KNN算法及KNN的优化算法-加权KNN
KNN及加权KNN优化算法
文章目录
- KNN及加权KNN优化算法
- 深度学习的常规套路:
- K-近邻(KNN)算法:
- 超参数(距离):
- 调参-训练采用交叉验证:
- 附:KNN算法实例:
- KNN算法注意事项:
- KNN算法缺陷及优化:
- 加权KNN算法:
深度学习的常规套路:

1.收集数据并给定标签
2.训练一个分类器
3.测试,评估
K-近邻(KNN)算法:
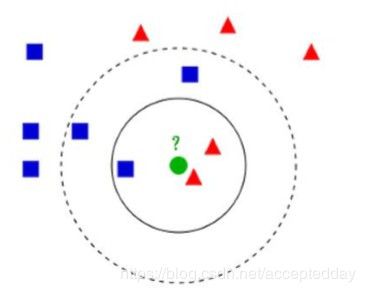
对于未知类别属性数据集中的点:
1.计算已知类别数据集中的点与当前点的距离
2.按照距离依次排序
3.选取与当前点距离最小的K个点
4.确定前K个点所在类别的出现概率
5.返回前K个点出现频率最高的类别作为当前点预测分类。
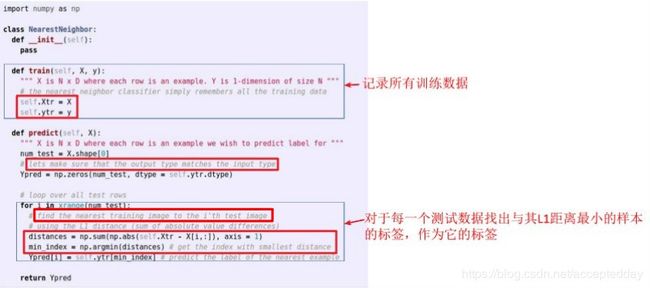
KNN算法:不需要使用训练集进行训练,训练复杂度为0,KNN分类的计算复杂度和训练集中的文档数目成正比。如训练集中文档总数为n,那么KNN的分类时间复杂度为O(n)。
例:CIFAR-10库采用KNN分类:

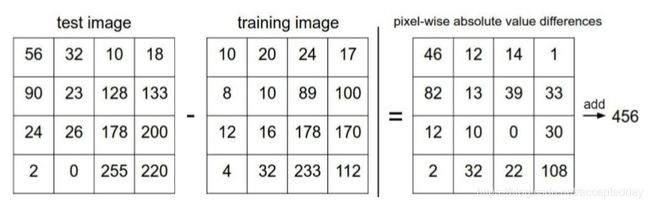
计算方法:
![[外链图片转存失败(img-JJfkMWS0-1565944939061)(C:\Users\爱拼才会赢\Desktop\python\神经网络基础及架构初步\图片\4.jpg)]](http://img.e-com-net.com/image/info8/330733bbb1024d43a1fab858590bbafe.jpg)
代码部分:
分类效果:

