CVTE-典型DNN结构
目前使用比较多的网络结构主要有ResNet(152-1000层),GooleNet(22层),VGGNet(19层)。
- Lenet,1998年
- Alexnet,2012年
- GoogleNet,2014年
- VGG,2014年
- Deep Residual Learning,2015年
Lenet5
LeNet5 诞生于 1994 年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。自从 1988 年开始,在许多次成功的迭代后,这项由 Yann LeCun 完成的开拓性成果被命名为 LeNet5。

由两个卷积层,两个池化层,以及两个全连接层组成。 卷积都是5*5的模板,stride=1,池化都是MAX。
LeNet5特征能够总结为如下几点:
1)卷积神经网络使用三个层作为一个系列: 卷积,池化,非线性
2) 使用卷积提取空间特征
3)使用映射到空间均值下采样(subsample)
4)双曲线(tanh)或S型(sigmoid)形式的非线性
5)多层神经网络(MLP)作为最后的分类器
6)层与层之间的稀疏连接矩阵避免大的计算成本
Alexnet
2012年,Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本。AlexNet中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。同时AlexNet也使用了GPU进行运算加速,作者开源了他们在GPU上训练卷积神经网络的CUDA代码。AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。AlexNet以显著的优势赢得了竞争激烈的ILSVRC 2012比赛,top-5的错误率降低至了16.4%。AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深度学习(深度卷积网络)在计算机视觉的统治地位,同时也推动了深度学习在语音识别、自然语言处理、强化学习等领域的拓展。
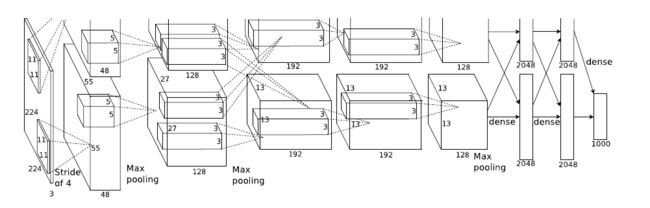
其中输入的图片尺寸为224´224,第一个卷积层使用了较大的卷积核尺寸11´11,步长为4,有96个卷积核;紧接着一个LRN层;然后是一个3´3的最大池化层,步长为2。这之后的卷积核尺寸都比较小,都是5´5或者3´3的大小,并且步长都为1,即会扫描全图所有像素;而最大池化层依然保持为3´3,并且步长为2。我们可以发现一个比较有意思的现象,在前几个卷积层,虽然计算量很大,但参数量很小,都在1M左右甚至更小,只占AlexNet总参数量的很小一部分。这就是卷积层有用的地方,可以通过较小的参数量提取有效的特征。虽然每一个卷积层占整个网络的参数量的1%都不到,但是如果去掉任何一个卷积层,都会使网络的分类性能大幅地下降。
只有寥寥八层(不算input层),但是它有60M以上的参数总量。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下。
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层(Local Response Normalization,局部相应归一化层),对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。同时,AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(6)数据增强,随机地从256´256的原始图像中截取224´224大小的区域(以及水平翻转的镜像),相当于增加了(256-224)2´2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。同时,AlexNet论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
