〖TensorFlow2.0笔记24〗生成式对抗网络(GAN)原理讲解以及实战!
| 生成式对抗网络(GAN)原理讲解以及实战! |
文章目录
- 一. 判别式模型和生成式模型
- 二. 生成式对抗网络(GAN)原理讲解
- 2.1. 生成对抗网络-现实世界的启发
- 2.2. 生成对抗网络的原理
- 2.3. 生成对抗网络的训练
- 2.3.1. 生成对抗网络的目标函数
- 2.3.2. 判别模型的目标函数
- 2.3.3. 生成模型的目标函数
- 2.4. 纳什均衡
- 2.4.1. 判别器状态
- 2.4.2. 生成器状态
- 2.4.3. 纳什均衡点
- 2.5. 生成对抗网络的实现
- 三. 生成式对抗网络(GAN)实战
- 3.1. GAN的训练稳定性
- 四. 如何理解转置卷积(反卷积)
- 4.1. 普通卷积理解动画
- 4.2. 普通卷积深入理解
- 4.3. 转置卷积深入理解
- 4.4. 形象化的转置卷积
- 4.5. 转置卷积动画演示
- 参考文章及推荐
一. 判别式模型和生成式模型
开始之前可以先看一下我之前的文章: 2.6. 判别式模型和生成式模型,更仔细点!
深度学习模型大概可以分为如下两类:
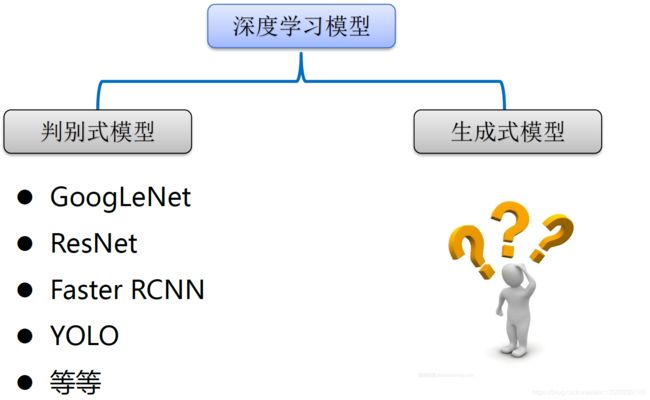
注意: 目前深度学习取得的成果主要集中在判别式模型,所谓的判别式模型就是:将一个高维的感官输入(比如图像)映射为类别标签,它是属于车还是人之类的,这些判别式模型主要归功于反向传播理论。相比之下生成式模型进展缓慢一些。
这里:生成式模型的研究意义如下:
- ① 是对我们处理高维数据和复杂概率分布能力很好的检测。
- ② 当面临缺乏数据或失数据时,我们可以通过生成模型来补足。 比如,用在半监督学习中。因为现在我们取得的很好性能里面,其实很多都是基于监督学习的,这就需要很多良好的标注的样本的,那么经常并没有那么多的样本,怎么生成一些样本,弥补这个不足。
- ③ 可以输出多模态(multimodal multimodal)等等。
还有一些其它生成式模型(这些方法都有明显的缺点:计算复杂度高。这节将的GAN就是克服了这一点):
- ① 最大似然估计: 以真实样本进行最大似然估计,参数更新直接来自于样本数据,导致学习到的生成模型收到限制。
- ② 近似法: 由于目标函数难解一般只能在学习过程中逼近目标函数的下界,并不是对目标函数逼近。
- ③ 马尔科夫链: 计算复杂度高。
- ④ 等等!
生成式模型方法介绍:
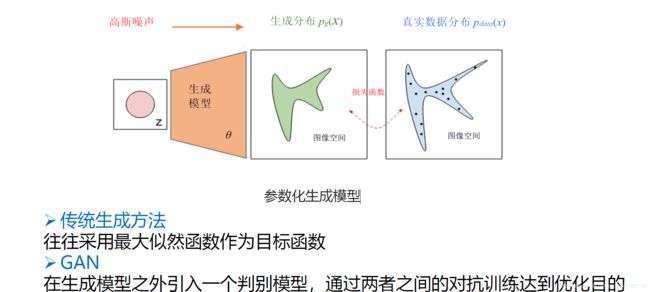
这里: 因为GAN是生成式模型的一种,这里介绍下生成式方法,上面这幅图右边每个小黑点表示真实分布的一个数据点(比如图像),蓝色轮廓表示以高概率包含了真实图像的一个图像样本空间,生成式模型就是将高斯噪声矢量映射为一个生成概率分布,使得这个生成概率分布尽量和真实数据分布相一致(例如,使得KL散度 最小)。简言之就是逐渐撑开图中中间绿色的区域使得绿色区域形状逐渐逼近右边真实的蓝色区域的形状,最终使得他们一样,这就是最终优化的目的。
这里: 在这个优化过程中传统的生成式方法往往采用最大似然函数作为目标函数(存在计算复杂度高问题)。然而GAN在生成模型之外引入一个判别模型,通过二者之间的对抗训练达到优化目的。
二. 生成式对抗网络(GAN)原理讲解
2.1. 生成对抗网络-现实世界的启发
什么是生成对抗网络,我们知道现实世界中名人的真迹字画往往会存在一些仿制的赝品,例如下图第一行为真迹,第二行为赝品,因此有一种工作叫做鉴定师,判断哪些是真迹,哪些是赝品,仿制者和鉴定师之间构成了博弈。为了更好的鉴定真伪,鉴定师不断学习。而仿制者为了达到以假乱真的目的,也要不断的学习。所以双方水平的提高,都有助于提高彼此的水平。
2.2. 生成对抗网络的原理
生成对抗网络(Generative Adversarial Network,GAN)属于生成式模型的一种,由Ian Goodfellow 2014年首先提出,此后到今天成为了深度学习中最热门的研究方向之一。

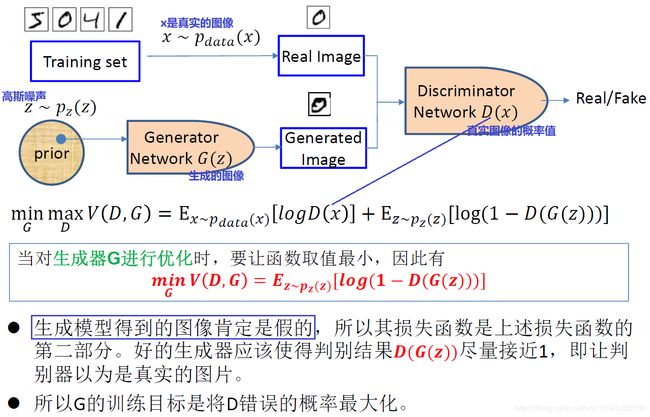
这里: 生成网络G的输入是一个来自常见概率分布的随机噪声矢量 z \boldsymbol z z(随机噪声通常从均匀分布或高斯分布中获取),经过神经网络生成一张图片;判别网络D的输入是图片一张图片 x \boldsymbol x x,但是 x \boldsymbol x x 来源有两种可能,可能是真实图片也可能是刚刚判别其生成的假的图像 z \boldsymbol z z,判别网络D的输出是一个标量(0到1之间的数),用来代表 x \boldsymbol x x 是真实图片的概率,真为1,假为0。
为什么GAN的性能这么强大呢? GAN的核心思想来源于博弈论的纳什均衡,它设定参与游戏双方分别为一个生成器和一个判别器,生成器的目的是尽量去学习真实的数据分布,而判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器(对于真实图像输出1,对于判别器生成的假图像输出0);为了取得游戏胜利,两个参与者需要不断优化,各自提高自己的生成能力和判别能力,这个学习的优化过程就是寻找二者之间的一个纳什均衡。
2.3. 生成对抗网络的训练
开始之前可以先看一下我之前的文章: 信息量、信息熵、交叉熵、KL散度(相对熵)、JS散度以及逻辑损失!
