MapReduce源码分析——MapTask流程分析
前言
首先要说,MapTask,分为4种,分别是Job-setup Task,Job-cleanup Task,Task-cleanup和Map Task。
Job-setup Task、Job-cleanup Task分别是作业运行时启动的第一个任务和最后一个任务,主要工作分别是进行一些作业初始化和收尾工作,比如创建和删除作业临时输出目录;Task-cleanup Task则是任务失败或者被杀死后,用于清理已写入临时目录中数据的任务;最后一种Map Task则是处理数据并将结果存到本地磁盘上。
本文分析的重点,是最重要的MapTask。
源码分析
MapTask的整个过程分为5个阶段:
Read----->Map------>Collect------->Spill------>Combine
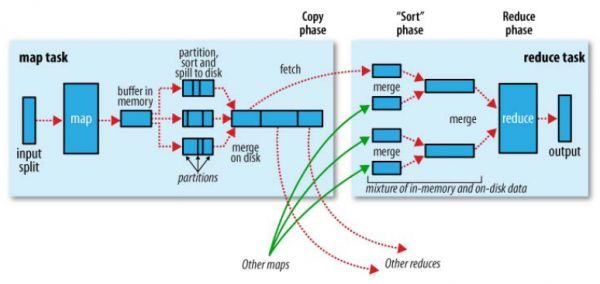
接下来我们直接分析源码
/**
* mapTask主要执行流程
*/
@Override
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical;
// start thread that will handle communication with parent
//发送task任务报告,与父进程做交流
TaskReporter reporter = new TaskReporter(getProgress(), umbilical,
jvmContext);
reporter.startCommunicationThread();
//判断用的是新的MapReduceAPI还是旧的API
boolean useNewApi = job.getUseNewMapper();
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
//map任务有4种,Job-setup Task, Job-cleanup Task, Task-cleanup Task和MapTask
if (jobCleanup) {
//这里执行的是Job-cleanup Task
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
//这里执行的是Job-setup Task
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
//这里执行的是Task-cleanup Task
runTaskCleanupTask(umbilical, reporter);
return;
}
//如果前面3个任务都不是,执行的就是最主要的MapTask,根据新老API调用不同的方法
if (useNewApi) {
//我们关注一下新的的方法实现splitMetaInfo为Spilt分片的信息
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
done(umbilical, reporter);
}
下面我们来看中的runNewMapper(job, splitMetaInfo, umbilical, reporter)方法方法,这个方法将会构造一系列的对象来辅助执行Mapper。其代码如下:
private
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
/*TaskAttemptContext类继承于JobContext类,相对于JobContext类增加了一些有关task的信息。
* 通过taskContext对象可以获得很多与任务执行相关的类,比如用户定义的Mapper类,InputFormat类等等 */
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.TaskAttemptContext(job, getTaskID());
// make a mapper//创建用户自定义的Mapper类的实例
org.apache.hadoop.mapreduce.Mapper mapper =
(org.apache.hadoop.mapreduce.Mapper)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format 创建用户指定的InputFormat类的实例
org.apache.hadoop.mapreduce.InputFormat inputFormat =
(org.apache.hadoop.mapreduce.InputFormat)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split 重新生成InputSplit
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
//根据InputFormat对象创建RecordReader对象,默认是LineRecordReader
org.apache.hadoop.mapreduce.RecordReader input =
new NewTrackingRecordReader
(split, inputFormat, reporter, job, taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
//生成RecordWriter对象
org.apache.hadoop.mapreduce.RecordWriter output = null;
org.apache.hadoop.mapreduce.Mapper.Context
mapperContext = null;
try {
Constructor contextConstructor =
org.apache.hadoop.mapreduce.Mapper.Context.class.getConstructor
(new Class[]{org.apache.hadoop.mapreduce.Mapper.class,
Configuration.class,
org.apache.hadoop.mapreduce.TaskAttemptID.class,
org.apache.hadoop.mapreduce.RecordReader.class,
org.apache.hadoop.mapreduce.RecordWriter.class,
