode关闭时,HDFS/Hadoop集群无法访问
namenode是hadoop集群中的单点故障
namenode所在机器通常会配置有大量内存
DataNode概述
datanode负责将实际数据存储在HDFS中
datanode也称为slave
namenode和datanode会保持不断通信
datanode启动时,它将自己发布到namenode并汇报自己负责持有的块列表
当某个datanode关闭时,它不会影响数据或集群的可用性。namenode将安排由其他datanode管理的块进行副本复制
datanode所在机器通常配置有大量的硬盘空间,因为实际数据存储在datanode中
datanode会定期向namenode发送心跳,如果namenode长时间没有接收到datanode发送的心跳,namenode就会认为该datanode失效
block汇报时间间隔取参数dfs.blockreport.intervalMsec,参数未配置的话默认为6小时
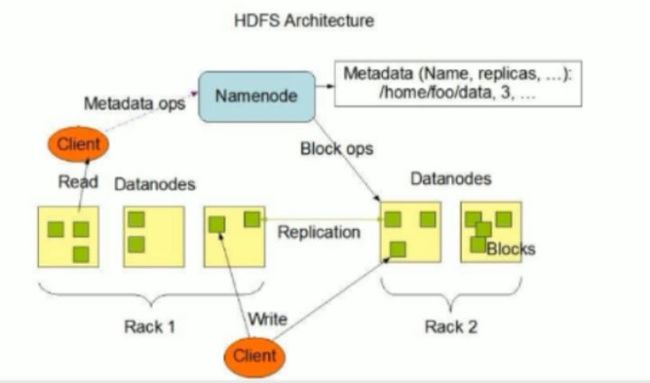
HDFS的工作机制
Namenode负责管理整个文件系统元数据,Datanode负责管理具体文件数据块存储,Secondary Namenode协助Namenode进行元数据的备份
HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向Namenode申请来进行
HDFS写数据流程
详细步骤解析
- client发起文件上传请求,通过RPC与NameNode建立通讯,NameNode检查 目标文件是否已经存在,父目录是否存在,返回是否可以上传
- client请求第一个block该传输到哪些DataNode服务器上
- NameNode根据配置文件中指定的备份数量及机架感知原理进行文件分配,返 回可用的DataNode的地址,如node01,node02,node03,node04
注意:Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点一份