(1)con - relu - pooling - LRN
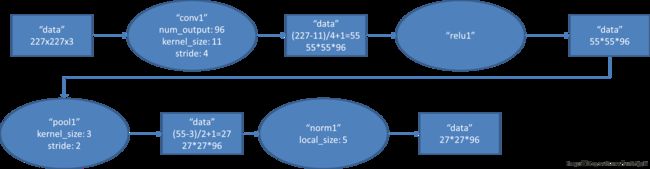
具体计算都在图里面写了,要注意的是input层是227*227,而不是paper里面的224*224,这里可以算一下,主要是227可以整除后面的conv1计算,224不整除。如果一定要用224可以通过自动补边实现,不过在input就补边感觉没有意义,补得也是0。
(2)conv - relu - pool - LRN

和上面基本一样,唯独需要注意的是group=2,这个属性强行把前面结果的feature map分开,卷积部分分成两部分做。
(3)conv - relu

(4)conv-relu

(5)conv - relu - pool

(6)fc - relu - dropout
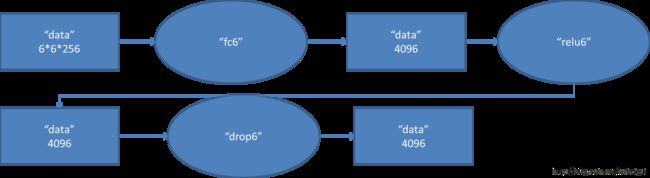
这里有一层特殊的dropout层,在alexnet中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点。
(7)
fc - relu - dropout 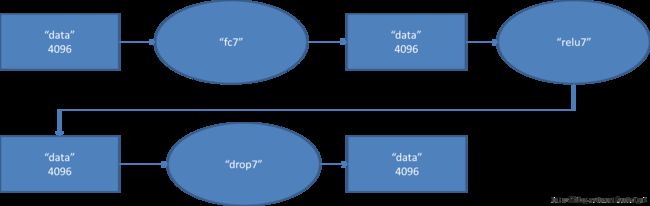
(8)fc - softmax 
VGGNet
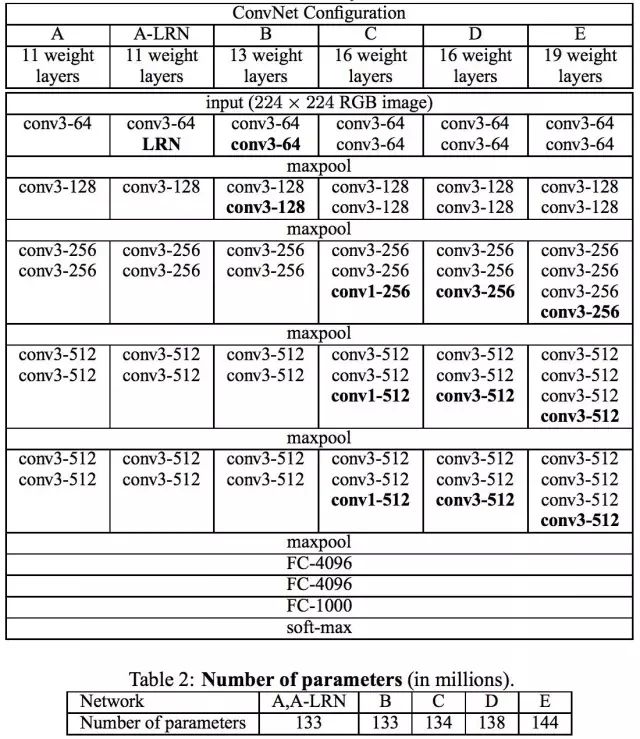
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的的深度卷积神经网络。VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3´3的小型卷积核和2´2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降,并取得了ILSVRC 2014比赛分类项目的第2名和定位项目的第1名。同时VGGNet的拓展性很强,迁移到其他图片数据上的泛化性非常好。VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3´3)和最大池化尺寸(2´2)。到目前为止,VGGNet依然经常被用来提取图像特征。VGGNet训练后的模型参数在其官方网站上开源了,可用来在domain specific的图像分类任务上进行再训练(相当于提供了非常好的初始化权重),因此被用在了很多地方。
VGGNet论文中全部使用了3´3的卷积核和2´2的池化核,通过不断加深网络结构来提升性能。虽然从A到E每一级网络逐渐变深,但是网络的参数量并没有增长很多,这是因为参数量主要都消耗在最后3个全连接层。前面的卷积部分虽然很深,但是消耗的参数量不大,不过训练比较耗时的部分依然是卷积,因其计算量比较大。这其中的D、E也就是我们常说的VGGNet-16和VGGNet-19。C很有意思,相比B多了几个1´1的卷积层,1´1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
VGG 网络是第一个在各个卷积层使用更小的 3×3 过滤器(filter),并把它们组合作为一个卷积序列进行处理的网络。和 LeNet 的原理相反,其中是大的卷积被用来获取一张图像中相似特征。和 AlexNet 的 9×9 或 11×11 过滤器不同,过滤器开始变得更小,离 LeNet 竭力所要避免的臭名昭著的 1×1 卷积异常接近——至少在该网络的第一层是这样。但是 VGG 巨大的进展是通过依次采用多个 3×3 卷积,能够模仿出更大的感受野(receptive field)的效果,例如 5×5 与 7×7。这些思想也被用在了最近更多的网络架构中,如 Inception 与 ResNet。它主要的贡献是展示出网络的深度是算法优良性能的关键部分。
两个3´3的卷积层串联相当于1个5´5的卷积层,即一个像素会跟周围5´5的像素产生关联,可以说感受野大小为5´5。而3个3´3的卷积层串联的效果则相当于1个7´7的卷积层。除此之外,3个串联的3´3的卷积层,拥有比1个7´7的卷积层更少的参数量。最重要的是,3个3´3的卷积层拥有比1个7´7的卷积层更多的非线性变换(前者可以使用三次ReLU激活函数,而后者只有一次),使得CNN对特征的学习能力更强。
几个小滤波器卷积层的组合比一个大滤波器卷积层好:假设你一层一层地重叠了3个3x3的卷积层(层与层之间有非线性激活函数)。在这个排列下,第一个卷积层中的每个神经元都对输入数据体有一个3x3的视野。第二个卷积层上的神经元对第一个卷积层有一个3x3的视野,也就是对输入数据体有5x5的视野。同样,在第三个卷积层上的神经元对第二个卷积层有3x3的视野,也就是对输入数据体有7x7的视野。假设不采用这3个3x3的卷积层,而是使用一个单独的有7x7的感受野的卷积层,那么所有神经元的感受野也是7x7,但是就有一些缺点。首先,多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。其次,假设所有的数据有C个通道,那么单独的7x7卷积层将会包含7*7*C=49C2个参数,而3个3x3的卷积层的组合仅有个3*(3*3*C)=27C2个参数。直观说来,最好选择带有小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者可以表达出输入数据中更多个强力特征,使用的参数也更少。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
1*1 filter: 作用是在不影响输入输出维数的情况下,对输入线进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
VGGNet在训练时有一个小技巧,先训练级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样训练收敛的速度更快。在预测时,VGG采用Multi-Scale的方法,将图像scale到一个尺寸Q,并将图片输入卷积网络计算。然后在最后一个卷积层使用滑窗的方式进行分类预测,将不同窗口的分类结果平均,再将不同尺寸Q的结果平均得到最后结果,这样可提高图片数据的利用率并提升预测准确率。
同时在训练中,VGGNet还使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224´224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。最终提交到ILSVRC 2014的版本是仅使用Single-Scale的6个不同等级的网络与Multi-Scale的D网络的融合,达到了7.3%的错误率。不过比赛结束后作者发现只融合Multi-Scale的D和E可以达到更好的效果,错误率达到7.0%,再使用其他优化策略最终错误率可达到6.8%左右。同时,作者在对比各级网络时总结出了以下几个观点。
(1)LRN层作用不大。
(2)越深的网络效果越好。
(3)1´1的卷积也是很有效的,但是没有3´3的卷积好,大一些的卷积核可以学习更大的空间特征。
网络中的网络(Network-in-network)
网络中的网络(NiN)的思路简单又伟大:使用 1×1 卷积为卷积层的特征提供更组合性的能力。
NiN 架构在各个卷积之后使用空间 MLP 层,以便更好地在其他层之前组合特征。同样,你可以认为 1×1 卷积与 LeNet 最初的原理相悖,但事实上它们可以以一种更好的方式组合卷积特征,而这是不可能通过简单堆叠更多的卷积特征做到的。这和使用原始像素作为下一层输入是有区别的。其中 1×1 卷积常常被用于在卷积之后的特征映射上对特征进行空间组合,所以它们实际上可以使用非常少的参数,并在这些特征的所有像素上共享!
