KNN手写数字识别
目录
导包
读取数据
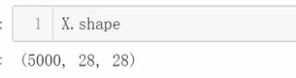
将5000张图片全部加载进来
画图显示
加载数据,处理(灰度化)
X,y划分成训练和验证数据
算法训练和预测(验证)
算法预测
提升准确率,将邻居数降为5
n-jobs提升
二值化操作
多次划分训练预测的平均准确率
导包
CV2比matplotlib加载速度快
import numpy as np
import cv2#加载图片
import matplotlib.pyplot as plt
#inline表示将图表嵌入到Notebook中
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier读取数据
# bitmap 位图
digit = cv2.imread('./data/0/0_101.bmp')
plt.imshow(digit)
#图为0

一个小方块代表一个像素,数据是三维的。将digit转换为黑白的,数据即会减小。
# 将彩色(三维的)图片转化成黑白的(图片灰度化处理):大大降低数据量
digit = cv2.cvtColor(digit,code = cv2.COLOR_BGR2GRAY)
# 原来的数据(28,28,3) [高度,宽度,像素]----------> (28,28)
# 数据量大大减少了2/3,只有原来的1/3
digit.shape![]()
# digit二维的,高度,宽度,像素(只有一个值)--------用什么颜色表示呢?
# 选择黑白,图片show就是黑白,rainbow显示出来,彩虹效果
plt.imshow(digit,cmap=plt.cm.gray)
将5000张图片全部加载进来
X = []
for i in range(10):
for j in range(1,501):#1-500
digit = cv2.imread('./data/%d/%d_%d.bmp'%(i,i,j))
X.append(digit[:,:,0])#切片
# 数据X和目标值y是一一对应
X = np.asarray(X) # 列表转换为numpy对象
y = np.array([i for i in range(10)]*500)#500个是一类 列表乘以500
y.sort()#排序
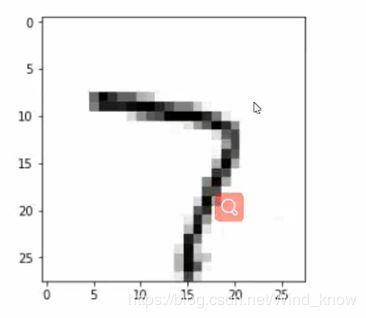
画图显示
# digit二维的,高度,宽度,像素(只有一个值)--------用什么颜色表示呢?
# 选择黑白,图片show就是黑白,rainbow显示出来,彩虹效果
index = np.random.randint(0,5000,size = 1)[0]
digit = X[index]
print('-----------------------',y[index])
plt.imshow(digit,cmap = plt.cm.gray)![]()
加载数据,处理(灰度化)
X,y划分成训练和验证数据
# 模型选择,可以打乱顺序,按照比例进行划分
from sklearn.model_selection import train_test_split
# test_size = 0.2,train_size = 0.8 百分比 random_state:
# 训练:测试= 4:1
# 一一对应的
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 100)
算法训练和预测(验证)
knn = KNeighborsClassifier(n_neighbors= 63)
knn.fit(X_train,y_train)
此时会发现报错了,
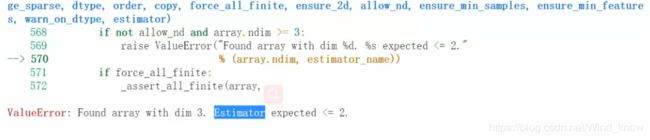
数据是三维的,算法是预估,数据不符要求,应用reshape改变形状,变成二维的。
# 数据不合要求,reshape形状改变
# 数据不变
# 三维的数据--------->变成2维
X_train = X_train.reshape(4000,-1)
X_train.shape![]()
再执行,就不报错了。

预测时也要用二维数据
X_test = X_test.reshape(1000,784)算法预测
%%time
knn = KNeighborsClassifier(n_neighbors= 63)
knn.fit(X_train,y_train)
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
y_ = knn.predict(X_test)
# 准确率
# (y_ == y_test).sum()/1000
print((y_ == y_test).mean())
提升准确率,将邻居数降为5
%%time
# 参数n_neighbors = 5告诉计算机找到最近的5个邻居
# 计算所有,找到最小的5个距离,最近的5个邻居
knn = KNeighborsClassifier(n_neighbors= 5)
knn.fit(X_train,y_train)
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
# 取出一个,找这一个5个邻居(4000个数据中)-----> 遍历------->d[:5]
# 取出一个,找这一个63个邻居(4000个数据中)-----> 遍历------>d[:63]
y_ = knn.predict(X_test)
# 准确率
# (y_ == y_test).sum()/1000
print((y_ == y_test).mean())#
由此可以看出kNN的缺点,时间和空间复杂度都比较大。
设学习和预测的数据一样
%%time
# 参数n_neighbors = 5告诉计算机找到最近的5个邻居
# 计算所有,找到最小的5个距离,最近的5个邻居
knn = KNeighborsClassifier(n_neighbors= 5)
# 算法是‘学习‘,不是死记硬背,存到数据库一样,进行一一对比
knn.fit(X_train,y_train) #算法训练(学习)4000个数据
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
# 取出一个,找这一个5个邻居(4000个数据中)-----> 遍历------->d[:5]
# 取出一个,找这一个63个邻居(4000个数据中)-----> 遍历------>d[:63]
y_ = knn.predict(X_train) #算法预测4000个数据
# 准确率是否可以100% ???
# (y_ == y_test).sum()/1000
print((y_ == y_train).mean())
n-jobs提升
knn = KNeighborsClassifier(n_neighbors= 5,n_jobs=-1)#n_jobs=-1便是使用全部的CPU![]()
算法是去学习,不是死记硬背,不是像数据库一样将数据一一对比,它是学习总结规律的过程,所以即使相同的数据去测试,准确率也不可能是100%。
index = np.random.randint(0,5000,size = 1)[0]
plt.imshow(X[index],cmap = 'gray')
二值化操作
# 二值化操作
for i in range(5000):
for y in range(28):#高
for x in range(28):#宽
if X[i][y,x] < 200:
X[i][y,x] = 0
else:
X[i][y,x] = 255
index = np.random.randint(0,5000,size = 1)[0]
plt.imshow(X[index],cmap = 'gray')
多次划分训练预测的平均准确率
y = np.array([i for i in range(10)]*500)
y.sort()
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state=100)#random_state标记状态
%%time
accuracy = 0
for i in range(30):
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2)
# 参数n_neighbors = 5告诉计算机找到最近的5个邻居
# 计算所有,找到最小的5个距离,最近的5个邻居
knn = KNeighborsClassifier(n_neighbors= 5,n_jobs=-1)
# 算法是‘学习‘,不是死记硬背,存到数据库一样,进行一一对比
knn.fit(X_train.reshape(4000,-1),y_train) #算法训练(学习)4000个数据
# 使用算法进行预测
# 保留了1000个数据,算法‘没见过‘这1000个数据
X_test = X_test.reshape(1000,784)
# 取出一个,找这一个5个邻居(4000个数据中)-----> 遍历------->d[:5]
# 取出一个,找这一个63个邻居(4000个数据中)-----> 遍历------>d[:63]
y_ = knn.predict(X_test.reshape(1000,-1)) #算法预测4000个数据
# 准确率是否可以100% ???
# (y_ == y_test).sum()/1000
accuracy += (y_ == y_test).mean()/30
print('-----------------多次划分训练预测的平均准确率:%0.3f'%(accuracy))