- client请求3台DataNode中的一台node01上传数据(本质上是一个RPC调用, 建立pipeline),node01收到请求会继续调用node02,然后node02调用node03,, 然后node03调用node04,将整个pipeline建立完成后逐级返回client
- client开始往node01上传递第一个block(先从磁盘读取数据放到一个本地内存 缓存),以packet为单位(默认64K),node01收到一个packet就会传送给 node02,node02传给node03,node03传给node04,node01每传一个packet会 放入一个应答队列等待应答
- 数据被分割成一个个packet数据包在pipeline上一次传输,在pipeline反方向 上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节 点node01将pipeline ack发送给client
- 当一个block传输完成之后,client再次请求NameNode上传第二个block到服 务器
HDFS读数据流程
详细步骤分析
- client向NameNode发起RPC请求,来确定请求文件block所在位置。
- NameNode会视情况返回文件的部分或者全部block列表,对于每个block, NameNode都会返回含有该block副本的DataNode地址
- 这些返回的DN地址,会按照集群拓扑结构得出DataNode与客户端的距离,然 后进行排序。
排序两个规则:网络拓扑结构中距离client近的排靠前
心跳机制中超时汇报的DN状态为stale,这样的排靠后
- client选取排序靠前的DataNode来读取block,如果客户端本身就是DataNode, 那么将从本地直接获取数据
- 底层上本质是建立Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream的read方法,直到这个块上的数据读取完毕。
- 当读完列表的block后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的block列表
- 读取完一个block都会进行checksum验证,如果读取DataNode时出现错误, 客户端会通过NameNode,然后再从下一个拥有该block副本的DataNode继 续读