MLP 的能力能通过将卷积特征组合进更复杂的组(group)来极大地增加单个卷积特征的有效性。这个想法之后被用到一些最近的架构中,例如 ResNet、Inception 及其衍生技术。
NiN 也使用了平均池化层作为最后分类器的一部分(这里作者说的有异议,全连接层替换成平均池化层,NIN提出的),这是另一种将会变得常见的实践。这是通过在分类之前对网络对多个输入图像的响应进行平均完成的。
GoogleNet
来自谷歌的 Christian Szegedy 开始追求减少深度神经网络的计算开销,并设计出 GoogLeNet——第一个 Inception 架构。
Christian 考虑了很多关于在深度神经网络达到最高水平的性能(例如在 ImageNet 上)的同时减少其计算开销的方式。或者在能够保证同样的计算开销的前提下对性能有所改进。他和他的团队提出了 Inception 模块:
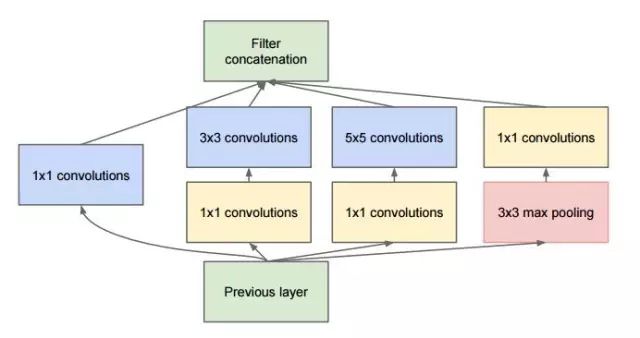
初看之下这不过基本上是 1×1、3×3、5×5 卷积过滤器的并行组合。但是 Inception 的伟大思路是用 1×1 的卷积块(NiN)在昂贵的并行模块之前减少特征的数量。这一般被称为「瓶颈(bottleneck)」。GoogleNet 使用没有 inception 模块的主干作为初始层,之后是与 NiN 相似的一个平均池化层加 softmax 分类器。这个分类器比 AlexNet 与 VGG 的分类器的运算数量少得多。
瓶颈层(Bottleneck layer)
受到 NiN 的启发,Inception 的瓶颈层减少了每一层的特征的数量,并由此减少了运算的数量;所以可以保持较低的推理时间。在将数据通入昂贵的卷积模块之前,特征的数量会减少 4 倍。在计算成本上这是很大的节约,也是该架构的成功之处。
让我们具体验证一下。现在你有 256 个特征输入,256 个特征输出,假定 Inception 层只能执行 3×3 的卷积,也就是总共要完成 256×256×3×3 的卷积(将近 589,000 次乘积累加(MAC)运算)。这可能超出了我们的计算预算,比如说,在谷歌服务器上要以 0.5 毫秒运行该层。作为替代,我们决定减少需要进行卷积运算的特征的数量,也就是 64(即 256/4)个。在这种情况下,我们首先进行 256 -> 64 1×1 的卷积,然后在所有 Inception 的分支上进行 64 次卷积,接而再使用一个来自 64 -> 256 的特征的 1×1 卷积,现在运算如下:256×64 × 1×1 = 16,000s; 64×64 × 3×3 = 36,000s; 64×256 × 1×1 = 16,000s,相比于之前的 60 万,现在共 7 万的计算量,少近 10 倍。而且,尽管我们做了更好的运算,我们在此层也没有损失其通用性。事实证明瓶颈层在 ImageNet 这样的数据集上已经表现出了顶尖水平,而且它也被用于 ResNet 这样的架构中。它之所以成功是因为输入特征是相关联的,因此可通过将它们与 1×1 卷积适当结合来减少冗余。然后,在小数量的特征进行卷积之后,它们能在下一层被再次扩展成有意义的结合。
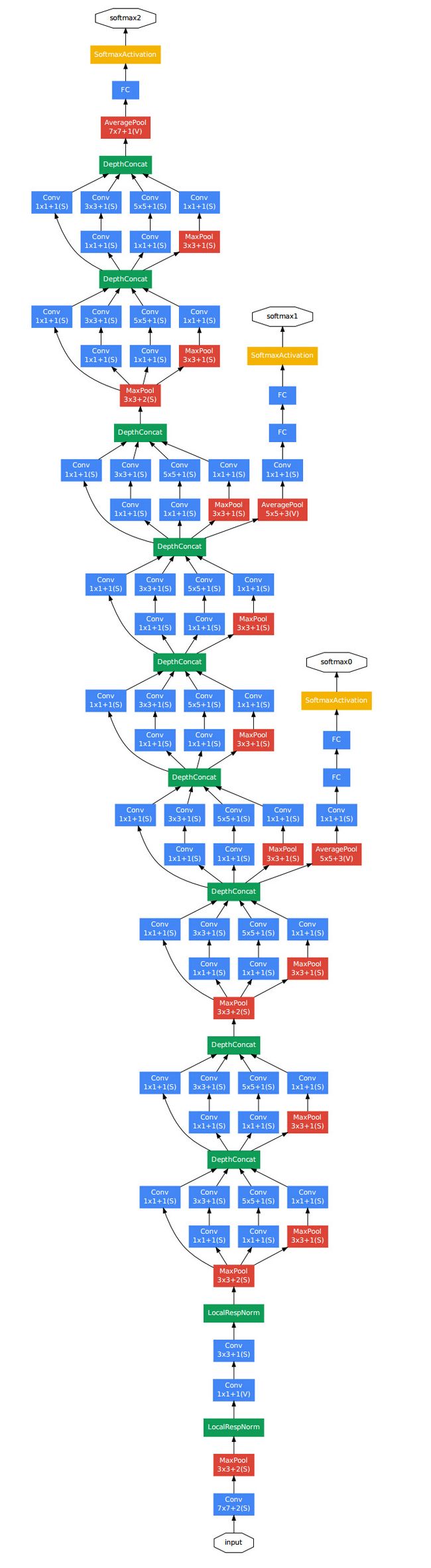
Inception V3(还有 V2)
2015 年 2 月,Batch-normalized Inception 被引入作为 Inception V2。Batch-normalization 在一层的输出上计算所有特征映射的均值和标准差,并且使用这些值规范化它们的响应。这相当于数据「增白(whitening)」,因此使得所有神经图在同样范围有响应,而且是零均值。在下一层不需要从输入数据中学习 offset 时,这有助于训练,还能重点关注如何最好的结合这些特征。
2015 年 12 月,该团队发布 Inception 模块和类似架构的一个新版本。原始思路如下:通过谨慎建筑网络,平衡深度与宽度,从而最大化进入网络的信息流。在每次池化之前,增加特征映射。当深度增加时,网络层的深度或者特征的数量也系统性的增加。使用每一层深度增加在下一层之前增加特征的结合。
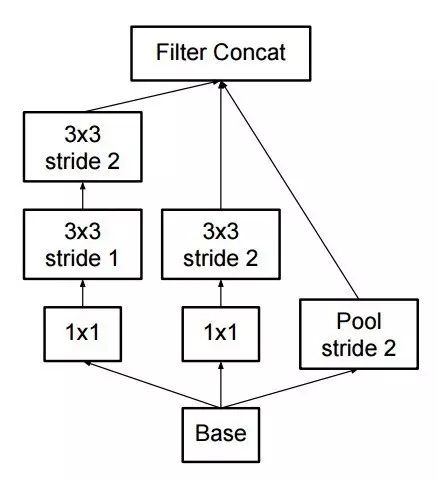
只使用 3×3 的卷积,可能的情况下给定的 5×5 和 7×7 过滤器能分成多个 3×3。看下图

因此新的 Inception 成为了:

也可以通过将卷积平整进更多复杂的模块中而分拆过滤器:

在进行 inception 计算的同时,Inception 模块也能通过提供池化降低数据的大小。这类似于运行一个卷积的时候并行一个简单的池化层:
