苹果首次将深度学习应用于人脸识别是在 iOS 10 上。通过 Vision 框架,开发者现在可以在 App 中将该技术与其他很多计算机视觉算法进行整合。为了保护用户隐私,保证有效运行,苹果在开发这个框架的过程中克服了大量挑战。本文旨在探讨这些挑战,并介绍人脸识别算法。
简介
通过 CIDetector 类,苹果首先借助核心图像(Core Image)框架中的公共 API 公开了人脸识别技术。这个 API 同样也用在苹果 App 中,比如 Photos。最早版本的 CIDetector 使用了一种基于 Viola-Jones 检测算法的方法 [1]。我们基于 CIDetector 的后续改进推动了传统计算机视觉的发展。
随着深度学习的出现,及其在计算机视觉问题上的应用,当前最优的人脸识别精确度获得巨大提升。我们不得不重新思考我们的方法,从而搭上这次范式转换的便车。相较于传统计算机视觉,深度学习模型需要更大数量级的内存、硬盘和算力。当下典型的高端智能手机并不是运行深度学习视觉模型的一个可行平台。业界的绝大多数解决方案是深度学习云端 API,在这些方案中,图像被发送到云端的服务器,并借助深度学习推理完成人脸的分析和检测。云服务通常使用内存巨大的桌面级 GPU。非常大型的模型及其集成能够运行在云服务器端,从而客户端(移动手机)也具备了在本地端不可能实现的深度学习能力。
苹果的 iCloud Photo 库是一个专为图片和视频存储设计的云解决方案。然而由于苹果对用户隐私的保护,我们无法使用 iCloud 服务器进行计算机视觉计算。每个图片和视频加密之后,才会发送到 iCloud Photo 进行存储,并且只能通过已注册 iCloud 账户的设备解密。因此,为让用户体验到基于深度学习的计算机视觉解决方案,我们选择迎难而上,使深度学习算法运行在 iPhone 上。
我们面临着若干个挑战,深度学习模型需要作为一部分封装进手机操作系统,占用宝贵的 NAND 存储空间。它们同样需要被加载进 RAM,并在 GPU 和/或 CPU 上消耗大量计算时间。与云服务只能单独专注地解决一个视觉问题不同,设备内置计算的同时必须与其他运行的应用共享这些系统资源。最后,计算必须足够高效才能在一个合理的短时间内处理一个大的 Photos 库,并不带有显著的功耗或过热问题。
余文讨论了我们的算法——一种基于深度学习的人脸识别方法,以及我们如何成功地克服挑战取得了当前最佳的精确度。讨论内容如下:
- 我们如何(通过 BNNS 和 Metal)充分利用 GPU 和 CPU
- 网络推理的内存优化、图像加载和缓存
- 我们如何以一种符合 iPhone 预期的、不会干扰其他多项同时任务的方式来实现网络
从 Viola-Jones 到深度学习
2014 年,当我们开始用深度学习检测图像中的人脸之时,深度卷积网络(DCN)刚刚在物体识别任务中取得有希望的结果。其中最突出的一个方法是「OverFeat」[2],它的一些简单想法证明 DCN 在扫描物体图像时相当有效,这使得 OverFeat 很流行。
OverFeat 描述了神经网络全连接层与卷积层之间的等价性,其与输入具有相同空间维度的滤波器的有效卷积。该项工作表明,一个固定接受野(比如 32x32,自然步幅为 16 像素)的二值分类网络可以有效应用于任意大小(比如 320x320)的图像,从而产出一个适当大小(20x20)的输出映射。OverFeat 论文中同样提出了通过有效减少网络步幅而产出更密集输出映射的聪明方法。
我们在 OverFeat 论文的基础上构建了最初架构,形成一个全卷积网络(见图 1),其中包含以下多任务目标:
- 一个预测输入中有或没有人脸的二元分类,以及
- 一个预测最优地定位输入中人脸边界框参数的回归。
我们尝试了若干个方法训练该网络。比如,一个简单的训练步骤是创建一个固定大小的大型图像块数据集,该图像块对应于网络的最小有效输入,使得每个块产生来自网络的单个输出。这一训练数据集达到了理想的平衡,因此,一半的图像块包含人脸(正类),一半不包含人脸(负类)。对于每个正块,我们提供该人脸的实际位置(x, y, w, h)。我们训练这个网络优化上述的多任务目标。一旦训练完成,网络就能够预测一个块是否含有人脸,如果是,它还提供该图块中人脸的坐标和比例。