- read方法是并行的读取block信息,不是一块一块的读取。NameNode只是返 回client请求包含块的DataNode地址,并不是返回请求块的数据。
- 最终读取来所有的block会合并成一个完整的最终文件
HDFS的应用开发
HDFS的Java API操作
Windows下配置Hadoop环境变量
将软件中的hadoop-lib、hadoop-2.6.5、hadoop-2.6.5-src文件夹复制到C盘usr文件夹下。如
打开usr文件夹下hadoop-2.6.5文件夹,找到bin目录,将软件包中bin文件夹下的文件复制到hadoop-2.6.5文件夹下并覆盖
软件包下bin目录文件
hadoop-2.6.5下bin目录文件
合并后的bin目录
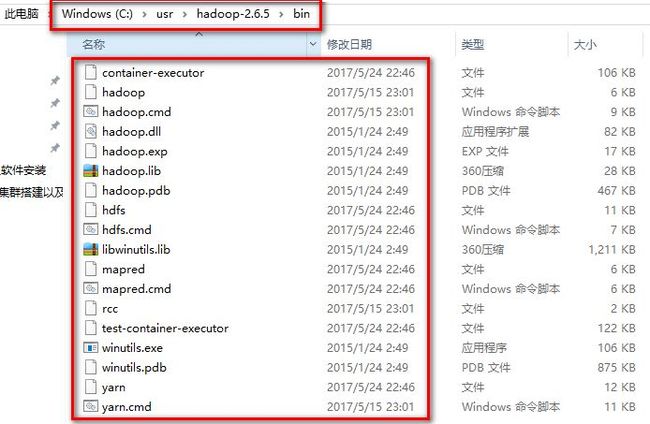
将bin合并后bin目录下的hadoop.dll文件拷贝到电脑System32文件夹下,然后重新启动电脑
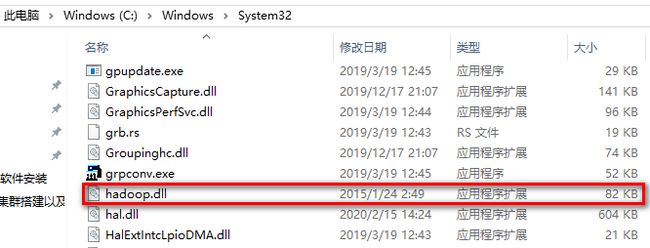
配置环境变量
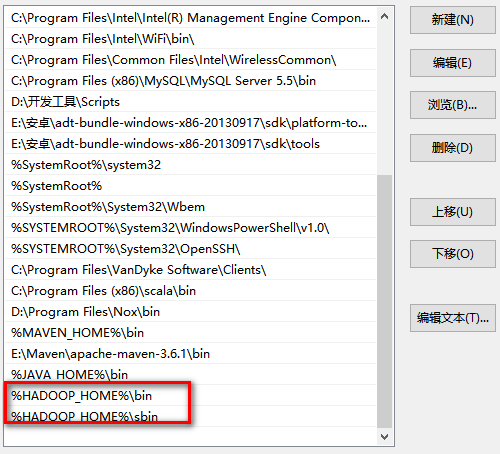
配置一个hadoop用户变量,用于指定hadoop用户名称
安装JDK
注意:JDK安装路径中不要出现空格,如果出现空格,后期配置Hadoop需要修改Hadoop中hadoop-env.cmd文件中的引用路径
如:JDK安装路径在C:\Program Files\Java\jdk1.8.0_161,因为Program Files两个单词中间存在空格,所以需要修改hadoop-env.cmd中引用路径
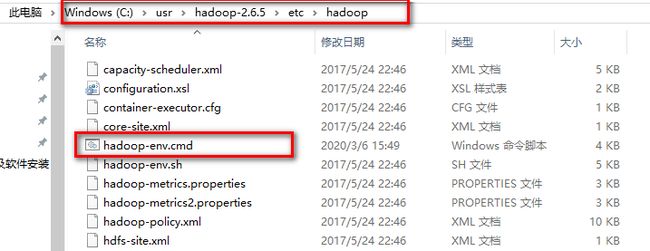
找到以上文件,打开hadoop-env.cmd,修改文件中JDK引用路径
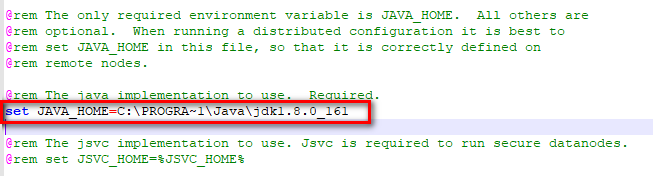
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_161
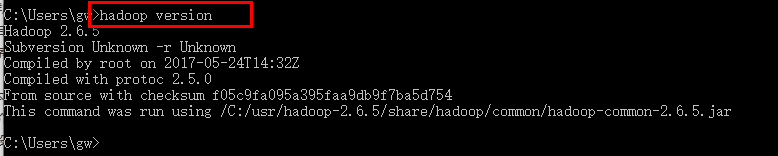