org.apache.hadoop.mapreduce.OutputCommitter.class,
org.apache.hadoop.mapreduce.StatusReporter.class,
org.apache.hadoop.mapreduce.InputSplit.class});
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
mapperContext = contextConstructor.newInstance(mapper, job, getTaskID(),
input, output, committer,
reporter, split);
/*初始化,在默认情况下调用的是LineRecordReader的initialize方 法,主要是打开输入文件并且将文件指针指向文件头*/
input.initialize(split, mapperContext);
mapper.run(mapperContext); //Mapper的执行
input.close();
output.close(mapperContext);
} catch (NoSuchMethodException e) {
throw new IOException("Can't find Context constructor", e);
} catch (InstantiationException e) {
throw new IOException("Can't create Context", e);
} catch (InvocationTargetException e) {
throw new IOException("Can't invoke Context constructor", e);
} catch (IllegalAccessException e) {
throw new IOException("Can't invoke Context constructor", e);
}
}
(1)会获取配置信息类对象taskContext、自己开发的Mapper的实例mapper、用户指定的InputFormat对象inputFormat(默认是TextInputFormat)、任务对应的分片信息split
(2)根据inputFormat构建一个NewTrackingRecordReader对象,这个对象中的RecordReader
(3)然后创建mapreduce.RecordWriter output,如果没有reducer(满足job.getNumReduceTasks() == 0),就output =new NewDirectOutputCollector(taskContext, job, umbilical, reporter)直接输出到HDFS上;如果有reducer,就output = new NewOutputCollector(taskContext, job, umbilical, reporter)作为输出,这俩都继承自org.apache.hadoop.mapreduce.RecordWriter类。output是map任务的输出。
(4)input.initialize(split, mapperContext)初始化,在默认情况下调用的是LineRecordReader的initialize方法,主要是打开输入文件(构建一个LineReader对象,在这实现文件内容的具体读)并且将文件指针指向文件头。
(5)mapper.run(mapperContext)这里是具体执行mapper的地方,下面再讲。
(6)最后mapper执行完毕之后,就会关闭输入输出流:input.close();output.close(mapperContext)。
上面这些就是MapTask的执行过程。还有一些地方需要再详细解读一下:
一、NewDirectOutputCollector直接将map的输出写入HDFS中
NewDirectOutputCollector是没有reducer的作业,直接将map的输出写入HDFS中。输出流mapreduce.RecordWriter out = outputFormat.getRecordWriter(taskContext),默认是TextOutputFormat.getRecordWriter(taskContext)这个方法会判断有无压缩配置项,然后通过Path file = getDefaultWorkFile(job, extension),extension这个参数如果没有压缩选项会为空,获取输出文件的写入目录和文件名,getRecordWriter方法最终会返回LineRecordWriter
二、NewOutputCollector是有reducer的作业的map的输出
这个类的主要包含的对象是MapOutputCollector
三、LineRecordReader类
是用来从指定的文件读取内容传递给Mapper的map方法做处理的。实际上读文件内容的是类中的LineReader对象in,该对象在initialize方法,会根据输入文件的文件类型(压缩或不压缩)传入相应输入流对象。
LineReader输入流对象中通过readLine(Text str, int maxLineLength,int maxBytesToConsume)方法每次读取一行放入str中,并返回读取数据的长度。LineRecordReader.nextKeyValue()方法会设置两个对象key和value,key是一个偏移量指的是当前这行数据在输入文件中的偏移量(注意这个偏移量可不是对应单个分片内的偏移量,而是针对整个分布式文中的偏移量),value是通过LineReader的对象in读取的一行内容,如果没有数据可读了,这个方法会返回false,否则true。getCurrentKey()和getCurrentValue()是获取当前的key和value,调用这俩方法之前需要先调用nextKeyValue()为key和value赋新值,否则会重复,当然我们不用考虑这个因为在mapper.run方法中已经做了。
四、mapper.run()方法的执行
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
首先会执行setup方法,我们在开发自己的mapper时有时需要传一些自己的参数,可以写入context,自己重写setup方法,获取这个参数;然后循环调用nextKeyValue()方法获取key和value,执行map方法。
runNewMapper中的mapperContext,这是mapreduce.Mapper
mapperContext = contextConstructor.newInstance(mapper, job, getTaskID(),input, output, committer,reporter, split)
之前的上面的代码会实例化一个mapreduce.Mapper
之后通过WrappedMapper再对mapContext进行包装,生成一个mapperContext,这里map方法的context就是mapperContext。
然后会有同样的nextKeyValue()、getCurrentValue()、getCurrentKey()会调用reader的相应方法,从而实现了Mapper.run方法中的nextKeyValue()不断获取key和value。
当读完数据之后,会调用cleanup方法来做一些清理工作,这点我们同样可以利用,我们可以根据自己的需要重写cleanup方法。
另外我们自己的map方法中最后都会有context.write(K,V)方法用来将计算数据输出,我们顺着上一段继续追查MapContext类中并无write方法,但是它继承自TaskInputOutputContext类,进去发现RecordWriter
五.MapOutputBuffer 的概念
接下来我们看看MapOutputBuffer implements MapOutputCollector这个类了。该类内部使用一个缓冲区暂时存储用户输出数据,当缓冲区使用率达到一定阈值后,再讲缓冲区中的数据写到磁盘上。Hadoop的这个缓冲区采用环形缓冲区:当缓冲区使用率达到一定的阈值后,便开始向磁盘上写入数据,同时生产者扔可以向不断增加的剩余空间中循环写入数据,进而达到读写并行(Map Task的collect阶段和spill阶段),性能也比较高。
MapOutputBuffer采用两级索引结构,涉及三个环形缓冲区:int[] kvoffsets(偏移量索引数组,保存KV信息在位置索引kvindices中的偏移量)、int[] kvindices(位置索引数组,用于保存KV值在数据缓冲区kvbuffer中的起始位置)、byte[] kvbuffer(数据缓冲区,保存实际的KV值,默认情况下最多使用io.sort.mb的95%)。一对KV需占用数组kvoffsets的1个int大小,数组kvindices的3个int大小(分别保存所在partion号、key值开始位置、Value值开始位置),所以按比例1:3将大小为{io.sort.mb}的内存空间分配给数组kvoffsets和kvindices,默认是0.05*100MB。
MapOutputBuffer类中有一个BlockingBuffer extends DataOutputStream内部类,该类中的OutputStream out对象也是MapOutputBuffer的一个内部类Buffer extends OutputStream,Buffer主要是对kvbuffer操纵,BlockingBuffer的实例化对象是bb,该值同时是keySerializer和valSerializer(默认都是org.apache.hadoop.io.serializer.WritableSerialization的内部类WritableSerializer)的输出流对象。
MapOutputBuffer.collect方法每次都会先检查kvoffsets数组的有效容量是否超过io.sort.spill.percent,默认0.8,如果超过则唤醒spill线程写到临时文件中( startSpill()方法完成);然后通过keySerializer.serialize(key)将key写入上述说的bb输出流中,实际最终调用的是Buffer.write(byte b[], int off, int len),这个方法会将key写入环形缓冲区kvbuffer中,如果kvbuffer的有效内存容量超过io.sort.spill.percent则会唤醒spill线程写到临时文件中( startSpill()方法完成),如果发生key跨界情况(bufindex < keystart),要保证key不能跨界(因为是排序的关键字要求排序关键字连续存储),会调用bb.reset()来直接操纵kvbuffer处理两种情况(一种是头部可以放下key,另外一种则不可以);然后是keySerializer.serialize(key),写到kvbuffer中,可以参考序列化key时的过程,但value可以跨界。如果遇到一条记录的key或者value太大以至于整个缓冲区都放不下,则会抛出MapBufferTooSmallException,执行spillSingleRecord(key, value, partition)会将该记录单独输出到一个文件中。
可以看出触发spill溢写操作的条件是:kvoffsets或者kvbuffer有效容量超过io.sort.spill.percent;出现一条缓冲区kvbuffer无法容纳的超大记录。
SpillThread线程在构造方法中已经启动,线程的run方法就是一直等待被唤醒,一旦唤醒就调用sortAndSpill()方法排序并写文件,startSpill()会唤醒这个线程。
protected class SpillThread extends Thread {
@Override
public void run() {
spillLock.lock();
spillThreadRunning = true;
try {
while (true) {
spillDone.signal();
while (!spillInProgress) {
spillReady.await();
}
try {
spillLock.unlock();
sortAndSpill();
} catch (Throwable t) {
sortSpillException = t;
} finally {
spillLock.lock();
if (bufend < bufstart) {
bufvoid = kvbuffer.length;
}
kvstart = kvend;
bufstart = bufend;
spillInProgress = false;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
spillLock.unlock();
spillThreadRunning = false;
}
}
}
先计算写入文件的大小;然后获取写到本地(非HDFS)文件的文件名,会有一个编号,例如output/spill2.out;然后构造一个输出流;然后使用快排对缓冲区kvbuffe中区间[bufstart,bufend)内的数据进行排序,先按分区编号partition进行排序,然后按照key进行排序。这样经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
之后会构建一个IFile.Writer对象将输出流传进去,输出到指定的文件当中,这个对象支持行级的压缩。如果用户设置了Combiner,则写入文件之前会对每个分区中的数据进行一次聚集操作,通过combinerRunner.combine(kvIter, combineCollector)实现,combine方法会执行reducer.run方法,只不过输出和正常的reducer不一样而已,这里最终会调用IFile.Writer的append方法实现本地文件的写入。
最后调用mergeParts()方法合并所有spill文件。代码如下:
private void mergeParts() throws IOException, InterruptedException,
ClassNotFoundException {
// get the approximate size of the final output/index files
long finalOutFileSize = 0;
long finalIndexFileSize = 0;
final Path[] filename = new Path[numSpills];
final TaskAttemptID mapId = getTaskID();
for(int i = 0; i < numSpills; i++) {
filename[i] = mapOutputFile.getSpillFile(i); //通过spill文件的编号获取到指定的spill文件路径
finalOutFileSize += rfs.getFileStatus(filename[i]).getLen();
}
//合并输出有俩文件一个是output/file.out,一个是output/file.out.index
if (numSpills == 1) { //the spill is the final output
rfs.rename(filename[0],
new Path(filename[0].getParent(), "file.out"));
if (indexCacheList.size() == 0) {
rfs.rename(mapOutputFile.getSpillIndexFile(0),
new Path(filename[0].getParent(),"file.out.index"));
} else { //写入文件
indexCacheList.get(0).writeToFile(
new Path(filename[0].getParent(),"file.out.index"), job);
}
return;
}
// read in paged indices
for (int i = indexCacheList.size(); i < numSpills; ++i) {
Path indexFileName = mapOutputFile.getSpillIndexFile(i);
indexCacheList.add(new SpillRecord(indexFileName, job, null));
}
//make correction in the length to include the sequence file header
//lengths for each partition
finalOutFileSize += partitions * APPROX_HEADER_LENGTH;
finalIndexFileSize = partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH;
Path finalOutputFile =
mapOutputFile.getOutputFileForWrite(finalOutFileSize); //output/file.out
Path finalIndexFile =
mapOutputFile.getOutputIndexFileForWrite(finalIndexFileSize); //output/file.out.index
//The output stream for the final single output file
FSDataOutputStream finalOut = rfs.create(finalOutputFile, true, 4096);
if (numSpills == 0) {
//create dummy(假的,假设) files
IndexRecord rec = new IndexRecord();
SpillRecord sr = new SpillRecord(partitions);
try {
for (int i = 0; i < partitions; i++) {
long segmentStart = finalOut.getPos();
Writer writer =
new Writer(job, finalOut, keyClass, valClass, codec, null);
writer.close();
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength();
rec.partLength = writer.getCompressedLength();
sr.putIndex(rec, i);
}
sr.writeToFile(finalIndexFile, job);
} finally {
finalOut.close();
}
return;
}
{
IndexRecord rec = new IndexRecord();
final SpillRecord spillRec = new SpillRecord(partitions);
//finalOut最终输出文件。循环分区获得所有spill文件的该分区数据,合并写入finalOut
for (int parts = 0; parts < partitions; parts++) {
//create the segments to be merged
List> segmentList =
new ArrayList>(numSpills);
for(int i = 0; i < numSpills; i++) {
IndexRecord indexRecord = indexCacheList.get(i).getIndex(parts);
Segment s =
new Segment(job, rfs, filename[i], indexRecord.startOffset,
indexRecord.partLength, codec, true);
segmentList.add(i, s);
if (LOG.isDebugEnabled()) {
LOG.debug("MapId=" + mapId + " Reducer=" + parts +
"Spill =" + i + "(" + indexRecord.startOffset + "," +
indexRecord.rawLength + ", " + indexRecord.partLength + ")");
}
}
//merge
@SuppressWarnings("unchecked")
RawKeyValueIterator kvIter = Merger.merge(job, rfs,
keyClass, valClass, codec,
segmentList, job.getInt("io.sort.factor", 100),//做merge操作时同时操作的stream数上限
new Path(mapId.toString()),
job.getOutputKeyComparator(), reporter,
null, spilledRecordsCounter);
//write merged output to disk
long segmentStart = finalOut.getPos();
Writer writer =
new Writer(job, finalOut, keyClass, valClass, codec,
spilledRecordsCounter);
// minSpillsForCombine 在MapOutputBuffer构造函数内被初始化,
// numSpills 为mapTask已经溢写到磁盘spill文件数量
if (combinerRunner == null || numSpills < minSpillsForCombine) {
Merger.writeFile(kvIter, writer, reporter, job);
} else {
combineCollector.setWriter(writer);
//其实写入数据的还是这里的writer类的append方法,这的输出是output/file.out文件,是合并后的文件
combinerRunner.combine(kvIter, combineCollector);
}
//close
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength();
rec.partLength = writer.getCompressedLength();
spillRec.putIndex(rec, parts);
}
spillRec.writeToFile(finalIndexFile, job); //写入索引文件
finalOut.close(); //合并后的输出文件
for(int i = 0; i < numSpills; i++) {
rfs.delete(filename[i],true);
}
}
}
该方法会将所有临时文件合并成一个大文件保存到output/file.out中,同时生成相应的索引文件output/file.out.index。 在进行文件合并的过程中,Map Task以分区为单位进行合并。
另外需要注意的是,mergeParts()中也有combiner的操作,但是需要满足一定的条件:
1、用户设置了combiner;
2、spill文件的数量超过了minSpillsForCombine的值,对应配置项"min.num.spills.for.combine",可自行设置,默认是3。
这俩必须同时具备才会在此启动combiner的本地聚集操作。所以在Map阶段有可能combiner会执行两次,所以有可能你的combiner执行两次之后输出数据不符合预期了。
总结
Map阶段的任务主要是读取数据然后写入内存缓冲区,缓存区满足条件就会快排后并设置partition后,spill到本地文件和索引文件;
如果有combiner,spill之前也会做一次聚集操作,待数据跑完会通过归并合并所有spill文件和索引文件。
如果有combiner,合并之前在满足条件后会做一次综合的聚集操作。map阶段的结果都会存储在本地中(如果有reducer的话),非HDFS。
注意
1.Combiner
Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,这样文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
2.默认分片大小与分块大小是相同的原因
hadoop在存储有输入数据(HDFS中的数据)的节点上运行map任务,可以获得高性能,这就是所谓的数据本地化。所以最佳分片的大小应该与HDFS上的块大小一样,因为如果分片跨越2个数据块,对于任何一个HDFS节点,分片中的另外一块数据就需要通过网络传输到map任务节点,与使用本地数据运行map任务相比,效率则更低!
3.map阶段的溢写疑问?
溢写阶段,分两类:
- 环形缓冲区的数据到达80%时,就会溢写到本地磁盘,当再次达到80%时,就会再次溢写到磁盘,直到最后一次,不管环形缓冲区还有多少数据,都会溢写到磁盘。然后会对这多次溢写到磁盘的多个小文件进行合并,减少Reduce阶段的网络传输。
- 就是没有达到80%map阶段就结束了,这时直接把环形缓冲区的数据写到磁盘上,供下一步合并使用。
参考资料
MapReduce的MapTask任务的运行源码级分析
)