TensorFlow学习Day3读取csv文件,动手写个logistic,softmax分类模型
上一篇讲到了logistic模型,今天用kaggle竞赛的数据集Titanic做一个小小的训练示范。
数据集可以从官网下载:https://www.kaggle.com/c/titanic/data
首先我们写一个读取文件的函数
# 读取文件
def read_csv(batch_size, file_name, record_defaults):
filename_queue = tf.train.string_input_producer([''.join([os.path.dirname(__file__), './dataset/', file_name])])
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(filename_queue)
decoded = tf.decode_csv(value, record_defaults=record_defaults)
return tf.train.shuffle_batch(decoded, batch_size=batch_size, capacity=batch_size*50, min_after_dequeue=batch_size)tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, shared_name=None, name=None, cancel_op=None)
string_input_producer函数生成一个文件队列,可以做随机打乱操作,然后交给阅读器读取。
reader用来读csv文件,key和value都是文本
decode_csv会将字符串转换到具有指定默认值的由张量列构成的元组中,它还会为每一列设置数据类型,每一列对应一个张量
最后shuffle batch将tensors打乱。
然后我们可以写个函数来读入数据,返回features和结果labels
def inputs():
passenger_id, survived, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked = \
read_csv(BATCH_SIZE, 'titanic.csv', [[0.0], [0.0], [0], [''], [''], [0.0], [0.0], [0.0], [''], [0.0], [''], ['']])
# 转换属性数据
is_first_class = tf.to_float(tf.equal(pclass, [1]))
is_second_class = tf.to_float(tf.equal(pclass, [2]))
is_third_class = tf.to_float(tf.equal(pclass, [3]))
gender = tf.to_float(tf.equal(sex, ["female"]))
age = tf.nn.l2_normalize(age, dim=0)
features = tf.transpose(tf.stack([is_first_class, is_second_class, is_third_class, gender, age]))
survived = tf.reshape(survived, [BATCH_SIZE, 1])
print(features.shape)
return features, survived我们将batch_size, 文件名,和每个feature的数据类型传递给read_csv函数,该函数给出一个tensor的list,每个column一个tensor。
pclass是一个属性变量,1,2,3种取值表示1,2,3等级的船舱。回归里对属性变量的处理方式一般来说是用dummy variable. 即为每种取值生成0,1变量,当取该种类时,值为1.
tf.equal(plcass,[1])返回布尔值,pclass=1的返回TRUE
然后就可以按照前两篇的内容搭建logistic回归模型
w = tf.Variable(tf.zeros([5,1]), name='weights')
b = tf.Variable(-0.9, name='bias')
def inference(x):
y_hat = tf.matmul(x, w)+b
# return tf.sigmoid(y_hat)
return y_hat
def loss(x, y):
return tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=inference(x), labels=y))
def train(total_loss):
learning_rate = 0.01
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
with tf.Session() as sess:
tf.global_variables_initializer().run()
features, survived = inputs()
total_loss = loss(features, survived)
train_op = train(total_loss)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for step in range(10000):
sess.run([train_op])
if step % 100 == 0:
print('loss:', sess.run(total_loss))
print('wb:', sess.run([w, b]))
coord.request_stop()
coord.join(threads)2. softmax分类
logistic模型的返回结果是针对二元分类问题的预测,当p大于某个阈值时我们将case归为yes。对于多分类问题,我们可以用softmax
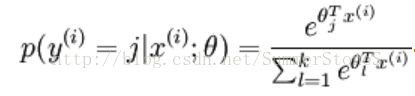
对于给定的x取值,该样本是j类的概率,假设有k种分类
softmax函数返回一个含有C个分量的概率向量,每个分量分别对应属于各种类别的概率。每种类别对应不同的weights组合(图中公式的theta)

关于softmax更多详见http://neuralnetworksanddeeplearning.com/chap3.html#softmax
我们用Yanlecun官方上给出的手写数字数据集来做softmax模型
http://yann.lecun.com/exdb/mnist/
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("mnist/", one_hot=True)
def inputs():
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
return x,y
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
def inference(x):
return tf.nn.softmax(tf.matmul(x, W) + b)
def loss(x, y):
return tf.reduce_mean(-tf.reduce_sum(y * tf.log(inference(x)), reduction_indices=[1]))
def train(total_loss):
learning_rate = 0.5
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
with tf.Session() as sess:
tf.global_variables_initializer().run()
x, y = inputs()
total_loss = loss(x, y)
train_op = train(total_loss)
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_op, feed_dict={x: batch_xs, y: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(inference(x), 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}))loss(xi)= - sigma(y_c*log(y_predict_c)) 即每个样本只有一个损失值会被计入。
训练集上的总loss是所有样本的loss(xi)的和。
tensorflow为softmax交叉熵函数提供了两个版本,tf.nn.sparse_softmax_cross_entropy_with_logits和tf.nn.softmax_cross_entropy_with_logits.
前者针对每个样本对应单个类别,后者适合每个样本对应不同分类有相应概率的情形。