配置完成打开windows中的命令提示符,输入hadoop version,出现如下界面表示hadoop环境配置成功
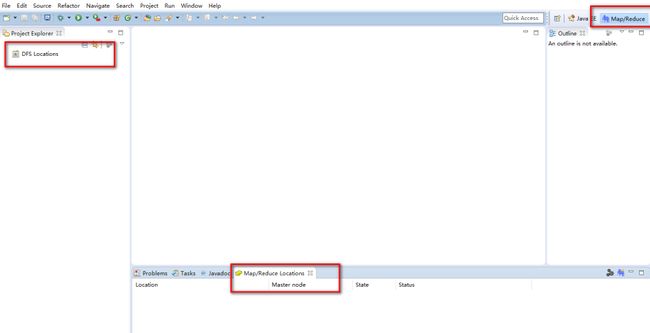
打开配置好的eclipse找到如下界面功能
在eclipse中配置hadoop环境
选择windows----preferences
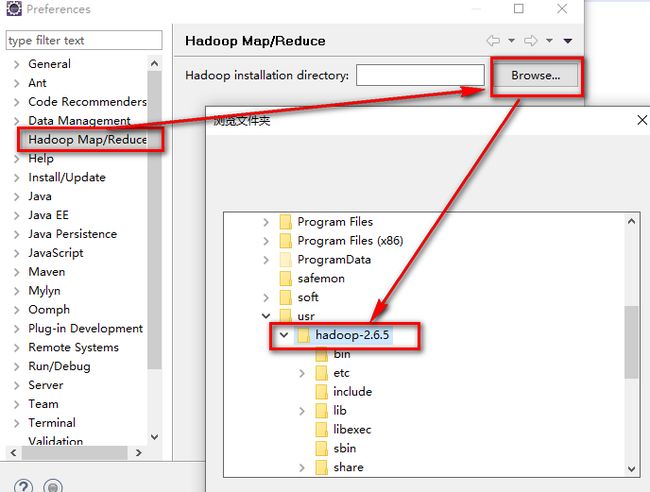
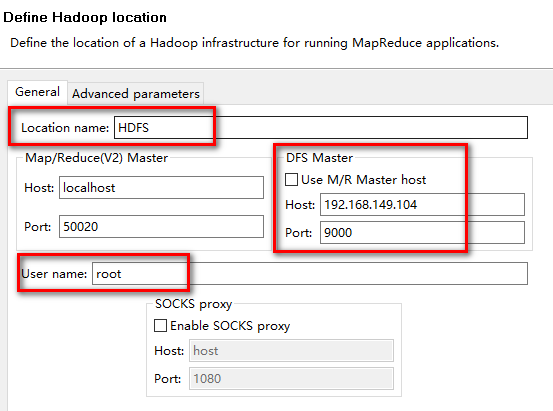
在eclipse中新建一个hadoop location

选中Location右键-----New hadoop location
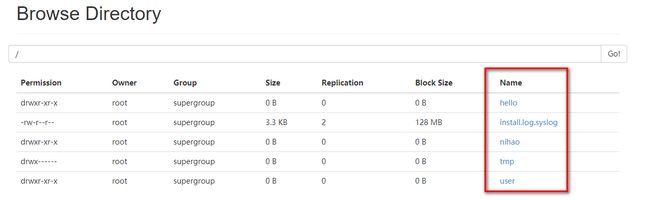
当连接成功之后,会在项目中展示HDFS中已有的文件信息
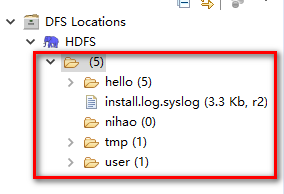
通过eclipse创建一个目录
选中主文件夹右键-----create new driectory----输入目录名称gw
刷新之后,会多出一个gw目录
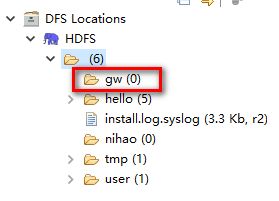
刷新页面,也会显示gw目录
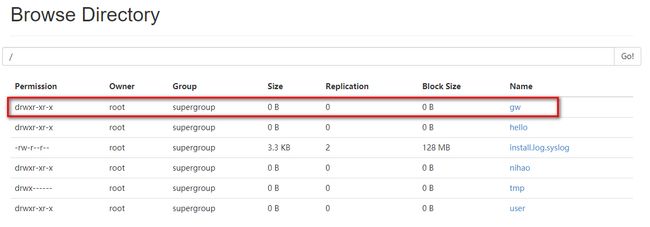
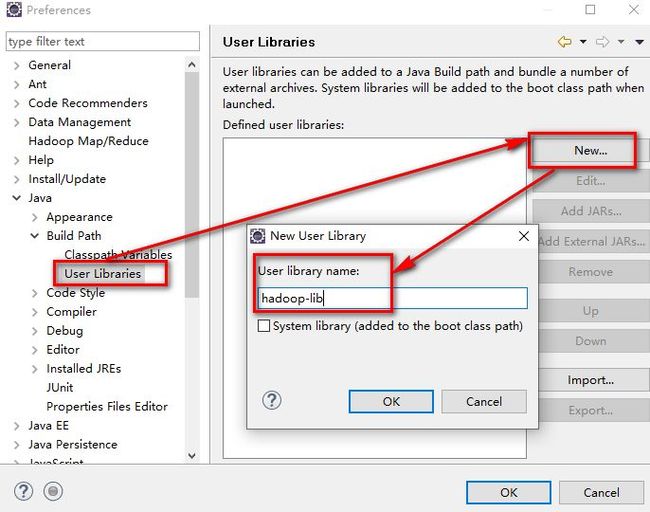
将hadoop-lib中jar包引入到eclipse中
点击windows---preferences
选中hadoop-lib,点击Add External JARs,找到jar包所在的位置,全选----打开
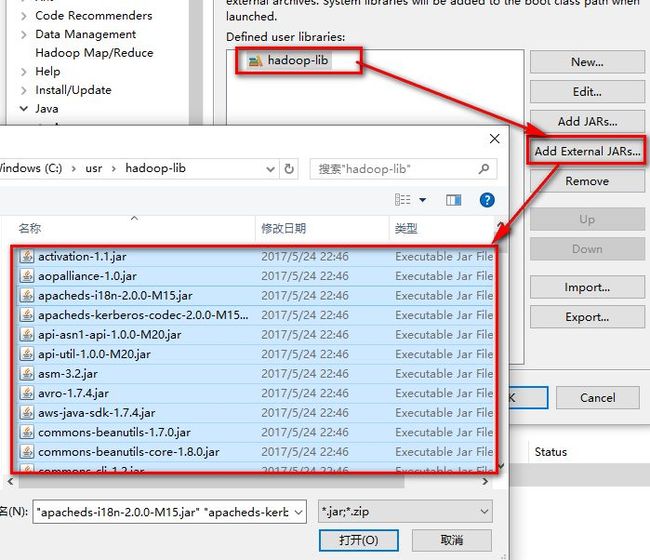
点击OK,完成jar包的引入
在项目中导入jar包
选中项目右键----build path-----Configure build path
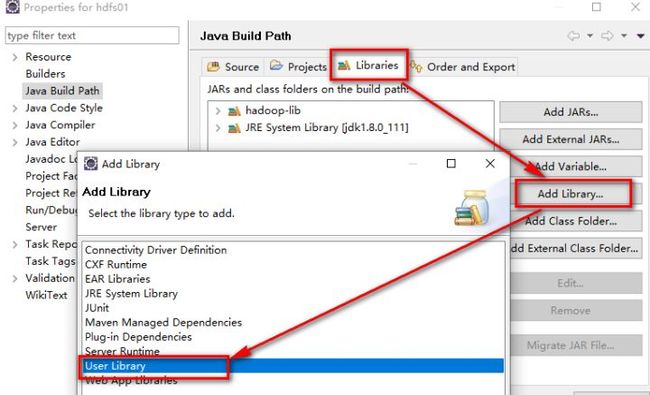
点击next,勾选上hadoop-lib-----OK----finish,此时,jar包添加完成
接下来需要指明hadoop的service在什么地方?Namenode在什么地方?