2.3.1. 生成对抗网络的目标函数
GAN的优化问题是一个极小-极大化问题,GAN的目标函数:
min G max D V ( D , G ) (1) \min _{G} \max _{D} V(D, G)\tag{1} GminDmaxV(D,G)(1) V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E x ∼ p g ( x ) [ log ( 1 − D ( x ) ) ] (2) \begin{aligned} V(D, G)&= \mathrm{E}_{ x \sim p_{data}(x)}[\log D( x)]+ E_{ z \sim p_{ z}( z)}[\log (1-D(G( z)))] \\ &= \mathrm{E}_{x \sim p_{data}(x)}[\log D( x)]+ E_{x \sim p_{ g}( x)}[\log (1-D(x))] \end{aligned} \tag{2} V(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]=Ex∼pdata(x)[logD(x)]+Ex∼pg(x)[log(1−D(x))](2)其中: x x x 采样于真实数据分布 p d a t a ( x ) p_{data}(x) pdata(x), z z z 采样于先验分布 p z ( z ) p_{z}(z) pz(z)(例如高斯噪声)。 其实和一般的基于sigmoid二分类模型一样,我们只需要最下化它的交叉熵。因为这个判别网路要做的就是对这个对象分类,只不过这里不像Resnet那样1000个类,这里就是一个二分类,判断图像是真还是假(最后只有一个神经元)。
注意: 在连续空间上,期望可以写成积分的形式,此时上式 ( 2 ) (2) (2)可以写成:
V ( D , G ) = ∫ x p d a t a ( x ) log ( D ( x ) ) d x + ∫ z p z ( z ) log ( 1 − D ( g ( z ) ) ) d z = ∫ x [ p d a t a ( x ) log ( D ( x ) ) + p g ( x ) log ( 1 − D ( x ) ) ] d x (3) \begin{aligned} V(D, G)&=\int_{x} p_{data}(x) \log (D({x})) d x+\int_{ z} p_{{z}}({z}) \log (1-D(g({z}))) d z \\ &= \int_{ x}\left[p_{data}(x) \log (D( x)) +p_{g}( x) \log (1-D( x))\right] d x \end{aligned} \tag{3} V(D,G)=∫xpdata(x)log(D(x))dx+∫zpz(z)log(1−D(g(z)))dz=∫x[pdata(x)log(D(x))+pg(x)log(1−D(x))]dx(3) 上式在
D G ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) (4) D_{G}^{*}( x)=\frac{p_{d a t a}( x)}{p_{d a t a(x)}+p_{g(x)}}\tag{4} DG∗(x)=pdata(x)+pg(x)pdata(x)(4)
处取得最小值,此处即是判别器的最优解。 由此可知,GAN估计的是两个概率分布密度的比值,这也是和其他基于下界优化或者马尔科夫链方法的关键不同之处。
采用交替优化的方法:
- ① 先保持生成器 G G G 不变,优化(或者叫训练)判别器 D D D,使得 D D D 的判别准确率最大化(提升鉴别器的鉴别能力)。
- ② 再保持判别器 D D D 不变,优化生成器 G G G,使得判别准确率最小化(让鉴别器鉴别不出来真假)。
- 当且仅当 p d a t a = p g p_{data}=p_g pdata=pg时,达到全局最优。
2.3.2. 判别模型的目标函数

判别模型的目标函数可以这样理解: 对于判别网络 D D D,它的目标是能够很好地分辨出真样本 x x x 与假样本 G ( z ) G(z) G(z)。以图片生成为例。它的目标是最小化图片的预测值和真实值之间的交叉熵损失函数:
min θ L = CrossEntropy ( D θ ( x ) , y x , D θ ( D ( x ) ) , y z ) (5) \min _{\theta} \mathcal{L}=\operatorname{CrossEntropy}\left(D_{\theta}\left({x}\right), y_{x}, D_{\theta}\left(D(x)\right), y_{z}\right) \tag{5} θminL=CrossEntropy(Dθ(x),yx,Dθ(D(x)),yz)(5) 其中: D θ ( x ) D_{\theta}({x}) Dθ(x) 表示真实样本 x x x 在判别网络 D θ D_{\theta} Dθ 的输出, θ \theta θ 为判别网络的参数集, D θ ( G ( z ) ) D_{\theta}({G(z)}) Dθ(G(z)) 为生成样本 z z z 在判别网络的输出, y x y_{x} yx 为 x x x 的标签,由于真实样本标注为真,故 y x = 1 y_{x}=1 yx=1, y z y_{z} yz 为生成样本 z z z 的标签,由于生成样本标注为假,故 y z = 0 y_{z}=0 yz=0。二分类问题的交叉熵损失函数定义为:
L = − ∑ x ∼ p d a t a ( x ) log D θ ( x ) − ∑ z ∼ p z ( z ) log ( 1 − D θ ( G ( z ) ) ) (6) \mathcal{L}=-\sum_{x \sim p_{data}(x)} \log D_{\theta}\left(x\right)-\sum_{z \sim p_{ z}( z)} \log \left(1-D_{\theta}\left(G(z)\right)\right) \tag{6} L=−x∼pdata(x)∑logDθ(x)−z∼pz(z)∑log(1−Dθ(G(z)))(6) 因此判别网络 D D D 的优化目标是: θ ∗ = argmin θ [ − ∑ x ∼ p d a t a ( x ) log D θ ( x ) − ∑ z ∼ p z ( z ) log ( 1 − D θ ( G ( z ) ) ) ] (7) \theta^*=\underset{\theta}{\operatorname{argmin}}\left[-\sum_{x \sim p_{data}(x)} \log D_{\theta}\left(x\right)-\sum_{z \sim p_{ z}( z)} \log \left(1-D_{\theta}\left(G(z)\right)\right)\right] \tag{7} θ∗=θargmin⎣⎡−x∼pdata(x)∑logDθ(x)−z∼pz(z)∑log(1−Dθ(G(z)))⎦⎤(7) 把 min θ L \min _{\theta} \mathcal{L} minθL 问题转换为 max θ − L \max _{\theta}-\mathcal{L} maxθ−L,即
min θ L = max θ − L (8) \min _{\theta} \mathcal{L}=\max _{\theta} -\mathcal{L} \tag{8} θminL=θmax−L(8) 写成期望形式:
L = E x ∼ p d a t a ( x ) [ log D θ ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D θ ( G ( z ) ) ) ] = E x ∼ p d a t a ( x ) [ log D θ ( x ) ] + E x ∼ p g ( x ) [ log ( 1 − D θ ( x ) ) ] (9) \begin{aligned} \mathcal{L}&= \mathrm{E}_{ x \sim p_{data}(x)}[\log D_{\theta}( x)]+ \mathrm{E}_{ z \sim p_{ z}( z)}[\log (1-D_{\theta}(G( z)))] \\ &= \mathrm{E}_{x \sim p_{data}(x)}[\log D_{\theta}( x)]+ \mathrm{E}_{x \sim p_{ g}( x)}[\log (1-D_{\theta}(x))] \end{aligned} \tag{9} L=Ex∼pdata(x)[logDθ(x)]+Ez∼pz(z)[log(1−Dθ(G(z)))]=Ex∼pdata(x)[logDθ(x)]+Ex∼pg(x)[log(1−Dθ(x))](9)
2.3.3. 生成模型的目标函数
注意: 因为目标函数的第一项不包含 G G G,是常数,所以可以直接忽略不受影响。