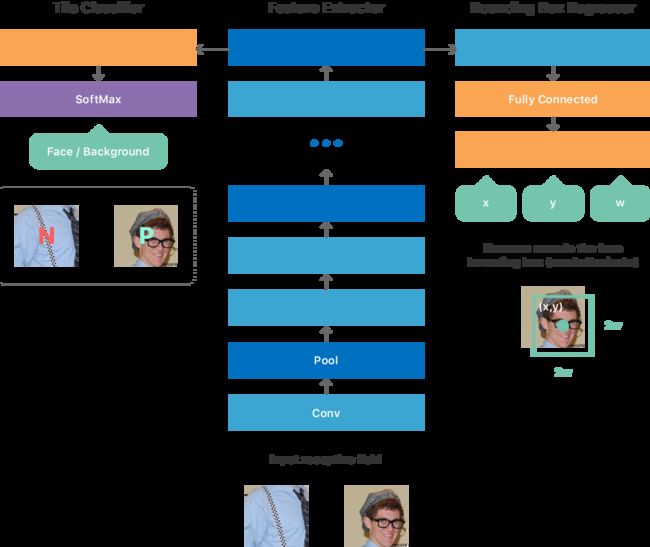
图 1. 一个用于人脸识别的改进版 DCN
由于网络是全卷积的,它可以有效处理一个任意大小的图像,并产出一个 2D 输出映射。映射上的每个点对应于输入图像上的一个块,并含有来自网络的预测,比如该块中是否有人脸,它在该输入块中的位置和比例(参见图 1 中 DCN 的输入和输出)。
通过这一网络,我们接着构建一个相当标准的处理通道以执行人脸检测,该通道包含一个多尺度图像金字塔、人脸检测器网络和一个后处理模块。我们需要一个多尺度金字塔处理不同大小的人脸。接着我们把这一网络应用于金字塔的每个层,并从每层中收集候选的检测(见图 2)。后处理模块接着整合这些候选检测,产出对应于网络图像人脸最后预测的一系列边界框。
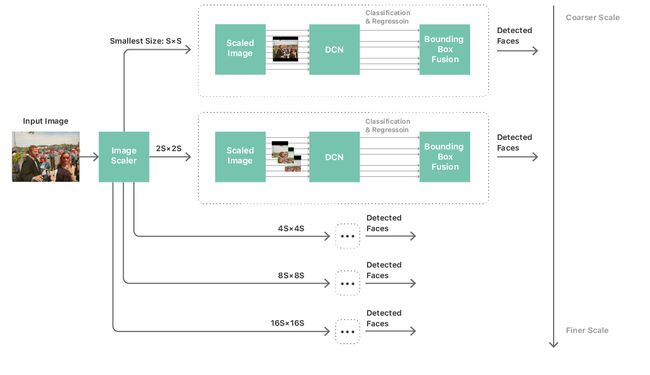
图 2. 人脸检测的工作流程
这种策略使我们能用设备内置的深度卷积网络更彻底地扫描图像。但网络复杂度和尺度仍然是制约性能的主要瓶颈。要克服这种困难意味着不仅要将网络限制为简单的拓扑结构,而且还要限制网络的层数、每一层的通道数和卷积滤波器的核的大小。这些限制导致了一个关键的问题:我们的网络在达到可接受的准确率的同时必须是简单的,至多只能有 20 多个层,且由几个 network-in-network[3] 模块组成。在我们之前描述的图像扫描框架中使用这样的网络是完全不可能的,不仅性能不足且能耗很大。实际上,我们甚至无法将把网络加载到内存上。然后,问题变成了如何训练一个简单和紧致的网络以模仿准确率高但非常复杂的网络的行为。
我们决定提出一种方法,非正式地称为「老师—学生」训练 [4]。这个方法提供了一种机制以训练另外一个窄而深的网络(「学生」),并以此尽可能匹配(之前描述的)已经训练过的大型复杂网络(「老师」)的输出。学生网络由简单而重复的 3x3 卷积和池化层组成,其架构经过了深度定制,以使我们的神经网络推理引擎达到最佳性能。(见图 1)
最后,我们现在已经开发了一种适用于设备内置执行的人脸检测的深度神经网络算法。经过多次迭代训练我们获得了在指定的应用中有足够准确率的网络模型。虽然网络已经足够准确和灵活,但要在实际中部署到几百万用户的设备中的话,还需要做大量的工作。
优化图像通道
对深度学习的切实考虑使我们决定为开发者设计一种易用的框架,称为 Vision。我们很快就意识到,优秀的算法不足以构建优秀的框架。我们需要一个高度优化的图像通道。
我们不希望开发者把精力花费在考虑缩放、颜色转换或图像来源上。人脸检测应该在无论是实时摄像头捕捉流、视频处理还是光盘或网页图像处理上都能工作得很好,不管使用何种图像表示和格式。
我们考虑了能耗和内存占用的问题,特别是在流媒体和图像捕捉上。尤其是 64M 像素全景图,其内存占用特别大。为了解决这些问题,我们在大型图像(甚至包括非典型的长宽比)的计算机视觉任务中使用了部分子采样解码(partial subsampled decoding)和自动平铺(automatic tiling)技术。
另一项挑战是色彩空间匹配。苹果有一系列广泛的色彩空间 API,但我们不希望开发者徒增色彩匹配任务的负担。Vision 框架可以处理色彩匹配,从而降低了将计算机视觉应用到 app 中的门槛。
Vision 还通过高效的处理过程和对中间图像的复用进行了优化。人脸检测、人脸基准检测和几种其它计算机视觉任务都是在相同比例的中间图像上工作的。通过为算法提取接口,和为图像或缓存分配处理的坐标,Vision 可以创建图像并把图像放入高速缓存,以提升多种计算机视觉任务的性能,而不需要开发者做任何额外工作。
另一方面也是如此。从中心接口(central interface)的角度看,我们可以把开发方向引导至更好地复用或共享中间图像。Vision 能执行多种不同且独立的计算机视觉算法。为了使不同的算法能同时顺利运行,实现中使用的输入分辨率和色彩空间将尽可能在所有的算法中共享。
优化设备内置的性能