通过配置文件方式获取
在项目中新建一个文件夹confg,在confg在新建一个hadoop文件夹,然后将hadoop中core-site.xml文件与hdfs-site.xml文件传输到windows界面,然后将两个文件拷贝到项目的hadoop文件中
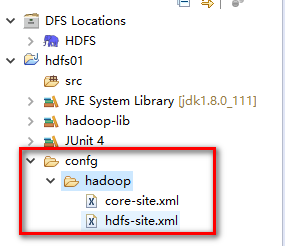
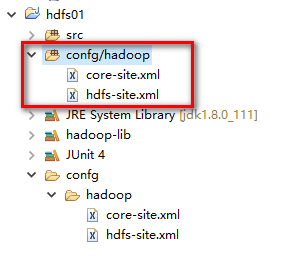
两个文件需要编译,所以需要指明配置文件的位置
选中hadoop文件夹右键------build path -------Use as Source Floder
编写JAVA程序
在java中操作HDFS,主要涉及一下Class
Configuration:该类的对象封装了客户端或者服务器配置
FileSystem:该对象是一个文件系统对象,可以用该对象的一些方法来对文件系统进 行操作,通过FileSystem的静态方法get获取该对象
FileSystem fs = FileSystem.get(conf);
get方法从conf中的一个参数fs.defaultFS的配置值判断具体是什么类型的文件系统。如果代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象。
案例1:通过java代码在HDFS中创建一个文件夹
测试HDFS程序,在src下新建一个TestHDFS.java文件,在该文件中编写代码
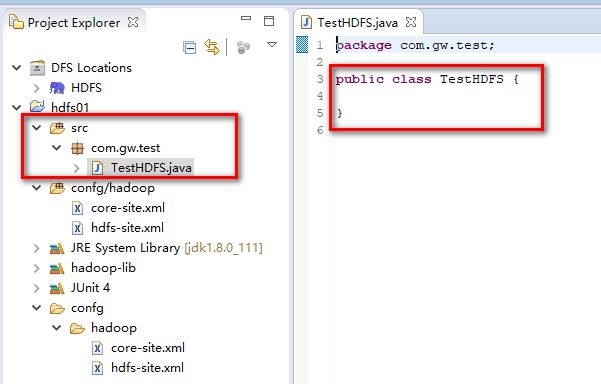
在文件中编写如下代码
public class TestHDFS {
/**
* 创建连接,使用hadoop提供的一个类Configuration
* 该类在org.apache.hadoop.conf包下
*/
Configuration conf;
/**
* 利用hadoop提供的FileSystem获取客户端配置文件信息
* 该类在org.apache.hadoop.fs包下
*/
FileSystem fs;
@Before
public void conn() throws IOException{
conf = new Configuration(true);
//获取客户端配置文件信息
fs = FileSystem.get(conf);
}
/**
* 关闭连接的方法
* @throws IOException
*/
@After
public void close() throws IOException{
fs.close();
}
@Test
public void mkdir() throws IOException{
//指定创建的目录
Path path = new Path("/first");
//判断目录是否存在
if(fs.exists(path)){
//如果目录存在,就递归删除目录
fs.delete(path, true);
}else{
fs.mkdirs(path);
}
}
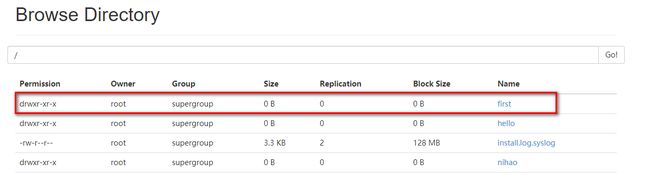
}测试运行结果:在HDFS中会多出一个文件夹,名称为First
删除文件夹
@Test
public void download() throws IllegalArgumentException, IOException{
//如果文件夹为非空,那么参数2必须是true
fs.delete(new Path("/hello"), true);
}重命名文件或文件夹
@Test
public void download() throws IllegalArgumentException, IOException{
fs.rename(new Path("/first"),new Path("/second"));
}
案例2:通过java代码向HDFS中上传文件
在测试类中编写一个通过Stream流形式上传文件的方法
public class TestHDFS {
/**
* 创建连接,使用hadoop提供的一个类Configuration
* 该类在org.apache.hadoop.conf包下
*/
Configuration conf;
/**
* 利用hadoop提供的FileSystem获取客户端配置文件信息
* 该类在org.apache.hadoop.fs包下
*/
FileSystem fs;
@Before
public void conn() throws IOException{
conf = new Configuration(true);
//获取客户端配置文件信息
fs = FileSystem.get(conf);
}
/**
* 关闭连接的方法
* @throws IOException
*/
@After
public void close() throws IOException{
fs.close();
}
/**
* 向HDFS目录上传文件的方法
* @throws IOException
*/
@Test
public void upload() throws IOException{
//设置上传路径以及上传文件名称
Path file = new Path("/first/hello.txt");
//定义文件上传的路径
FSDataOutputStream output = fs.create(file);
//指明需要上传的文件路径
InputStream input = new BufferedInputStream(new FileInputStream(new File("C:\\hdfs-site.xml")));
//开始文件上传
IOUtils.copyBytes(input, output, conf,true);
}
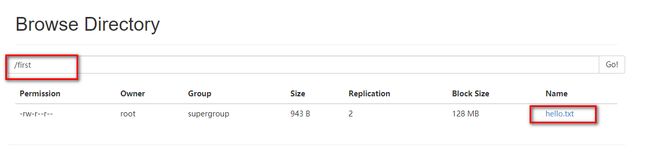
}测试结果:
方式二:
package hdfsFirst;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class TestHDFS {
/**
* 创建连接,使用hadoop提供的一个类Configuration
* 该类在org.apache.hadoop.conf包下
*/
Configuration conf;
/**
* 利用hadoop提供的FileSystem获取客户端配置文件信息
* 该类在org.apache.hadoop.fs包下
*/
FileSystem fs;
@Before
public void conn() throws IOException{
conf = new Configuration(true);
//获取客户端配置文件信息
fs = FileSystem.get(conf);
}
/**
* 关闭连接的方法
* @throws IOException
*/
