数据科学课程笔记1 --- 导论
1. 与数据科学有关的相关学科包括:数据库(Database)数据挖掘(Data Mining)机器学习(Machine Learning)模式识别(Pattern Recognition)数据科学导论(Data Science)等。
其中,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学更重视理论研究,因此,统计学提供的许多技术通常都要在机器学习界进一步研究,编程有效的机器学习算法后,进入数据挖掘领域。机器学习研究往往并不把海量数据作为处理对象,因此,数据挖掘要对算法进行再改造,使得算法性能和空间占用都达到实用的地步。同时,数据挖掘还有自身独特的内容,及关联分析。数据挖掘重在发现知识,模式识别重在认识事物。机器学习的目的是建模隐藏的数据结构,然后做识别、预测、分类等。因此,机器学习是方法,模式识别是目的。
2. 数据科学的组成
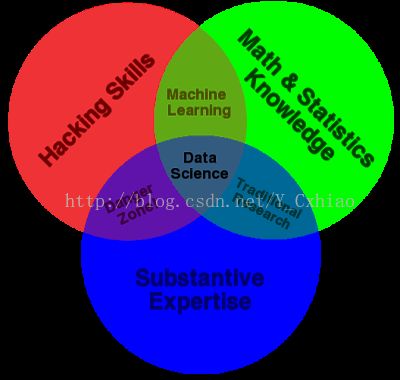
· 计算机技巧 · 数学和统计知识 · 实质性的专业知识
数据科学知识图:
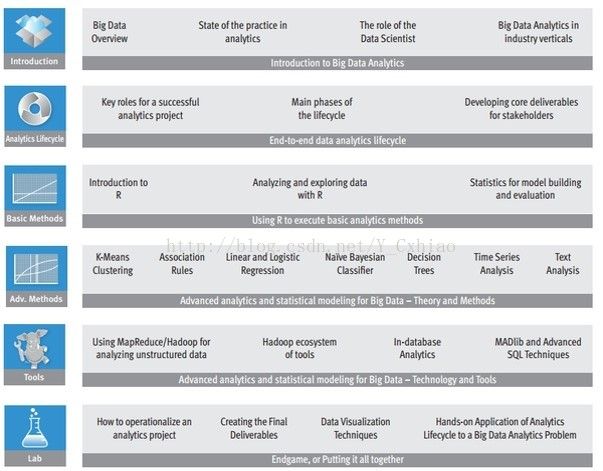
由上到下依次为:介绍、数据科学的处理过程、基本分析工具(weka 、 R 、 python)、分析方法、工程技术工具、实验和结果交付
3.数据科学中的三个重要技能:
1. 计算机能力:数据的获取和整理
· 数据整理
· 大规模数据
· 存储数据只是数据平台建设的一部分
2.数学和统计学能力:数据的挖掘
· 机器学习是另一项必不可少的工具
· 统计是“数据科学的语法”
· 一个不可或缺的语言工具(R 或 Python)
3. 图形可视化:数据的提炼和展现
· 展现的不仅仅是结果,还包括贯穿过程的分析过程可视化、挖掘结果可视化等。
· why可视化: 对于人来说,知识最重要。而人类最容易学习到的知识就是图形。
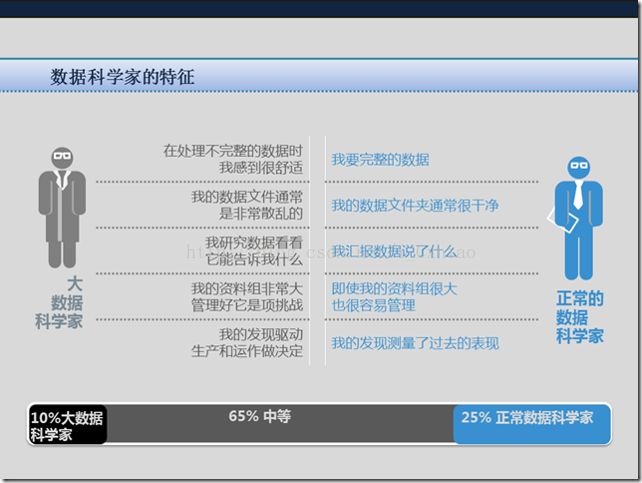
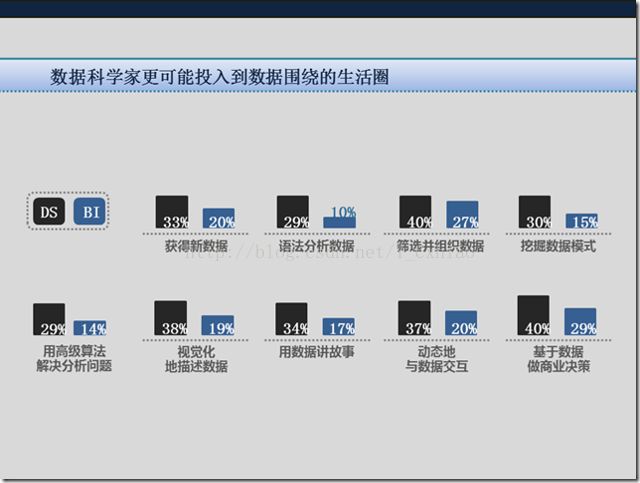
大数据分析:数据稀疏度高、善于处理不完整的数据
数据处理:多源异构交叉分析
得到结果:数据说明了什么
数据量:海量
4.大数据的数据源
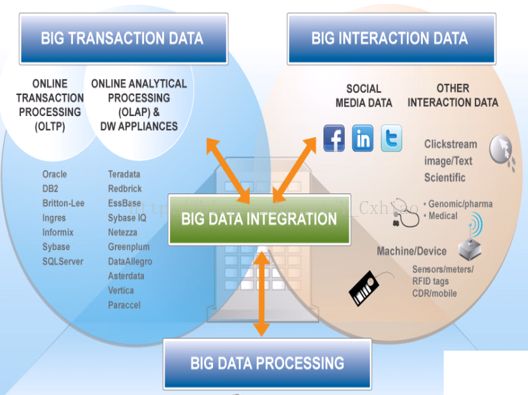
大数据包括:交易数据和交互数据集在内的所有数据集
大数据 = 海量数据 + 复杂类型的数据
· 海量交易数据:企业内部的经营交易信息,主要包括联机交易数据和联机分析数据,是结构化的、通古关系数据库进行管理和访问的静态、历史数据。通过这些数据,我们可以了解到过去发生了什么
· 海量交互数据:源于Facebook、Twitter、LinkedIn及其他来源的社交媒体数据构成。它包括了呼叫详细记录CDR、设备和传感器信息、GPS和地理定位映射数据、通过管理文件和传输Manage File Transfer协议传送的海量图像文件、Web文本和点击流数据、科学信息、电子邮件等。可以告诉我们未来会发生什么
· 海量数据处理:大数据的涌现已经催生出了设计用于数据密集型处理的架构。例如具有开放源码、在商品硬件群中运行的Apache Hadoop