生成器 G G G 的损失函数(就是判别器损失函数前面取负号,因为生成器和判别器它们之间的训练是一个二元零和博弈,博弈双方的利益就是零,也就是一方的多得就是另一方的所失。所以这里前面加一个负号就得到了生成器G的损失函数),其实也就是最小化和最大化之间差了一个负号的关系:
O b j G = − O b j D (10) Obj^{G}=-Obj^{D}\tag{10} ObjG=−ObjD(10)
生成模型的目标函数可以这样理解: 对于生成网络 G ( z ) G(z) G(z),我们希望 G ( z ) G(z) G(z) 能够很好地骗过判别网络 D D D,假样本 G ( z ) G(z) G(z) 在判别网络的输出越接近真实的标签越好。也就是说,在训练生成网络时,希望判别网络的输出 D ( G ( z ) ) ) D(G( z))) D(G(z))) 越逼近1 越好,最小化 D ( G ( z ) ) ) D(G( z))) D(G(z))) 与 1 1 1 之间的交叉熵损失函数:
min ϕ L = CrossEntropy ( D ( G ϕ ( z ) ) , 1 ) = − log D ( G ϕ ( z ) ) (11) \min _{\phi} \mathcal{L}=\operatorname{CrossEntropy}\left(D\left(G_{\phi}({z})\right), 1\right)=-\log D\left(G_{\phi}(\mathbf{z})\right)\tag{11} ϕminL=CrossEntropy(D(Gϕ(z)),1)=−logD(Gϕ(z))(11)其中: ϕ \phi ϕ 为生成网络的参数集。把 min ϕ L \min _{\phi} \mathcal{L} minϕL 问题转换为 max ϕ − L \max _{\phi}-\mathcal{L} maxϕ−L,即
min ϕ L = max ϕ − L (12) \min _{\phi} \mathcal{L}=\max _{\phi}-\mathcal{L}\tag{12} ϕminL=ϕmax−L(12) 并写成期望形式:
ϕ ∗ = argmax ϕ [ E z ∼ p z ( z ) log D ( G ϕ ( z ) ) ] (13) \phi^{*}=\underset{\phi}{\operatorname{argmax}} \left[\mathrm{E}_{{z} \sim p_{z}(z)} \log D\left(G_{\phi}({z})\right)\right]\tag{13} ϕ∗=ϕargmax[Ez∼pz(z)logD(Gϕ(z))](13)再次等价转化为: ϕ ∗ = argmin ϕ [ E z ∼ p z ( z ) log D ( 1 − G ϕ ( z ) ) ] (14) \phi^{*}=\underset{\phi}{\operatorname{argmin}} \left[\mathrm{E}_{{z} \sim p_{z}(z)} \log D\left(1-G_{\phi}({z})\right)\right]\tag{14} ϕ∗=ϕargmin[Ez∼pz(z)logD(1−Gϕ(z))](14)
2.4. 纳什均衡
现在从理论层面进行分析,通过博弈学习的训练方式,生成器 G G G 和判别器 D D D 分别会达到什么平衡状态。具体地,我们将探索以下两个问题:
- ①. 固定 G G G, D D D 会收敛到什么最优状态 D ∗ D^* D∗ ?
- ②. 在 D D D 达到最优状态 D ∗ D^* D∗ 后, G G G 会收敛到什么状态?
2.4.1. 判别器状态
判别器状态: 回顾GAN的损失函数:
L ( G , D ) = ∫ x p d a t a ( x ) log ( D ( x ) ) d x − ∫ z p z ( z ) log ( 1 − D ( g ( z ) ) ) d z = ∫ x [ p d a t a ( x ) log ( D ( x ) ) + p g ( x ) log ( 1 − D ( x ) ) ] d x (15) \begin{aligned} \mathcal{L}\left(G, D\right) &=\int_{x} p_{data}(x) \log (D({x})) d x-\int_{ z} p_{{z}}({z}) \log (1-D(g({z}))) d z \\ &= \int_{ x}\left[p_{data}(x) \log (D( x)) +p_{g}( x) \log (1-D( x))\right] d x \end{aligned} \tag{15} L(G,D)=∫xpdata(x)log(D(x))dx−∫zpz(z)log(1−D(g(z)))dz=∫x[pdata(x)log(D(x))+pg(x)log(1−D(x))]dx(15) 对于判别器 D D D,优化的目标是最大化 L ( G , D ) \mathcal{L}\left(G, D\right) L(G,D)函数,需要找出如下函数的最大值,其中 θ \theta θ 为判别器 D D D 的网络参数:
f θ = p d a t a ( x ) log ( D ( x ) ) + p g ( x ) log ( 1 − D ( x ) ) (16) f_{\theta}=p_{data}(x) \log (D(x)) +p_{g}(x) \log (1-D(x))\tag{16} fθ=pdata(x)log(D(x))+pg(x)log(1−D(x))(16)
我们来考虑 f θ f_{\theta} fθ 更通用的函数的最大值情况: f ( x ) = A log x + B log ( 1 − x ) (17) f(x)=A \log x+B \log (1- x)\tag{17} f(x)=Alogx+Blog(1−x)(17) 要求得函数 f ( x ) f(x) f(x) 的最大值。考虑 f ( x ) f(x) f(x) 的导数: d f ( x ) d x = A 1 ln 10 1 x − B 1 ln 10 1 1 − x = 1 ln 10 ( A x − B 1 − x ) = 1 ln 10 A − ( A + B ) x x ( 1 − x ) (18) \begin{aligned} \frac{\mathrm{d} f(x)}{\mathrm{d} x}&=A \frac{1}{\ln 10} \frac{1}{x}-B \frac{1}{\ln 10} \frac{1}{1-x} \\ &= \frac{1}{\ln 10}\left(\frac{A}{x}-\frac{B}{1-x}\right)\\ &=\frac{1}{\ln 10} \frac{A-(A+B) x}{x(1-x)} \end{aligned} \tag{18} dxdf(x)=Aln101x1−Bln1011−x1=ln101(xA−1−xB)=ln101x(1−x)A−(A+B)x(18) 令 d f ( x ) d x = 0 \frac{\mathrm{d} f(x)}{\mathrm{d} x}=0 dxdf(x)=0,我们可以求得 f ( x ) f(x) f(x) 函数的极值点 x = A A + B (19) x=\frac{A}{A+B}\tag{19} x=A+BA(19) 因此,可以得知, f θ f_{\theta} fθ 函数的极值点同样为: D θ = p d a t a ( x ) p d a t a ( x ) + p g ( x ) (20) D_{\theta}=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)}\tag{20} Dθ=pdata(x)+pg(x)pdata(x)(20) 也就是说,判别器网络 D θ D_{\theta} Dθ 处于 D θ ∗ D_{\theta ^*} Dθ∗ 状态时, f θ f_{\theta} fθ 函数取得最大值, L ( G , D ) \mathcal{L}\left(G, D\right) L(G,D) 函数也取得最大值。
现在回到最大化 L ( G , D ) \mathcal{L}\left(G, D\right) L(G,D) 的问题, L ( G , D ) \mathcal{L}\left(G, D\right) L(G,D) 的最大值点在: D ∗ = A A + B = p d a t a ( x ) p d a t a ( x ) + p g ( x ) (21) D^{*}=\frac{A}{A+B}=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)}\tag{21} D∗=A+BA=pdata(x)+pg(x)pdata(x)(21) 此时也是 D θ D_{\theta} Dθ 的最优状态 D θ ∗ D_{\theta ^*} Dθ∗。
2.4.2. 生成器状态
开始之前可以先看一下我之前的文章,看一下JS散度:信息量、信息熵、交叉熵、KL散度(相对熵)、JS散度以及逻辑损失!