如果我们的人脸检测 API 不能应用到实时 App 和后台系统处理中,其易用性也没有什么意义。用户们希望人脸检测能在处理他们的照片库进行面部识别的时候,或在拍摄照片后立即进行分析的时候,能够平滑地运行。他们不希望这个应用太耗电或拖慢系统运行的速度。苹果的移动设备都是多任务处理设备。因此,后台计算机视觉处理不应该显著影响系统的其余部分的功能。
我们实现了几种策略以最小化内存占用和 GPU 的使用。为了减少内存占用,我们通过分析计算图分配神经网络的中间层。这允许我们在相同的缓存中应用多种层结构。虽然内存占用是完全确定的,但这项技术能在不影响性能和不出现内存碎片的前提下降低内存占用,且可以在 CPU 和 GPU 上使用。
Vision 的检测器同时运行 5 个网络(如图 2 所示,每一个网络应用于一个图像金字塔,image pyramid scale)。这 5 个网络共享相同的权重和参数,但有不同形状的输入、输出和中间层。为了进一步减少内存占用,我们在由那 5 个网络组成的联合图(joint graph)上运行了以活跃度为基础(liveness-based)的内存优化算法,从而显著降低了内存占用。而且,多个网络复用相同的权重和参数缓存,从而降低了内存需求。
为了获得更好的性能,我们利用了网路的全卷积本质:所有的尺度都会动态地改变大小以匹配输入图像的分辨率。与拟合矩形网络视网膜(通过空白带填充)上的图像相比,将网络拟合图像的尺寸使我们能大幅度地降低总运算次数。由于运算的拓扑不随重塑尺寸改变,和分配器的剩余高性能,动态重塑不会因为分配而造成性能开销。
为了保证当深度神经网络在后台运行的时候的 UI 的灵敏度和流畅度,我们分离 GPU 工作项,并为网络的每一层分配,直到每一层的时间消耗小于 1 毫秒,使得驱动程序能及时转换到更高优先级的任务中,比如 UI 动画,从而减少甚至消除掉帧现象。综上所述,所有这些策略保证了用户可以享受本地的、低延迟的、个人深度学习推理,而没有任何性能降低的体验。
如何使用 Vision 框架
我们达成了开发一个性能优异、易于上手的人脸识别 API 的目标了吗?使用这一视觉框架之后,你自然会明白。下面是该框架的上手方法:
- 观看 WWDC 2017 大会相关演示:https://developer.apple.com/videos/play/wwdc2017/506/
- 阅读该框架的参考说明:https://developer.apple.com/documentation/vision
- 尝试 Core ML 和该框架:iOS 11 机器学习教程 [5]
参考文献
[1] Viola, P. and Jones, M.J. Robust Real-time Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the Computer Vision and Pattern Recognition Conference, 2001.
[2] Sermanet, Pierre, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, and Yann LeCun. OverFeat: Integrated Recognition, Localization and Detection Using Convolutional Networks. arXiv:1312.6229 [Cs], December, 2013.
[3] Lin, Min, Qiang Chen, and Shuicheng Yan. Network In Network. arXiv:1312.4400[Cs], December, 2013.
[4] Romero, Adriana, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. FitNets: Hints for Thin Deep Nets. arXiv:1412.6550 [Cs], December, 2014.
[5] Tam, A. Core ML and Vision: Machine learning in iOS Tutorial. Retrieved from https://www.raywenderlich.com, September, 2017.