Inception 也使用一个池化层和 softmax 作为最后的分类器。
ResNet
这和 Inception V3 出现的时间一样。ResNet 有着简单的思路:供给两个连续卷积层的输出,并分流(bypassing)输入进入下一层。

ResNet 中,它们分流两个层并被应用于更大的规模。在 2 层后分流是一个关键直觉,因为分流一个层并未给出更多的改进。通过 2 层可能认为是一个小型分类器,或者一个 Network-In-Network。这是第一次网络层数超过一百,甚至还能训练出 1000 层的网络。有大量网络层的 ResNet 开始使用类似于 Inception 瓶颈层的网络层:

这种层通过首先是由带有更小输出(通常是输入的 1/4)的 1×1 卷积较少特征的数量,然后使用一个 3×3 的层,再使用 1×1 的层处理更大量的特征。类似于 Inception 模块,这样做能保证计算量低,同时提供丰富的特征结合。
ResNet 在输入上使用相对简单的初始层:一个带有两个池的 7×7 卷积层。ResNet 也使用一个池化层加上 softmax 作为最后的分类器。
关于 ResNet 的其他洞见每天都有发生:ResNet 可被认为既是平行模块又是连续模块,把输入输出(inout)视为在许多模块中并行,同时每个模块的输出又是连续连接的。ResNet 也可被视为并行模块或连续模块的多种组合。已经发现 ResNet 通常在 20-30 层的网络块上以并行的方式运行。而不是连续流过整个网络长度。当 ResNet 像 RNN 一样把输出反馈给输入时,该网络可被视为更好的生物上可信的皮质模型。
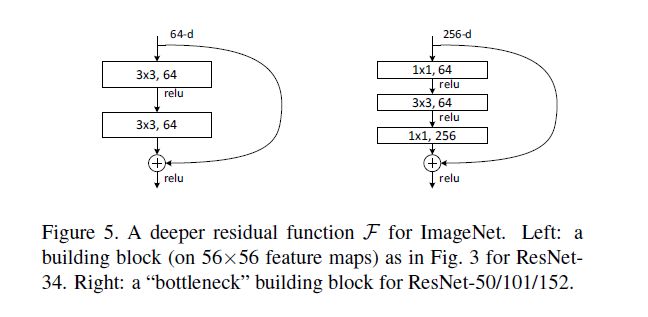
Deep Residual Learning
这个model是15年的imagenet比赛冠军。可以说是进一步将conv进行到底,其特殊之处在于设计了“bottleneck”形式的block(有跨越几层的直连)。最深的model采用的152层!!下面是一个34层的例子,更深的model见表格。 
其实这个model构成上更加简单,连LRN这样的layer都没有了。
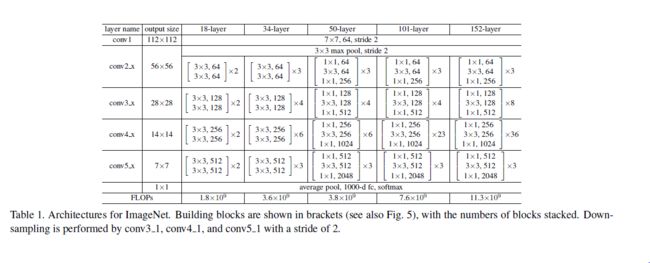
block的构成见下图: