基于Kmeans聚类的航空公司会员客户价值分析
1.导入相关的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入数据
# 导入航空公司会员客户数据
df = pd.read_csv(r"C:\Python\基于数据挖掘技术的航空公司会员客户价值研究报告\air_data.csv")
df
# 导入字段说明数据
df_field = pd.read_excel(r"C:\Python\基于数据挖掘技术的航空公司会员客户价值研究报告\数据特征说明.xlsx")
df_field
# 更改列名为中文名
dfc = df.copy()
dfc.columns = df_field['属性名称']
dfc
3、选择模型指标
# 这里使用以下指标作为RFM模型指标:其中金额指标拆分为两部分,分别是平均折扣率和飞行公里数,平均折扣率越高,说明打折幅度越少
# 说明这是价格不敏感的客户,而飞行公里也在一定程度上能够衡量机票的金额,飞行公里数越大越好。
# R:最近一次飞行间隔:LAST_TO_END
# F:飞行频率:FLIGH_COUNT
# D:折扣率:avg_discount
# K:飞行公里:SEG_KM_SUM
# 选择模型指标
df_rfm = dfc.loc[:,['最后一次乘机时间至观察窗口末端时长','飞行次数','平均折扣率','观测窗口总飞行公里数']]
df_rfm.columns = ['R','F','D','K']
df_rfm
3.1、缺失值处理
# 观察特征缺失值比例
df_rfm.isnull().sum()
3.2、异常值处理
# 因为KMeans是基于距离计算的聚类模型,因此离群点会对建模产生影响,所以要对异常值做处理
df_rfm.describe()
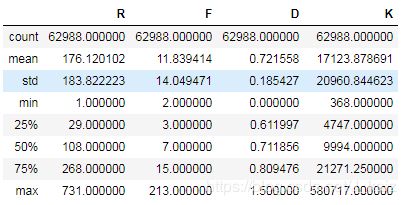
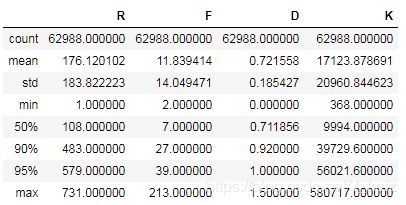
# 由下表可知,F值的最大值是0.95分位数的五倍,K值的最大值也是0.95分位数的5倍,属于异常值
df_rfm.describe([0.9,0.95])
# 使用95分位数盖帽法来处理异常值
F_095 = df_rfm['F'].quantile(0.95)
df_rfm['F'] = df_rfm['F'].mask(df_rfm['F'] > F_095, F_095)
K_095 = df_rfm['K'].quantile(0.95)
df_rfm['K'] = df_rfm['K'].mask(df_rfm['K'] > K_095, K_095)
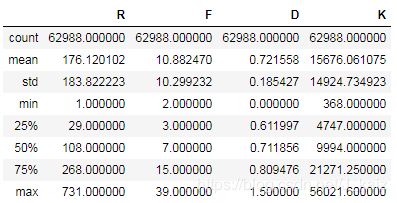
# 再次观察
df_rfm.describe()
3.3、 数据预处理
# 因为RFM数值的量纲不统一,因此会对模型造成较大的影响,在此需要对其进行数据标准化处理
# 采用了Z-score方法
df_rfm = (df_rfm - df_rfm.mean())/df_rfm.std()
df_rfm
4、数据建模
4.1 选择最优聚类
# 尝试用聚类模型进行分类
from sklearn.cluster import KMeans
# 基于SSE选择最优聚类
SSE = []
nums = []
for num in range(2,9):
KM = KMeans(n_clusters=num, random_state=0)
KM = KM.fit(df_rfm)
SSE.append(KM.inertia_)
nums.append(num)
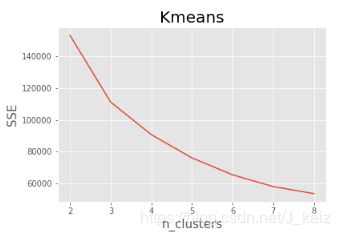
# 绘图
plt.style.use('ggplot')
# 观察绘制SSE与簇个数的关系图
plt.plot(figsize = (10,8))
plt.plot(nums, SSE)
plt.xlabel('n_clusters', fontsize=15)
plt.ylabel('SSE', fontsize=15)
plt.title('Kmeans', fontsize=20)
plt.show()
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
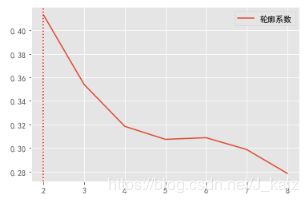
# 基于轮廓系数选择最优聚类
# 绘制轮廓系数曲线,找到最合适的k值
score = []
for i in range(2,9):
KM = KMeans(n_clusters=i, random_state=0)
KM = KM.fit(df_rfm)
score.append(silhouette_score(df_rfm, KM.labels_))
plt.rcParams['font.sans-serif']=['Simhei'] # 显示中文,解决图中无法显示中文的问题
plt.rcParams['axes.unicode_minus']=False # 设置显示中文后,负号显示受影响。解决坐标轴上付好乱码问题
plt.plot(range(2,9), score, label='轮廓系数')
plt.axvline(pd.DataFrame(score).idxmax()[0]+2, ls=':', c='r')
plt.legend()
plt.show()
4.2 确定聚类个数,开始建模
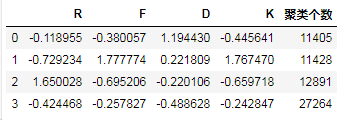
# 根据interia_拐点法最优的结果是分成3类,而根据轮廓系数最优分类是2类,但这都只能作为参考,根据业务标准,应该将其分成4类。
KM = KMeans(n_clusters=4, random_state=0)
KM = KM.fit(df_rfm)
# 统计频数
r1 = pd.Series(KM.labels_).value_counts()
# 将n个簇类中心转换成DataFrame格式
r2 = pd.DataFrame(KM.cluster_centers_)
# 将两组数据合并
center = pd.concat([r2,r1], axis=1)
center.columns = ['R','F','D','K','聚类个数']
center
5、聚类可视化
# 显示中文字体
plt.style.use('seaborn')
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制雷达图
# 所有簇中心坐标值中最大值和最小值,确定雷达图的范围
center_max = r2.values.max()
center_min = r2.values.min()
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, polar=True)
center_num = center.values
feature = list(df_rfm.columns)
N = len(feature)
for i,v in enumerate(center_num):
# 设置雷达图的角度,用于平分切开一个圆面
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
# 为了使雷达图一圈封闭,需要以下步骤
heart = np.concatenate((v[:-1], [v[0]]))
angles = np.concatenate((angles, [angles[0]]))
# 绘制折线图
ax.plot(angles, heart, 'o-', linewidth=2, label='第%d类人群,%d人' % (i+1, v[-1]))
# 填充颜色
ax.fill(angles, heart, alpha=0.25)
# 添加每个特征的标签
ax.set_thetagrids(angles * 180 / np.pi, feature, fontsize=15)
# 设置雷达图的范围
ax.set_ylim(center_min-0.1, center_max+0.1)
# 添加标题
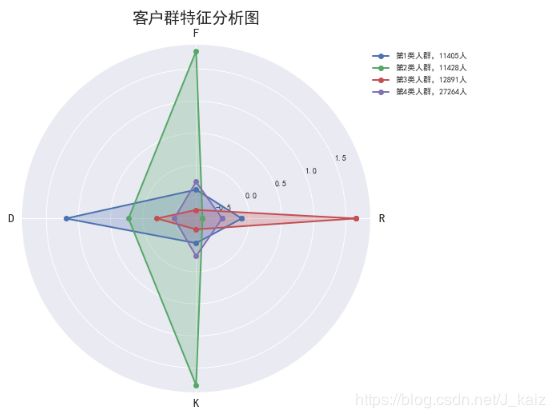
plt.title('客户群特征分析图', fontsize=20)
# 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3,1.0), ncol=1, fancybox=True, shadow=True)
# 显示图形
plt.show()
6、结论
(1)客户群1(蓝色):最后一次飞行距离当前时间短,飞行次数少,飞行里程少,平均折扣率最高
建议:客户群1属于重要发展客户,客户平均折扣率最高,一般所乘坐航班的舱位等级较高,最后一次飞行距离当前时间短,有一定的活跃度,但是飞行次数不多,飞行里程少,这类客户当前价值不高,但是很有发展潜力,应该促使该类客户在本公司消费,通过提升客户价值,加强满意度,促使其成为忠诚客户。
(2)客户群2(绿色):最后一次飞行距离当前时间最短,飞行次数多,飞行里程多,平均折扣率居中
建议:客户群2属于一般价值用户,平均折扣率居中,他们会倾向于购买打折机票,但是飞行次数多,飞行时间长,这里客户是价格敏感性用户,不太能通过刺激消费的方法升级客户价值,需要采取一定的营销手段保持该类客户的活跃度。
(3)客户群3(红色):最后一次飞行距离当前时间最长,飞行次数少,飞行里程少,平均折扣率居低
建议:客户群3属于一般挽留客户,是低价值用户,各项属性都很差,可能已经流失了,不需要在他们身上花费太多的营销成本和精力。
(4)客户群4(紫色):最后一次飞行距离当前时间最短,飞行次数少,飞行里程少,平均折扣率居低
建议:客户群4属于一般发展客户,比较符合一般新客户的特征,他们最近一次乘坐飞机的时间短,但是飞行次数少,飞行旅程少,而且倾向于购买打折机票,属于价值敏感型的客户,应该给予一定的优惠措施,将其发展为一般价值客户。