超参数(距离):
欧氏距离:应用勾股定理计算两个点的直线距离。![[外链图片转存失败(img-t3USjKMW-1565944939062)(C:\Users\爱拼才会赢\Desktop\python\神经网络基础及架构初步\图片\8.jpg)]](http://img.e-com-net.com/image/info8/14d307dafacb41a8a6c09177a731520a.jpg)
曼哈顿距离:表示两个点在标准坐标系上的绝对轴距之和。![[外链图片转存失败(img-OTUstmw6-1565944939062)(C:\Users\爱拼才会赢\Desktop\python\神经网络基础及架构初步\图片\9.jpg)]](http://img.e-com-net.com/image/info8/4929c68017d14b858d18b3dc5dce4273.jpg)
调参-训练采用交叉验证:
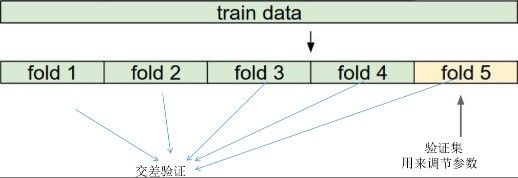
附:KNN算法实例:
样本数据:
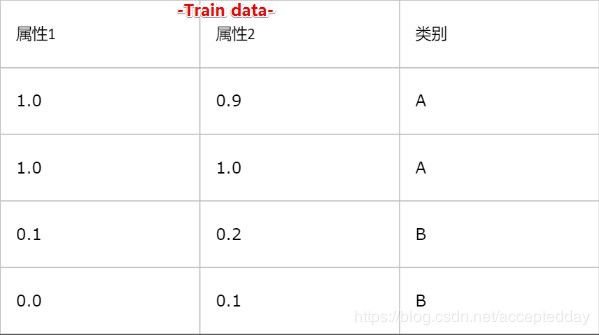
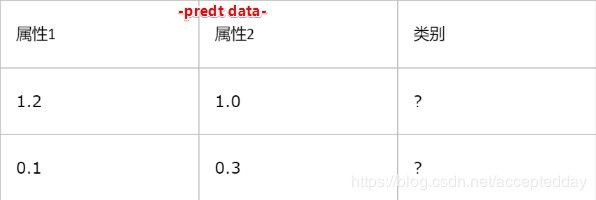
KNN的脚本代码:
#!/usr/bin/python
coding=utf-8
#########################################
kNN: k Nearest Neighbors
输入: newInput: (1xN)的待分类向量
dataSet: (NxM)的训练数据集
labels: 训练数据集的类别标签向量
k: 近邻数
输出: 可能性最大的分类标签
#########################################
from numpy import *
import operator
创建一个数据集,包含2个类别共4个样本
def createDataSet():
# 生成一个矩阵,每行表示一个样本
group = array([[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]])
# 4个样本分别所属的类别
labels = ['A', 'A', 'B', 'B']
return group, labels
KNN分类算法函数定义
def kNNClassify(newInput, dataSet, labels, k):
numSamples = dataSet.shape[0] # shape[0]表示行数
# # step 1: 计算距离[
# 假如:
# Newinput:[1,0,2]
# Dataset:
# [1,0,1]
# [2,1,3]
# [1,0,2]
# 计算过程即为:
# 1、求差
# [1,0,1] [1,0,2]
# [2,1,3] -- [1,0,2]
# [1,0,2] [1,0,2]
# =
# [0,0,-1]
# [1,1,1]
# [0,0,-1]
# 2、对差值平方
# [0,0,1]
# [1,1,1]
# [0,0,1]
# 3、将平方后的差值累加
# [1]
# [3]
# [1]
# 4、将上一步骤的值求开方,即得距离
# [1]
# [1.73]
# [1]
#
# ]
# tile(A, reps): 构造一个矩阵,通过A重复reps次得到
# the following copy numSamples rows for dataSet
diff = tile(newInput, (numSamples, 1)) - dataSet # 按元素求差值
squaredDiff = diff ** 2 # 将差值平方
squaredDist = sum(squaredDiff, axis = 1) # 按行累加
distance = squaredDist ** 0.5 # 将差值平方和求开方,即得距离
# # step 2: 对距离排序
# argsort() 返回排序后的索引值
sortedDistIndices = argsort(distance)
classCount = {} # define a dictionary (can be append element)
for i in xrange(k):
# # step 3: 选择k个最近邻
voteLabel = labels[sortedDistIndices[i]]
# # step 4: 计算k个最近邻中各类别出现的次数
# when the key voteLabel is not in dictionary classCount, get()
# will return 0
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
# # step 5: 返回出现次数最多的类别标签
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key
return maxIndex
KNN-TEST的测试代码:
#!/usr/bin/python
# coding=utf-8
import KNN
from numpy import *
# 生成数据集和类别标签
dataSet, labels = KNN.createDataSet()
# 定义一个未知类别的数据
testX = array([1.2, 1.0])
k = 3
# 调用分类函数对未知数据分类
outputLabel = KNN.kNNClassify(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel
testX = array([0.1, 0.3])
outputLabel = KNN.kNNClassify(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel
测试效果:
![[外链图片转存失败(img-8q8VhpUW-1565944939063)(C:\Users\爱拼才会赢\Desktop\python\神经网络基础及架构初步\图片\14.jpg)]](http://img.e-com-net.com/image/info8/cc9c225722024e2cae31460a9f9c1edc.jpg)
参考博客链接:
https://www.cnblogs.com/ahu-lichang/p/7151007.html
KNN算法注意事项:
1.预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值 (zero mean)和单位方差(unit variance)。
2.如果数据是高维数据,考虑使用降维方法,比如PCA。
3.将数据随机分入训练集和验证集。按照一般规律,70%-90% 数据作为训练集。
4.在验证集上调优,尝试足够多的k值,尝试曼哈顿距离和欧氏距离两种范数计算方式。
KNN算法缺陷及优化:
1.样本不平衡容易导致结果错误
如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
改善方法:对此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
2.计算量较大
因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
改善方法:事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
该方法比较适用于样本容量比较大的类域的分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
加权KNN算法:
采用Gaussian函数进行不同距离的样本的权重优化,当训练样本与测试样本距离↑,该距离值权重↓。
给更近的邻居分配更大的权重(你离我更近,那我就认为你跟我更相似,就给你分配更大的权重),而较远的邻居的权重相应地减少,取其加权平均。
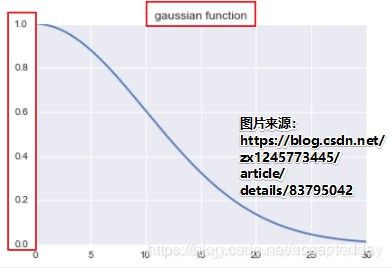
加权KNN代码:
def gaussian(dist, sigma = 10.0):
""" Input a distance and return it`s weight"""
weight = np.exp(-dist**2/(2*sigma**2))
return weight
### 加权KNN
def weighted_classify(input, dataSet, label, k):
dataSize = dataSet.shape[0]
diff = np.tile(input, (dataSize, 1)) - dataSet
sqdiff = diff**2
squareDist = np.array([sum(x) for x in sqdiff])
dist = squareDist**0.5
#print(input, dist[0], dist[1164])
sortedDistIndex = np.argsort(dist)
classCount = {}
for i in range(k):
index = sortedDistIndex[i]
voteLabel = label[index]
weight = gaussian(dist[index])
#print(index, dist[index],weight)
## 这里不再是加一,而是权重*1
classCount[voteLabel] = classCount.get(voteLabel, 0) + weight*1
maxCount = 0
#print(classCount)
for key, value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
参考博客链接:
https://blog.csdn.net/u010967162/article/details/52269077