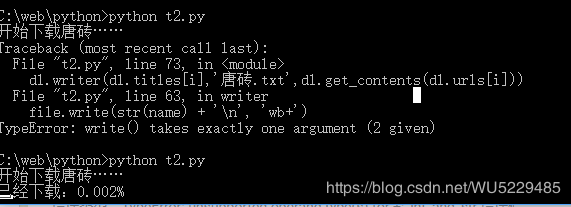
使用 python3.x爬取《唐砖》全本txt小说
最近有部很火的网剧《唐砖》,虽说编剧改了很多地方,但是单单从电视剧的角度来讲,还是很不错的,也看出了剧组和演员的用心,给一个大大的赞;于是今天心血来潮,想下本原著看看,找了个笔趣看的小说网站,发现没有小说的下载地址,这就尴尬了,所以准备用python爬一下,生成一个 " 唐砖.txt " 文件传手机上。
1. 爬取博客主页信息,生成一个网页HTML文件 (预热)
import urllib.request;
page = urllib.request.urlopen('https://blog.csdn.net/wu5229485');
htmlcode = page.read();
pageFile = open('pageCode.html','wb+'); # 以写的方式打开pageCode.html
pageFile.write(htmlcode); # 写入
pageFile.close(); # 关
print('OK!');2.安装pip工具
解决方案:https://jingyan.baidu.com/article/ff42efa9d630e5c19e220207.html
3.使用requests获取网页数据
(1)安装requests
pip install requests
中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
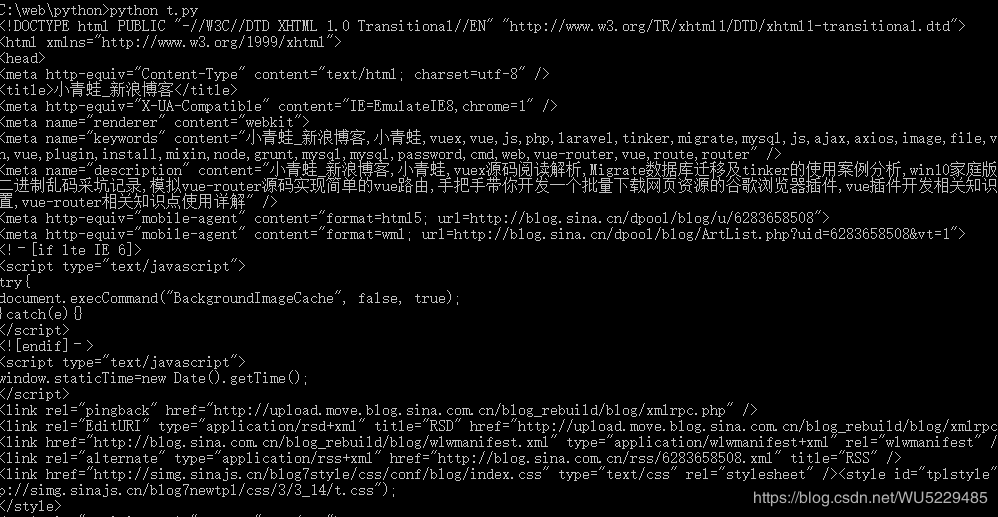
(2)使用requests获取网页HTML结构数据
import requests
if __name__ == '__main__':
target = "http://blog.sina.com.cn/riversfrog"
req = requests.get(target)
req.encoding = 'utf-8'
print(req.text);效果预览:
4. 安装beautifulsoup4爬取网页中想要获取的数据
pip install beautifulsoup4
中文文档:https://beautifulsoup.readthedocs.io/zh_CN/latest/
5. 抓取小说网单篇文章
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
target = "https://www.biqukan.com/0_219/53216.html"
req = requests.get(url=target)
req.encoding = 'GBK'
html = req.text
soup = BeautifulSoup(html,'html.parser')
content = soup.find(id='content')
print(content.text.replace('\xa0'*8,'\n\n'))效果预览:

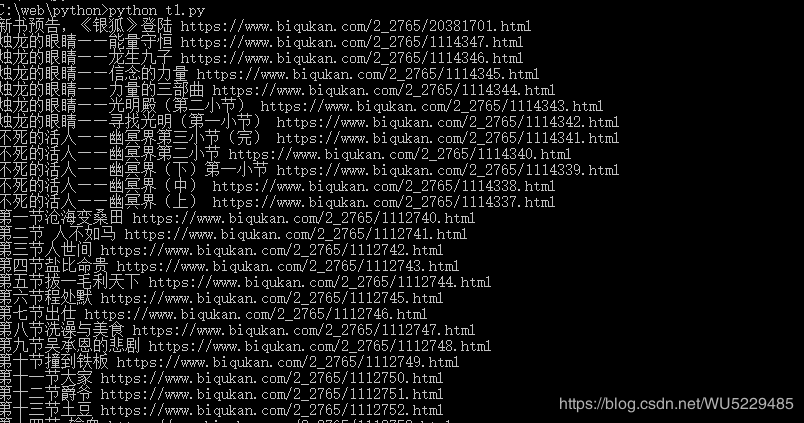
6. 抓取小说网章节目录和每章的原文链接
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
server = 'https://www.biqukan.com'
target = 'https://www.biqukan.com/2_2765/'
req = requests.get(url=target)
req.encoding = 'GBK'
html = req.text
soup = BeautifulSoup(html,'html.parser')
content = soup.find(class_ = 'listmain')
soupLink = BeautifulSoup(str(content),'html.parser')
links = soupLink.find_all('a')
for link in links:
print(link.string, server + link.get('href'))效果预览:
踩坑:
content = soup.find(class_ = 'listmain')
soupLink = BeautifulSoup(content,'html.parser')报错:
C:\web\python>python t1.py