· 大数据技术:图像、音频、视频、非结构化、社交关系数据处理技术商
· 现有IT系统改造商:大数据咨询公司、集成商、ERP、商务智能、客户关系管理系统
· 终端提供商向数据提供商演进:对现有客户数据的深度把握、建立客户之间的社交和联系
即 文字作为数据、位置作为数据、沟通作为数据、量化一切
5. 大数据是互联网及其延伸导致的“自然现象”
大数据源于 信息技术的不断廉价化 与 互联网及其延伸所带来的 无所不在的信息技术应用,源于 摩尔定律驱动的指数增长模式 ,源于 技术低成本驱动的万物数字化, 源于 宽带移动泛在互联驱动的人机物广泛链接, 源于 云计算模式驱动的数据大规模汇聚
6.大数据的定义
大数据的4个基本特征(4V):
数量(Volume),即数据巨大,从TB级别跃升到PB级别;
· 非结构化数据的 超大规模和增长
· 比结构化数据增长快10倍到50倍
· 是传统数据仓库的10倍到50倍
· 总数据量的80%~90%
多样性(Variety),即数据类型繁多,不仅包括传统的格式化数据,还包括来自互联网的网络日志、视频、图片、地理位置信息等;
· 大数据的异构和多样性
· 很多不同形式
· 无模式或者模式不明显
· 不连贯的语法或句义
价值密度(Value),即高质量的数据;
· 大量的不相关信息
· 对未来趋势和模式的可预测分析
· 深度复杂分析(机器学习、人工智能 / 传统商务智能(咨询、报告等))
速度(Velocity),即快速处理。2方面含义:数据增长速度快 、 数据处理速度快(实时)
· 实时分析而非批量式分析
· 数据输入、处理与丢弃
· 立竿见影而非事后奏效
价值密度低,是大数据的一个典型特征
能够在不同的数据类型中,进行交叉分析的技术,是大数据的核心技术之一。(如语义分析技术、图文转换技术、模式识别技术等)
对于数据处理速度而言,1s是临界点。对于大数据应用而言,必须要在1秒钟内形成答案,否则处理结果就是过时和无效的。
实时处理的要求,是区别大数据引用和传统数据仓库技术、BI技术的关键差别之一。(BI技术:Business Intelligence 商业智能。使用基于事实的决策支持系统,来改善业务决策的一套理论与方法。数据仓库、OLAP和数据挖掘等技术的综合运用。)


大数据时代的思维变革:更多、更杂、更好。
更多:不是随机样本,而是全体数据
· 实现采样的随机性非常困难
· 随机采样的方法不适用于更深层次的细分领域情况
· 人们只能从采样数据中的初试线设计好的问题结果
· 小数据时代的随机采样,最少的数据获得最多的信息
· 全数据模式,样本 = 总体
更杂:不是精确性,而是混杂性
· 对小数据而言,最重要的要求是减少错误。而在大数据的采集里,在技术尚未到达完美无缺之前,混乱是不可避免的。虽然信息可能不完全准确,但收集到的数量庞大的信息让我们放弃严格精确的选择变得划算
· 允许不精确
· 大数据的简单算法比小数据的复杂算法更有效
· 纷繁的数据越多越好
· 混杂性,不是竭力避免,而是标准途径
更好:不是因果关系,而是相关关系
· 大数据时代最大的转变就是,放弃对因果关系的渴求,而转而关注相关关系。即只要知道“是什么”,而不需要知道“为什么”
· 大数据时代改变人们探索世界的方法