@After
public void close() throws IOException{
fs.close();
}
/**
* 下载HDFS中的文件
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void download() throws IllegalArgumentException, IOException{
//从HDFS中下载文件
fs.copyFromLocalFile(new Path("e:/install.log.syslog"), new Path("/first"));
}
}
案例3:从HDFS中下载文件
package hdfsFirst;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class TestHDFS {
/**
* 创建连接,使用hadoop提供的一个类Configuration
* 该类在org.apache.hadoop.conf包下
*/
Configuration conf;
/**
* 利用hadoop提供的FileSystem获取客户端配置文件信息
* 该类在org.apache.hadoop.fs包下
*/
FileSystem fs;
@Before
public void conn() throws IOException{
conf = new Configuration(true);
//获取客户端配置文件信息
fs = FileSystem.get(conf);
}
/**
* 关闭连接的方法
* @throws IOException
*/
@After
public void close() throws IOException{
fs.close();
}
/**
* 下载HDFS中的文件
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void download() throws IllegalArgumentException, IOException{
//从HDFS中下载文件
fs.copyToLocalFile(new Path("/install.log.syslog"), new Path("e://"));
}
}
案例4:获取HDFS中文件存储块信息
package hdfsFirst;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class TestHDFS {
/**
* 创建连接,使用hadoop提供的一个类Configuration
* 该类在org.apache.hadoop.conf包下
*/
Configuration conf;
/**
* 利用hadoop提供的FileSystem获取客户端配置文件信息
* 该类在org.apache.hadoop.fs包下
*/
FileSystem fs;
@Before
public void conn() throws IOException{
conf = new Configuration(true);
//获取客户端配置文件信息
fs = FileSystem.get(conf);
}
/**
* 关闭连接的方法
* @throws IOException
*/
@After
public void close() throws IOException{
fs.close();
}
/**
* 读取HDFS中文件存储的块信息
* @throws IOException
*/
@Test
public void blks() throws IOException{
//指明需要获取信息的文件路径以及名称
Path f = new Path("/install.log.syslog");
FileStatus file = fs.getFileStatus(f);
//读取文件存储的块信息
BlockLocation[] blks = fs.getFileBlockLocations(file, 0, file.getLen());
for (BlockLocation b : blks) {
System.out.println(b);
}
}
}代码效果:

案例5:查看HDFS中的目录信息
@Test
public void download() throws IllegalArgumentException, IOException{
//遍历second目录中文件信息
RemoteIterator listFiles = fs.listFiles(new Path("/second"), true);
//遍历集合
while(listFiles.hasNext()){
LocatedFileStatus fileStatus = listFiles.next();
//获取文件名称
System.out.println(fileStatus.getPath().getName());
//获取文件块大小
System.out.println(fileStatus.getBlockSize());
//获取文件的权限信息
System.out.println(fileStatus.getPermission());
//获取文件的长度
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocation = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocation) {
//获取分块数据大小信息以及块的下标信息
System.out.println("block-length:"+bl.getLength()+"-- block-offset:"+bl.getOffset());
//获取数据备份信息
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
}
}
添加判断,判断遍历的数据是文件夹还是文件,如果是文件夹在名称前加d--,如果是文件在名称前加f--
public void download() throws IllegalArgumentException, IOException{
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "";
for (FileStatus fstatus : listStatus) {
if(fstatus.isFile()){
flag = "f--";
}else{
flag = "d--";
}
System.out.println(flag+fstatus.getPath().getName());
System.out.println(fstatus.getPermission());
}
}