Traceback (most recent call last):
File "t1.py", line 12, in
soupLink = BeautifulSoup(content,'html.parser')
File "C:\Users\92809\AppData\Local\Programs\Python\Python37-32\lib\site-packages\bs4\__init__.py", line 245, in __init__
markup = markup.read()
TypeError: 'NoneType' object is not callable 解决:
soupLink = BeautifulSoup(str(content),'html.parser')
7. 生成小说txt文件
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests, sys
"""
类说明: 下载 笔趣看网 小说 《 唐砖 》
Parameters:
无
Returns:
无
Modify:
2018年11月13日21点57分
"""
class downloader(object):
""" docstring for downloader """
def __init__(self):
super(downloader, self).__init__()
self.domain = 'https://www.biqukan.com' # 小说下载网的主域名
self.target = 'https://www.biqukan.com/2_2765/' # 唐砖小说的目录主页
self.titles = [] # 章节名称
self.urls = [] # 章节对应的详情链接
self.nums = 0 # 章节数
"""
函数说明:get_down_url() 获取下载链接
"""
def get_down_url(self):
req = requests.get(url=self.target)
req.encoding = 'GBK'
html = req.text
soup = BeautifulSoup(html,'html.parser')
content = soup.find(class_ = 'listmain')
soupLink = BeautifulSoup(str(content),'html.parser')
links = soupLink.find_all('a')
self.nums = len(links);
for link in links:
self.titles.append(link.string)
self.urls.append(self.domain + link.get('href'))
"""
函数说明:get_contents() 获取每章节的内容
"""
def get_contents(self, target):
req = requests.get(url=target)
req.encoding = 'GBK'
html = req.text
soup = BeautifulSoup(html,'html.parser')
content = soup.find(id='content')
texts = content.text.replace('\xa0'*8,'\n\n')
return texts
"""
函数说明: writer() 将爬取到的文章写入txt文件
"""
def writer(self,name,path,text):
write_flag = True
with open(path, 'a', encoding="utf-8") as file :
file.write(str(name) + '\n')
file.writelines(text)
file.write('\n\n')
if __name__ == '__main__':
dl = downloader()
dl.get_down_url()
print('开始下载唐砖……')
for i in range(dl.nums):
dl.writer(dl.titles[i],'唐砖.txt',dl.get_contents(dl.urls[i]))
sys.stdout.write('已经下载:%.3f%%' % float(i/dl.nums) + '\r')
sys.stdout.flush()
print('恭喜你,《唐砖》下载完成')
效果预览: