4.3.4.集成学习(一) - 袋装法(Bagging),提升法(Boosting),随机森林(Random Forest)
简介
集成学习(Ensemble Learning)是通过聚合多个分类器的预测结果来提高分类的准确率。比如,在集成学习中,会生成多个分类树模型,从中选取表现较好的那些树模型,在通过投票等筛选方式决定最终输出的分类器。在聚合算法中,以Bagging,Boosting与Random Forest(随机森林)最为典型。这三个算法,因为能够显著改善决策树的缺陷而被广泛应用。
一句话解释版本:
Bagging是决策树的改进版本,通过拟合很多决策树来实现降低Variance。
Random Forrest是Bagging的改进版本,通过限制节点可选特征范围优化Bagging。
Boosting是Bagging的改进版本,通过吸取之前树的经验建立后续树优化Bagging。
数据分析与挖掘体系位置
集成学习是数据建模中的一种,虽然集成学习大多是决策树的优化,但是它建立的模型数量庞大,因此我并没有将其归类于有监督学习中,而是另外建立一个分支。

Bagging
Bagging的目的
决策树的缺点在于High Variance,也就是说,我们将样本一分为二,用两个子样本分别拟合模型,得到的结果很可能不一样。而Bagging,又称Bootstrap Aggregation,就是为了降低分类器的Variance。
这就是说,应用了Bagging后,不同样本子集产出的分类器结果将会更相似。
Bagging的基本理念
Bagging的基本理念是:求平均值会降低Variance。
想要降低模型的Variance,并提高准确率的方法就是,从样本总体中抽取很多个训练集(Training Set),对每个训练集分别拟合模型。将每个模型的结果求平均(Average)。
因此,Bagging的方法就是:
- 通过Bootstrap的方法,从一个Training Set中反复提取出多个样本集,假设样本集数量为B。
- 用这B个样本分别拟合出B个预测性模型
- 将B个模型的结果取平均值,得到Bagging的预测结果。
其公式表达为:
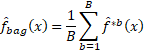
对于回归树而言,Bagging的结果就是B个没有经过Prune(剪枝)树的结果平均值。
对于分类树而言,我们通过Majority Vote,多数投票制,计算大多数模型认为结果应当属于哪一类,Bagging认为多数的结果是最终的分类结果。
Bagging的优缺点
Bagging提高了模型的准确率,降低了模型的Variance。
但是,由于模型在最后用了平均值,因此Bagging结果的可解释性降低了。
Random Forest(随机森林)
Random Forest的目的
随机森林是Bagging的改进版本,它在Bagging的基础上做出了一个小调整,使得各个树之间的相关性降低了(decorrelate trees)。
Random Forest的基本理念
随机森林的理念是,在建立随机森林时,在每个树的分支点,大部分可用的特征值是不能被考虑的。
在Bagging中,由于对每个Split的选择范围没有限定,会使得某几个特别重要的特征每次都会别优先选中,所以Bagged Trees产出的结果都会是很类似的,也就是说,Bagged Trees的结果是高相关度的。将这些高相关度的树取个平均值并不能减少太多variance。所以Bagging的结果也不能比决策树好出多少。
随机森林解决了这一问题,因为它迫使模型每次只能考虑一部分的特征值。所以,这就让其他相对没那么重要的特征值有了出场的机会。这个过程叫做decorrelates tree。
这也是随机森林区别于Bagging的地方,每个分支点上,Bagging能够考虑所有m=p个特征,而Random Forest只能考虑m=sqrt(p)个特征。如果random forest的m取成p,那么它与Bagging是相同的。
Boosting
Boosting的目的
Boosting同样是Bagging的改进版本。它与Bagging的不同在于:树的推导是有序的,每个树的生成都借鉴了之前树的经验。Boosting方法不采用Boostrap的取样方法,每个树用的都是修正后的原始数据集(Original Dataset)。
Boosting的基本理念
在Boosting中,有如下参数需要考虑:
(1)B:树的数量。要生成多少棵树。
(2)d:每个树中的分支(split)数。它掌握每棵树的复杂度,若d=1,则树只有一个节点。
(3)λ:Shrinkage parameter,压缩参数。一个非常小的正数。它掌握着Boosting学习的速率。代表着每个树的作用大小。一般可以设定为0.01或0.001.一个非常小的λ代表每个树的作用很小,所以需要非常大的B,非常多的树去得到优秀的结果。
Boosting方法通过以上的步骤,以很慢的学习方式拟合模型。Boosting将残差引入拟合模型的过程中,它在模型表现的不太好的地方慢慢的去优化它。也就是说,Boosting先拟合出一个原始的模型,之后的模型希望能够一点点的优化原始模型中的Residual。在拟合过程中,每个树的权重,即发挥效用的大小就是shrinkage parameter。
Boosting的学习方法是有时间循序(Sequential)的,在T时刻生成的树的Residual,会在T+1时刻生成的树中被改善优化。
因此,Boosting是与原始模型息息相关的。同时,这种学习方法一般训练成本较高,学习结果比较慢。