我们先介绍一下与KL散度类似的另一个分布距离度量标准:JS 散度,它定义为KL 散度的组合,首先给出DS散度: D K L ( p ∥ q ) = ∫ x p ( x ) log p ( x ) q ( x ) d x (22) D_{K L}(p \| q)=\int_{x} p(x) \log \frac{p(x)}{q(x)} d x\tag{22} DKL(p∥q)=∫xp(x)logq(x)p(x)dx(22) 然后再给出DS散度: D J S ( p ∥ q ) = 1 2 D K L ( p ∥ p + q 2 ) + 1 2 D K L ( q ∥ p + q 2 ) (23) D_{J S}(p \| q)=\frac{1}{2} D_{K L}\left(p \| \frac{p+q}{2}\right)+\frac{1}{2} D_{K L}\left(q \| \frac{p+q}{2}\right)\tag{23} DJS(p∥q)=21DKL(p∥2p+q)+21DKL(q∥2p+q)(23) 其中: JS 散度克服了KL散度不对称的缺陷
当 D θ D_{\theta} Dθ 达到最优状态 D θ ∗ D_{\theta ^*} Dθ∗时, 我们来考虑此时 p d a t a p_{data} pdata 和 p g p_{g} pg 的JS 散度:
D J S ( p d a t a ∥ p g ) = 1 2 D K L ( p d a t a ∥ p d a t a + p g 2 ) + 1 2 D K L ( p g ∥ p d a t a + p g 2 ) (24) D_{J S}\left(p_{data} \| p_{g}\right)=\frac{1}{2} D_{K L}\left(p_{data} \| \frac{p_{data}+p_{g}}{2}\right)+\frac{1}{2} D_{K L}\left(p_{g} \| \frac{p_{data}+p_{g}}{2}\right)\tag{24} DJS(pdata∥pg)=21DKL(pdata∥2pdata+pg)+21DKL(pg∥2pdata+pg)(24) 根据 KL 散度的定义展开为:
D J S ( p d a t a ∥ p g ) = 1 2 ( log 2 + ∫ x p d a t a ( x ) log p d a t a ( x ) p d a t a ( x ) + p g ( x ) d x ) + 1 2 ( log 2 + ∫ x p g ( x ) log p g ( x ) p d a t a ( x ) + p g ( x ) d x ) (25) \begin{aligned} D_{J S}\left(p_{data} \| p_{g}\right) &=\frac{1}{2}\left(\log 2+\int_{x} p_{data}(x) \log \frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} d x\right) \\&+\frac{1}{2}\left(\log 2+\int_{x} p_{g}(x) \log \frac{p_{g}(x)}{p_{data}(x)+p_{g}(x)} d x\right) \end{aligned}\tag{25} DJS(pdata∥pg)=21(log2+∫xpdata(x)logpdata(x)+pg(x)pdata(x)dx)+21(log2+∫xpg(x)logpdata(x)+pg(x)pg(x)dx)(25) 合并常数项可得:
D J S ( p d a t a ∥ p g ) = 1 2 ( log 4 ) + 1 2 ( ∫ x p d a t a ( x ) log p d a t a ( x ) p d a t a ( x ) + p g ( x ) d x + ∫ x p g ( x ) log p g ( x ) p d a t a ( x ) + p g ( x ) d x ) (26) \begin{aligned} D_{J S}\left(p_{data} \| p_{g}\right) &=\frac{1}{2}(\log 4) +\frac{1}{2}\left(\int_{x} p_{data}(x) \log \frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} d x+\int_{x} p_{g}(x) \log \frac{p_{g}(x)}{p_{data}(x)+p_{g}(x)} d x\right) \end{aligned}\tag{26} DJS(pdata∥pg)=21(log4)+21(∫xpdata(x)logpdata(x)+pg(x)pdata(x)dx+∫xpg(x)logpdata(x)+pg(x)pg(x)dx)(26) 考虑在判别网络到达 D θ ∗ D_{\theta ^*} Dθ∗时,此时的损失函数为:
L ( G , D ∗ ) = ∫ x p d a t a ( x ) log ( D ∗ ( x ) ) + p g ( x ) log ( 1 − D ∗ ( x ) ) d x = ∫ x p d a t a ( x ) log p d a t a ( x ) p d a t a ( x ) + p g ( x ) d x + ∫ x p g ( x ) log p g ( x ) p d a t a ( x ) + p g ( x ) d x (27) \begin{aligned} \mathcal{L}\left(G, D^{*}\right) &=\int_{x} p_{data}(x) \log \left(D^{*}(x)\right)+p_{g}(x) \log \left(1-D^{*}(x)\right) d x \\&=\int_{x} p_{data}(x) \log \frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} d x+\int_{x} p_{g}(x) \log \frac{p_{g}(x)}{p_{data}(x)+p_{g}(x)} d x \end{aligned}\tag{27} L(G,D∗)=∫xpdata(x)log(D∗(x))+pg(x)log(1−D∗(x))dx=∫xpdata(x)logpdata(x)+pg(x)pdata(x)dx+∫xpg(x)logpdata(x)+pg(x)pg(x)dx(27) 因此在判别网络到达 D θ ∗ D_{\theta ^*} Dθ∗时, D J S ( p d a t a ∥ p g ) D_{J S}\left(p_{data} \| p_{g}\right) DJS(pdata∥pg) 和 L ( G , D ∗ ) \mathcal{L}\left(G, D^{*}\right) L(G,D∗) 满足关系:
D J S ( p d a t a ∥ p g ) = 1 2 ( log 4 + L ( G , D ∗ ) ) (28) D_{J S}\left(p_{data} \| p_{g}\right)=\frac{1}{2}\left(\log 4+\mathcal{L}\left(G, D^{*}\right)\right)\tag{28} DJS(pdata∥pg)=21(log4+L(G,D∗))(28) 即:
L ( G , D ∗ ) = 2 D J S ( p d a t a ∥ p g ) − 2 log 2 (29) \mathcal{L}\left(G, D^{*}\right)=2 D_{J S}\left(p_{data} \| p_{g}\right)-2 \log 2\tag{29} L(G,D∗)=2DJS(pdata∥pg)−2log2(29)
对于生成网络 G G G 而言,训练目标是 min G L ( G , D ∗ ) \min _{G} \mathcal{L}(G, D^{*}) minGL(G,D∗),考虑到JS 散度具有性质:
D J S ( p d a t a ∥ p g ) ≥ 0 (30) D_{J S}\left(p_{data} \| p_{g}\right) \geq 0\tag{30} DJS(pdata∥pg)≥0(30)因此 L ( G , D ∗ ) \mathcal{L}(G, D^{*}) L(G,D∗) 取得最小值仅在 D J S ( p d a t a ∥ p g ) = 0 D_{J S}\left(p_{data} \| p_{g}\right) = 0 DJS(pdata∥pg)=0 时(此时 p d a t a = p g p_{data} =p_{g} pdata=pg), L ( G , D ∗ ) \mathcal{L}(G, D^{*}) L(G,D∗) 取得最小值: L ( G ∗ , D ∗ ) = − 2 log 2 (31) \mathcal{L}\left(G^{*}, D^{*}\right)=-2 \log 2\tag{31} L(G∗,D∗)=−2log2(31) 此时生成网络 G ∗ G^{*} G∗ 的状态是:
p g = p d a t a (32) p_{g}=p_{data}\tag{32} pg=pdata(32) 即 G ∗ G^{*} G∗ 学到的分布 p g p_{g} pg 与真实分布 p r p_{r} pr 一致,网络达到平衡点,此时: D ∗ = p d a t a ( x ) p d a t a ( x ) + p g ( x ) = 0.5 (33) D^{*}=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)}=0.5\tag{33} D∗=pdata(x)+pg(x)pdata(x)=0.5(33)
2.4.3. 纳什均衡点
通过上面的推导,我们可以总结出生成网络G 最终将收敛到真实分布,即: p g = p d a t a (34) p_{g}=p_{data}\tag{34} pg=pdata(34)此时生成的样本与真实样本来自同一分布,真假难辨,在判别器中均有相同的概率判定为真或假,即 D ( ⋅ ) = 0.5 (35) D(\cdot)=0.5\tag{35} D(⋅)=0.5(35)
此时损失函数为
L ( G ∗ , D ∗ ) = − 2 log 2 (36) \mathcal{L}\left(G^{*}, D^{*}\right)=-2 \log 2\tag{36} L(G∗,D∗)=−2log2(36)
2.5. 生成对抗网络的实现
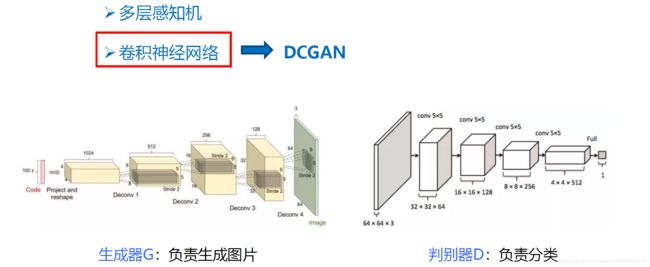
这里: 实际上生成式对抗网络并没有对生成器和判别器的具体结构进行限制,目前使用比较多的使用卷积神经网络对生成式对抗网络进行实现,叫做DCGAN(Deep CNN GNN!)。它是在生成对抗网络基础上增加了深度卷积神经网络结构。
生成器: 图中输入是一个100维的向量(就是前面说的噪声向量),去的网路第一层是全连接层,从第2层开始它用转置的卷积做一个上采样,越靠后的层图像的尺寸越大,从 4 × 4 = > 8 × 8 = , . . . , = > 64 × 64 4×4=>8×8=,...,=>64×64 4×4=>8×8=,...,=>64×64。另外转置卷积进行上采样的过程中也逐渐减少了通道的数量,从 1024 = > 512 = > , . . . , = > 128 = > 3 ( R G B 三 通 道 ) 1024=>512=>,...,=>128=>3(RGB三通道) 1024=>512=>,...,=>128=>3(RGB三通道)。最后输出的是一张 64 × 64 64×64 64×64 三通道的图像。
判别器: 就是一个普通的分类网络,特别之处就是一个二分类模型,用来判断输入图像是真实图像还是生成的图像。它的输入就是一张图像,输出就是这张输入的图像为真实图像的概率。
三. 生成式对抗网络(GAN)实战
3.1. GAN的训练稳定性
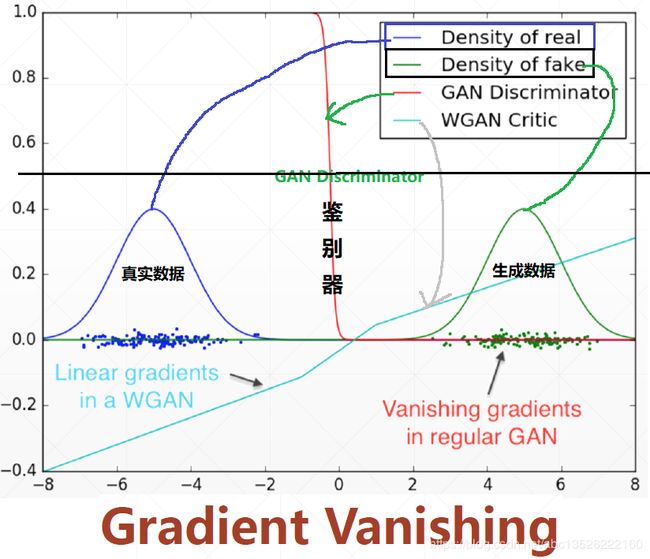
GAN训练的时候经常不稳定,下面尝试分析。
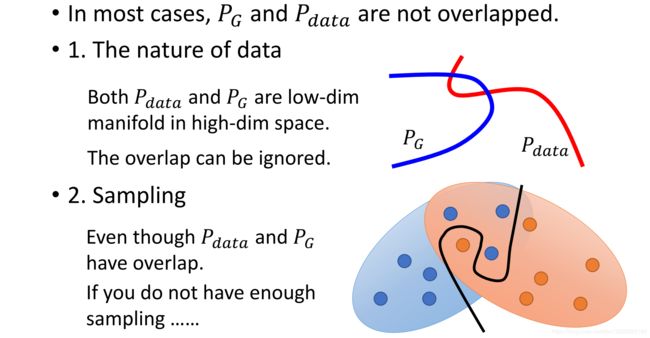
这里: 在GAN训练刚开始的时候, x ∼ p d a t a x \sim p_{data} x∼pdata的真实分布,和生成的 x g x_g xg 的分布 x g ∼ p g x_g \sim p_{g} xg∼pg。这些分布有没有overlapped?刚开始的时候可以想象,生成器不好,生成的肯定是一些噪声,也就是说不可能和真实分布有重叠的。
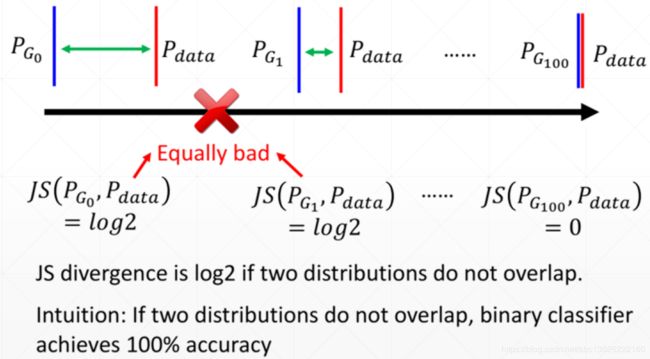
基于上面这个点,在不overlaped的情况下, J S JS JS散度会出现什么情况?
首先给出KL和JS散度公式: D K L ( p ∥ q ) = ∫ x p ( x ) log p ( x ) q ( x ) d x D J S ( p ∥ q ) = 1 2 D K L ( p ∥ p + q 2 ) + 1 2 D K L ( q ∥ p + q 2 ) \begin{array}{l}{D_{K L}(p \| q)=\int_{x} p(x) \log \frac{p(x)}{q(x)} d x} \\ {D_{J S}(p \| q)=\frac{1}{2} D_{K L}\left(p \| \frac{p+q}{2}\right)+\frac{1}{2} D_{K L}\left(q \| \frac{p+q}{2}\right)}\end{array} DKL(p∥q)=∫xp(x)logq(x)p(x)dxDJS(p∥q)=21DKL(p∥2p+q)+21DKL(q∥2p+q) 下面考虑这样一个情况,有两个变量的分布:第一个分布 P 1 P_1 P1, ∀ ( x , y ) ∈ P , x = 0 \forall(x, y) \in P, x=0 ∀(x,y)∈P,x=0 and y ∼ U ( 0 , 1 ) y \sim U(0,1) y∼U(0,1)(0-1的均值分布)。第二个分布 P 2 P_2 P2: ∀ ( x , y ) ∈ Q , x = θ , 0 ≤ θ ≤ 1 and y ∼ U ( 0 , 1 ) \forall(x, y) \in Q, x=\theta, 0 \leq \theta \leq 1 \text { and } y \sim U(0,1) ∀(x,y)∈Q,x=θ,0≤θ≤1 and y∼U(0,1),图形表示如下:
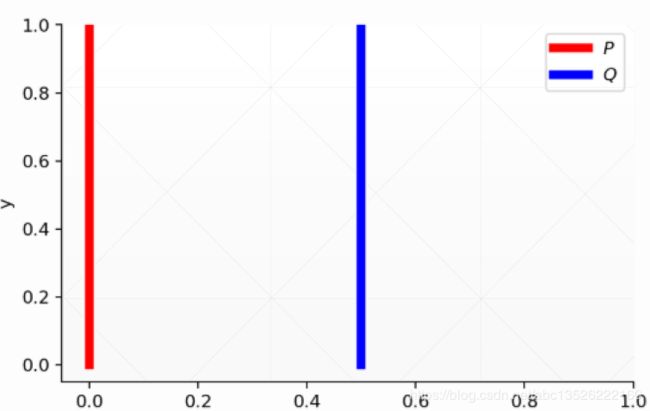
只要这 θ ≠ 0 \theta \neq 0 θ=0,这两个分布绝对不可能有重叠。下面考虑这种情况,当 θ ≠ 0 \theta \neq 0 θ=0时:
D K L ( p ∥ q ) = ∑ x = 0 , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 0 = + ∞ D_{K L}(p \| q)=\sum_{x=0, y \sim U(0,1)} 1 \cdot \log \frac{1}{0}=+\infty DKL(p∥q)=x=0,y∼U(0,1)∑1⋅log01=+∞ 这里情况下: 对于 p p p 分布永远是1, q q q 只能为0。
D K L ( q ∥ p ) = ∑ x = θ , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 0 = + ∞ D_{K L}(q \| p)=\sum_{x=\theta, y \sim U(0,1)} 1 \cdot \log \frac{1}{0}=+\infty DKL(q∥p)=x=θ,y∼U(0,1)∑1⋅log01=+∞ 这里情况下: 也是同样的道理。最终到代入到 J S JS JS散度中去: D J S ( p , q ) = 1 2 ( ∑ x = 0 , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 1 / 2 + ∑ x = 0 , y ∼ U ( 0 , 1 ) 1 ⋅ log 1 1 / 2 ) = log 2 D_{J S}(p, q)=\frac{1}{2}\left(\sum_{x=0, y \sim U(0,1)} 1 \cdot \log \frac{1}{1 / 2}+\sum_{x=0, y \sim U(0,1)} 1 \cdot \log \frac{1}{1 / 2}\right)=\log 2 DJS(p,q)=21⎝⎛x=0,y∼U(0,1)∑1⋅log1/21+x=0,y∼U(0,1)∑1⋅log1/21⎠⎞=log2
我们可以发现: 只要 θ ≠ 0 \theta \neq 0 θ=0,不管 θ \theta θ 是多少,这两个KL散度总是为无穷大,JS总是 log 2 \log 2 log2。这就意味着,两个分布没有交叉重叠的时候,意味KL散度不能很好的量化这两个分布之间的距离(比如:服务员问你吃饱了没?你说没饱,你这信息量给的太少了。服务员没法帮你加菜,不知道几成饱,比如只有一成饱给你加个汉堡,如果你有8成饱给你加个饼干)。就这这个道理,对于两个不一样的分布,这个KL散度或者JS散度,只能给出这么浅显的标准,就有一定的局限性。
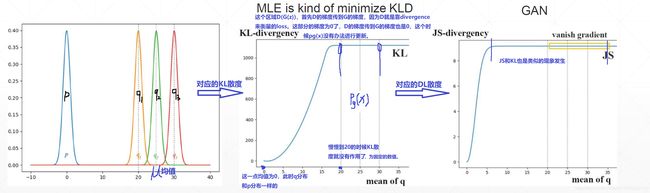
上面很好解释了为什么GAN在刚开始训练的时候容易出现训练不稳定的现象。
- 可以参考这个链接!
- 下面又有两个例子参考!
四. 如何理解转置卷积(反卷积)
首先声明这部分内容主要摘取自作者:抽丝剥茧,带你理解转置卷积(反卷积)
转置卷积又叫反卷积、逆卷积。一句话解释:逆卷积相对于卷积在神经网络结构的正向和反向传播中做相反的运算。不过转置卷积是目前最为正规和主流的名称,因为这个名称更加贴切的描述了卷积的计算过程,而其他的名字容易造成误导。
我们先说一下为什么人们很喜欢叫转置卷积为反卷积或逆卷积。首先举一个例子,将一个 4 × 4 4×4 4×4 的输入通过 3 × 3 3×3 3×3 的卷积核在进行普通卷积(无padding, stride=1),将得到一个 2 × 2 2×2 2×2 的输出。而转置卷积将一个 2 × 2 2×2 2×2 的输入通过同样 3 × 3 3×3 3×3 大小的卷积核将得到一个 4 × 4 4×4 4×4 的输出,看起来似乎是普通卷积的逆过程。就好像是加法的逆过程是减法,乘法的逆过程是除法一样,人们自然而然的认为这两个操作似乎是一个可逆的过程。但事实上两者并没有什么关系,操作的过程也不是可逆的。
4.1. 普通卷积理解动画
如下表普通卷积动画:蓝色映射是输入,青色映射是输出。
- half/same padding(半填充/相同填充):保证输入和输出的feature map尺寸相同。
- valid padding(有效填充):完全不使用填充。
- full padding(全填充):在卷积操作过程中,每个像素在每个方向上被访问的次数相同。
- arbitrary padding(任意填充):人为设定填充。
- 输出尺寸大小为: ⌈ n + 2 p − f s + 1 ⌉ ∗ ⌈ n + 2 p − f s + 1 ⌉ \left\lceil\frac{n+2 p-f}{s}+1\right\rceil*\left\lceil\frac{n+2 p-f}{s}+1\right\rceil ⌈sn+2p−f+1⌉∗⌈sn+2p−f+1⌉ 向上取整, n n n 表示输入尺寸大小, p p p表示padding, s s s表示strides, f f f卷积核尺寸。或者是 ⌊ n + 2 p − f s ⌋ + 1 \left\lfloor \frac{n+2p-f}{s}\right\rfloor+ 1 ⌊sn+2p−f⌋+1向下取整。
| No padding, no strides | Arbitrary padding, no strides | Half padding, no strides | Full padding, no strides |
|---|---|---|---|
|
|
|
|
|
| No padding, strides | Padding, strides | Padding, strides (odd) | |
|
|
|
|
4.2. 普通卷积深入理解
普通的卷积过程可以直观的理解为一个带颜色小窗户(卷积核)在原始的输入图像一步一步的挪动,来通过加权计算得到输出特征。

实际在计算机中计算的时候,并不是像这样逐个位置的进行滑动计算,因为这样的效率太低了。 计算机会将卷积核转换成等效的矩阵,将输入转换为向量。通过输入向量和卷积核矩阵的相乘获得输出向量。输出的向量经过整形便可得到我们的二维输出特征。
具体的操作如下图所示。由于我们的 3 × 3 3×3 3×3 卷积核要在输入上不同的位置卷积 4 4 4 次,所以通过补零的方法将卷积核分别置于一个 4 × 4 4×4 4×4 矩阵的四个角落。这样我们的输入可以直接和这四个 4 × 4 4×4 4×4 的矩阵进行卷积,而舍去了滑动这一操作步骤。
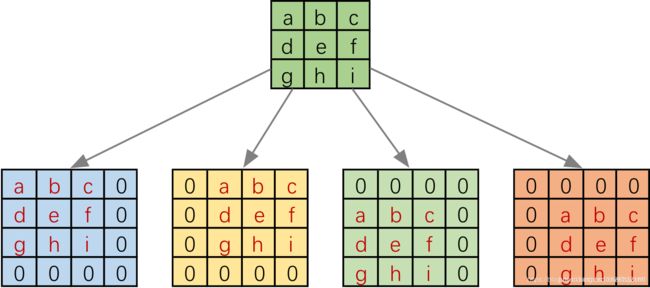
进一步的,我们将输入拉成长向量(这里按行来拉),四个 4 × 4 4×4 4×4 卷积核也拉成长向量并进行拼接,如下图。
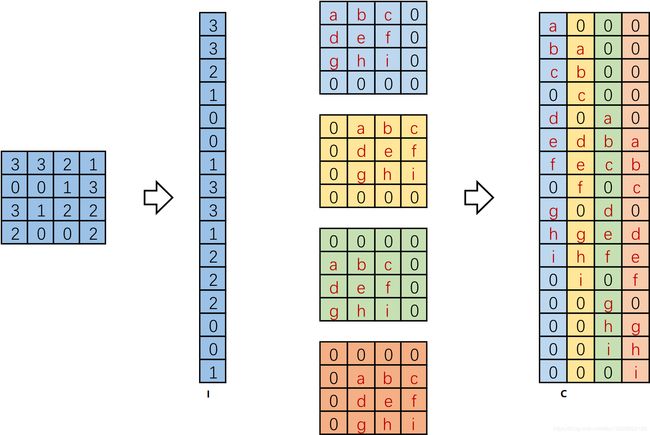
这里将向量化的图像表示为 I \boldsymbol I I,向量化的卷积矩阵为 C \boldsymbol C C,输出特征向量为 O \boldsymbol O O, 这里都是用的列向量表示。则 I T C = O T (37) \boldsymbol I^{T} \boldsymbol C=\boldsymbol O^{T}\tag{37} ITC=OT(37)
如下图所示:

我们将一个 1 × 16 1×16 1×16 的行向量乘以 16 × 4 16×4 16×4 的矩阵,得到了 1 × 4 1×4 1×4 的行向量。那么反过来将一个 1 × 4 1×4 1×4 的向量乘以一个 4 × 16 4×16 4×16 的矩阵是不是就能得到一个 1 × 16 1×16 1×16 的行向量呢? 没错,这便是转置卷积的思想。
4.3. 转置卷积深入理解
一般的卷积操作(这里只考虑最简单的无padding, stride=1的情况),都将输入的数据越卷越小。根据卷积核大小的不同,和步长的不同,输出的尺寸变化也很大。但是有的时候我们需要输入一个小的特征,输出更大尺寸的特征该怎么办呢?比如图像语义分割中往往要求最终输出的特征尺寸和原始输入尺寸相同,但在网络卷积核池化的过程中特征图的尺寸却逐渐变小。在这里转置卷积便能派上了用场。
在数学上, 转置卷积的操作也非常简单,把正常卷积的操作反过来即可。对应上面公式,我们有转置卷积的公式: O T C T = I T (38) \boldsymbol O^{T} \boldsymbol C^{T}=\boldsymbol I^{T}\tag{38} OTCT=IT(38)
如下图所示:

注意:需要注意的是这两个操作并不是可逆的,对于同一个卷积核,经过转置卷积操作之后并不能恢复到原始的数值,保留的只有原始的形状。所以转置卷积的名字就由此而来,而并不是“反卷积”或者是“逆卷积”,不好的名称容易给人以误解。
4.4. 形象化的转置卷积
但是仅仅按照矩阵转置形式来理解转置卷积似乎有些抽象,不像直接卷积那样理解的直观。所以我们也来尝试一下可视化转置卷积。前面说了在将直接卷积向量化的时候是将卷积核补零然后拉成列向量,现在我们有了一个新的转置卷积矩阵,可以将这个过程反过来,把 16 16 16 个列向量再转换成卷积核。以第一列向量为例,如下图:

这里将输入还原为一个 2 × 2 2×2 2×2 的张量,新的卷积核由于只有左上角有非零值直接简化为右侧的形式。对每一个列向量都做这样的变换可以得到:
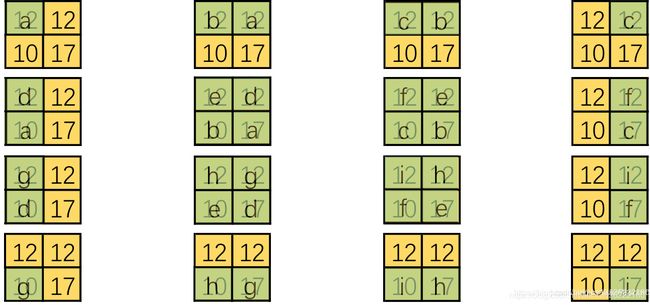
这是一个很有趣的结果,结合整体来看,仿佛有一个更大的卷积核在 2 × 2 2×2 2×2 大小的输入滑动(如下图第1张)。 但是输入太小,每一次卷积只能对应卷积核的一部分。 我们来把更大的卷积核补全,如下图:
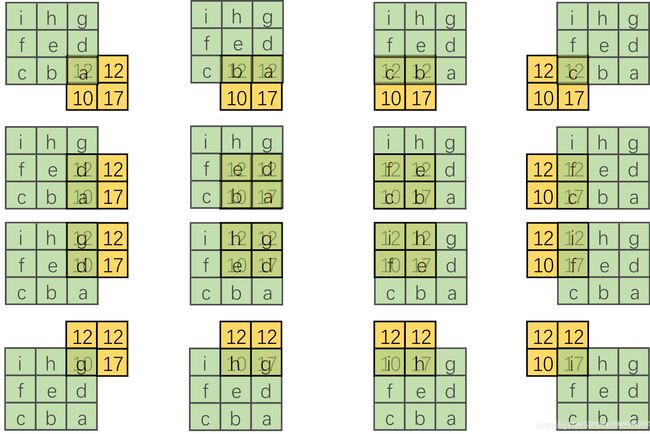
这里和直接卷积有很大的区别,直接卷积我们是用一个“小窗户”去看一个“大世界”,而转置卷积是用一个“大窗户”的一部分去看“小世界”。这里有一点需要注意,我们定义的卷积核是左上角为 a a a,右下角为 i i i,但在可视化转置卷积中,需要将卷积核旋转 180 ° 180° 180° 后再进行卷积。由于输入图像太小,我们按照卷积核尺寸来进行补零操作,每边的补零数量显而易见是 2 2 2,即 3 − 1 = 2 3-1=2 3−1=2。这样我们就将一个转置卷积操作转换为对应的直接卷积。如下图:

总结一下将转置卷积转换为直接卷积的步骤:(这里只考虑stride=1,padding=0的情况)
- 设卷积核大小为 k × k k×k k×k,输入为方形矩阵。
- 对输入进行四边补零,单边补零的数量为 k − 1 k-1 k−1。
- 将卷积核旋转 180 ° 180° 180°,在新的输入上进行直接卷积。
这里调用TensorFlow2.0的conv_transpose函数来进行转置卷积
import tensorflow as tf
# 输入: 1张图片, 尺寸2*2, 通道为1
x = tf.reshape(tf.constant([[1,2],
[4,5]],dtype=tf.float32), [1, 2, 2, 1])
# kernel: 尺寸3*3, 个数是1
kernel = tf.reshape(tf.constant([[1,2,3],
[4,5,6],
[7,8,9]],dtype=tf.float32), [3, 3, 1, 1])
transpose_conv = tf.nn.conv2d_transpose(x, kernel, output_shape=[1, 4, 4, 1],
strides=[1,1,1,1], padding='VALID')
# 为了方便观察,把维度size=1的去掉。
print(tf.squeeze(x))
print(tf.squeeze(kernel))
print(tf.squeeze(transpose_conv))
输出结果:
tf.Tensor(
[[1. 2.]
[4. 5.]], shape=(2, 2), dtype=float32)
tf.Tensor(
[[1. 2. 3.]
[4. 5. 6.]
[7. 8. 9.]], shape=(3, 3), dtype=float32)
tf.Tensor(
[[ 1. 4. 7. 6.]
[ 8. 26. 38. 27.]
[23. 62. 74. 48.]
[28. 67. 76. 45.]], shape=(4, 4), dtype=float32)
Process finished with exit code 0
接下来按照上面的方式,将转置卷积转换为一个等效的直接卷积
import tensorflow as tf
# 转换为等效普通卷积
x2 = tf.reshape(tf.constant([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 1, 2, 0, 0],
[0, 0, 4, 5, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]],dtype=tf.float32), [1, 6, 6, 1])
kernel2 = tf.reshape(tf.constant([[9,8,7],
[6,5,4],
[3,2,1]],dtype=tf.float32), [3, 3, 1, 1])
conv = tf.nn.conv2d(x2,kernel2, strides=[1,1,1,1], padding='VALID')
print(tf.squeeze(x2))
print(tf.squeeze(kernel2))
print(tf.squeeze(conv))
输出结果:
tf.Tensor(
[[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 1. 2. 0. 0.]
[0. 0. 4. 5. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]], shape=(6, 6), dtype=float32)
tf.Tensor(
[[9. 8. 7.]
[6. 5. 4.]
[3. 2. 1.]], shape=(3, 3), dtype=float32)
tf.Tensor(
[[ 1. 4. 7. 6.]
[ 8. 26. 38. 27.]
[23. 62. 74. 48.]
[28. 67. 76. 45.]], shape=(4, 4), dtype=float32)
Process finished with exit code 0
4.5. 转置卷积动画演示
如下:蓝色映射是输入,青色映射是输出。
| No padding, no strides, transposed | Arbitrary padding, no strides, transposed | Half padding, no strides, transposed | Full padding, no strides, transposed |
|---|---|---|---|
|
|
|
|
|
| No padding, strides, transposed | Padding, strides, transposed | Padding, strides (odd), transposed | |
|
|
|
|
参考文章及推荐
- 龙龙老师Tensorflow深度学习书!
- 参考了浙江大学城市学院的深度学习应用开发PPT,表示感谢!
- 参考了哈尔滨工业大学刘远超老师的PPT资料,表示感谢!
- 抽丝剥茧,带你理解转置卷积(反卷积)
- 训练GAN的技巧清单
- 生成式模型合集
- pix2pix模型在线Demo
- GAN入门理解及公式推导
- 50行代码实现GAN-pytorch
- https://github.com/vdumoulin/conv_arithmetic#convolution-arithmetic
- 开发者自述:我是这样学习 GAN 的