AdaBoosting
在AdaBoost初始化时,对每个训练的样本给出相等的权重。之后对每个样本进行模型的拟合。每一次训练后,对之前失败的训练样本集给予较大的权重。所以,之后的训练会更加侧重之前失败的样本集。最后,得到的模型按照预测效果给出权重,最终回归或者分类的结果会按照加权平均,或者加权投票结果给出判别。
Gradient Boosting(GBM)
Gradient Boosting是Boosting的一种实现方法,在Boosting中,GBM定义了损失函数(Loss Function)的概念。GMB主要的理念在于,后建立的模型是在之前建立模型的梯度下降方向的。损失函数就是模型的误差程度,损失函数越大,模型越容易出错。如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其梯度(Gradient)的方向下降。
Ensemble方法在Python上的实现
这些方法都是用的scikit-learn包实现的。没有编程,只有调参。谢谢!
################## Bagging ##############
from sklearn.datasets import make_blobs
from sklearn.ensemble import BaggingClassifier
import matplotlib as plt
X, y = make_blobs(n_samples=100, n_features=3, centers=10, cluster_std=1)
plt.pyplot.scatter(X[:,0],X[:,1], c=y)
plt.pyplot.show()
clf_bagging = BaggingClassifier(n_estimators=100,random_state=1,warm_start=True)
# fitting bagging model
clf_bagging.fit(X,y)
# predict bagging model
prediction_list = clf_bagging.predict(X)
############################# random forest ################################
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
import matplotlib as plt
X, y = make_blobs(n_samples=10000, n_features=10, centers=10,random_state=0)
# X = data, y=label
plt.pyplot.scatter(X[:, 0], X[:, 1], c=y)
plt.pyplot.show()
# 模型1
clf_rf = DecisionTreeClassifier(max_depth=None, min_samples_split=2,random_state=0)
# 通过cross validation进行结果的输出
scores = cross_val_score(clf, X, y)
scores.mean()
# 直接输出结果
clf_rf.fit(X,y)
clf_rf.predict(X)
############################# Ada boosting #####################################
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_blobs
import matplotlib as plt
X, y = make_blobs(n_samples=10000, n_features=10, centers=10,random_state=0)
# X = data, y=label
plt.pyplot.scatter(X[:,0],X[:,1], c=y)
clf_adaboost = AdaBoostClassifier(n_estimators=100)
# 通过cross validation进行结果的输出
scores = cross_val_score(clf_adaboost, X, y)
scores.mean()
# 正常拟合
clf_adaboost.fit(X,y)
clf_adaboost.predict(X)
############################# gradient boosting #####################################
# classification
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import make_blobs
import matplotlib as plt
X, y = make_blobs(n_samples=10000, n_features=10, centers=10,random_state=0)
clf_GBM = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,max_depth=1, random_state=0)
clf_GBM.fit(X, y)
clf_GBM.predict(X)