概述
从OkHttp问世以来,度娘,google上关于OkHttp的讲解说明数不胜数,各种解读思想不尽相同,一千个读者就有一千个哈默雷特。本篇文章从源码出发向你介绍Okhttp的基本使用以及底层实现原理,让你从会写转向会用,学习Android顶尖源码的设计理念和开源扩展性,如果解读有误,还望提出探讨纠正。
文章链接:
Android OkHttp源码解析入门教程:同步和异步(一)
Android OkHttp源码解析入门教程:拦截器和责任链(二)
前言
上一篇文章我们主要讲解OkHttp的基本使用以及同步请求,异步请求的源码分析,相信大家也对其内部的基本流程以及作用有了大致的了解,还记得上一篇我们提到过getResponseWithInterceptorChain责任链,那么这篇文章就带你深入OkHttp内部5大拦截器(Interceptors)和责任链模式的源码分析,滴滴滴。
正文
首先,我们要清楚OkHttp拦截器(Interceptors)是干什么用的,来看看官网的解释
Interceptors are a powerful mechanism that can monitor, rewrite, and retry calls
拦截器是一种强大的机制,可以做网络监视、重写和重试调用
这句话怎么理解呢?简单来说,就好比如你带着盘缠上京赶考,遇到了五批贼寇,但其奇怪的是他们的目标有的是为财,有的是为色,各不相同;例子中的你就相当于一个正在执行任务的网络请求,贼寇就是拦截器,它们的作用就是取走请求所携带的参数拿过去修改,判断,校验然后放行,其实际是实现了AOP(面向切面编程),关于AOP的了解,相信接触过Spring框架的是最熟悉不过的。
我们再来看官方给出的拦截器图

拦截器有两种:APP层面的拦截器(Application Interception)、网络拦截器(Network Interception),而我们这篇文章注重讲解OkHttp core(系统内部五大拦截器)
那么OkHttp系统内部的拦截器有哪些呢?作用分别是干什么的?
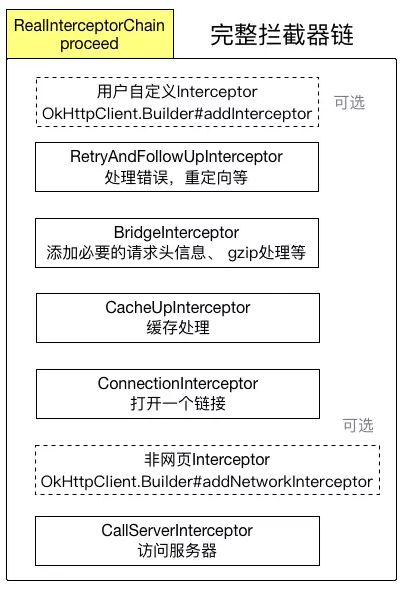
紧接上篇文章,我们到getResponseWithInterceptorChain()源码中分析,这些拦截器是怎么发挥各自作用的?
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
// 责任链
List interceptors = new ArrayList<>();
// 添加自定义拦截器(Application Interception)
interceptors.addAll(client.interceptors());
// 添加 负责处理错误,失败重试,重定向拦截器 RetryAndFollowUpInterceptor
interceptors.add(retryAndFollowUpInterceptor);
// 添加 负责补充用户创建请求中缺少一些必须的请求头以及压缩处理的 BridgeInterceptor
interceptors.add(new BridgeInterceptor(client.cookieJar()));
// 添加 负责进行缓存处理的 CacheInterceptor
interceptors.add(new CacheInterceptor(client.internalCache()));
// 添加 负责与服务器建立链接的 ConnectInterceptor
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
// 添加网络拦截器(Network Interception)
interceptors.addAll(client.networkInterceptors());
}
//添加 负责向服务器发送请求数据、从服务器读取响应数据的 CallServerInterceptor
interceptors.add(new CallServerInterceptor(forWebSocket));
// 将interceptors集合以及相应参数传到RealInterceptorChain构造方法中完成责任链的创建
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
// 调用责任链的执行
return chain.proceed(originalRequest);
}
从这里可以看出,getResponseWithInterceptorChain方法首先创建了一系列拦截器,并整合到一个Interceptor集合当中,同时每个拦截器各自负责不同的部分,处理不同的功能,然后把集合加入到RealInterceptorChain构造方法中完成拦截器链的创建,而责任链模式就是管理多个拦截器链。
关于责任链模式的理解,简单来说,其实日常的开发代码中随处可见

@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
super.onActivityResult(requestCode, resultCode, data);
if (resultCode == RESULT_OK) {
switch (requestCode) {
case 1:
System.out.println("我是第一个拦截器: " + requestCode);
break;
case 2:
System.out.println("我是第二个拦截器: " + requestCode);
break;
case 3:
System.out.println("我是第三个拦截器: " + requestCode);
break;
default:
break;
}
}
}
相信当你看到这段代码就明白责任链模式是干什么的吧,根据requestCode的状态处理不同的业务,不属于自己的任务传递给下一个,如果还不明白,你肯定是个假的程序员,当然这是个非常简化的责任链模式,很多定义都有错误,这里只是给大家做个简单介绍下责任链模式的流程是怎样的,要想深入并应用到实际开发中,还需要看相关文档,你懂我意思吧。

我们直奔主题,上文也说到,getResponseWithInterceptorChain最终调用的RealInterceptorChain的proceed方法,我们接着从源码出发
public interface Interceptor {
// 每个拦截器会根据Chain拦截器链触发对下一个拦截器的调用,直到最后一个拦截器不触发
// 当拦截器链中所有的拦截器被依次执行完成后,就会将每次生成后的结果进行组装
Response intercept(Chain chain) throws IOException;
interface Chain {
// 返回请求
Request request();
// 处理请求
Response proceed(Request request) throws IOException;
}
}
public final class RealInterceptorChain implements Interceptor.Chain {
private final List interceptors;
private final StreamAllocation streamAllocation;
private final HttpCodec httpCodec;
private final RealConnection connection;
private final int index;
private final Request request;
private final Call call;
private final EventListener eventListener;
private final int connectTimeout;
private final int readTimeout;
private final int writeTimeout;
private int calls;
public RealInterceptorChain(List interceptors, StreamAllocation streamAllocation,
HttpCodec httpCodec, RealConnection connection, int index, Request request, Call call,
EventListener eventListener, int connectTimeout, int readTimeout, int writeTimeout) {
this.interceptors = interceptors;
this.connection = connection;
this.streamAllocation = streamAllocation;
this.httpCodec = httpCodec;
this.index = index;
this.request = request;
this.call = call;
this.eventListener = eventListener;
this.connectTimeout = connectTimeout;
this.readTimeout = readTimeout;
this.writeTimeout = writeTimeout;
}
@Override public Response proceed(Request request) throws IOException {
return proceed(request, streamAllocation, httpCodec, connection);
}
}
上述代码中可以看出Interceptor是个接口类,RealInterceptorChain实现了Interceptor.chain方法,在这里我们也看到了之前我们初始化时传进来的参数,可见我们实际调用的是RealInterceptorChain的proceed方法,接着往下看
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException {
if (index >= interceptors.size()) throw new AssertionError();
calls++;
// 去掉一些逻辑判断处理,留下核心代码
// Call the next interceptor in the chain.(调用链中的下一个拦截器)
// 创建下一个拦截器链,index+1表示如果要继续访问拦截器链中的拦截器,只能从下一个拦截器访问,而不能从当前拦截器开始
// 即根据index光标不断创建新的拦截器链,新的拦截器链会比之前少一个拦截器,这样就可以防止重复执行
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
// 获取当前拦截器
Interceptor interceptor = interceptors.get(index);
// 执行当前拦截器,并将下一个拦截器链传入
Response response = interceptor.intercept(next);
return response;
}
看到这里你会觉得一头雾水,简单了解后,你的疑问可能如下
1.index+1的作用是干什么的?
2.当前拦截器是怎么执行的?
3.拦截器链是怎么依次调用执行的?
4.上面3点都理解,但每个拦截器返回的结果都不一样,它是怎么返回给我一个最终结果?
首先,我们要清楚责任链模式的流程,如同上文所说的,书生携带书籍,软银,家眷上京赶考,途遇强盗,第一批强盗抢走了书籍并且放行,第二批强盗抢走了软银放行,一直到最后一无所有才会停止。
书生就是最开始的RealInterceptorChain,强盗就是Interceptor,,index+1的作用就是创建一个新的拦截器链,简单来说,就是
书生(书籍,软银,家眷) →劫书籍强盗→书生(软银,家眷)→劫财强盗→书生(家眷)→...
即通过不断创建新的RealInterceptorChain链轮循执行interceptors中的拦截器形成一个责任链(抢劫链)模式直到全部拦截器链中的拦截器处理完成后返回最终结果
// 获取当前拦截器
Interceptor interceptor = interceptors.get(index);
index+1不断执行,list.get(0),list.get(1),... 这样就能取出interceptors中所有的拦截器,我们之前也说过Interceptor是一个接口,okhttp内部的拦截器都实现了这个接口处理各自的业务
如此,每当 Interceptor interceptor = interceptors.get(index)执行时,就可以根据interceptor.intercept(next)执行相应拦截器实现的intercept方法处理相应的业务,同时把创建好新的拦截器链传进来,这样就可以避免重复执行一个拦截器。
RetryAndFollowUpInterceptor(重定向拦截器)
负责处理错误,失败重试,重定向
/**
* This interceptor recovers from failures and follows redirects as necessary. It may throw an
* {@link IOException} if the call was canceled.
*/
public final class RetryAndFollowUpInterceptor implements Interceptor {
/**
* How many redirects and auth challenges should we attempt? Chrome follows 21 redirects; Firefox,
* curl, and wget follow 20; Safari follows 16; and HTTP/1.0 recommends 5.
*/
//最大失败重连次数:
private static final int MAX_FOLLOW_UPS = 20;
public RetryAndFollowUpInterceptor(OkHttpClient client, boolean forWebSocket) {
this.client = client;
this.forWebSocket = forWebSocket;
}
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
// 建立执行Http请求所需要的对象,,通过责任链模式不断传递,直到在ConnectInterceptor中具体使用,
// 主要用于 ①获取连接服务端的Connection ②连接用于服务端进行数据传输的输入输出流
// 1.全局的连接池,2.连接线路Address,3.堆栈对象
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()), callStackTrace);
int followUpCount = 0;
Response priorResponse = null; // 最终response
while (true) {
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response = null;
boolean releaseConnection = true;
try {
// 执行下一个拦截器,即BridgeInterceptor
// 将初始化好的连接对象传递给下一个拦截器,通过proceed方法执行下一个拦截器链
// 这里返回的response是下一个拦截器处理返回的response,通过priorResponse不断结合,最终成为返回给我们的结果
response = ((RealInterceptorChain) chain).proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
// The attempt to connect via a route failed. The request will not have been sent.
// 如果有异常,判断是否要恢复
if (!recover(e.getLastConnectException(), false, request)) {
throw e.getLastConnectException();
}
releaseConnection = false;
continue;
} catch (IOException e) {
// An attempt to communicate with a server failed. The request may have been sent.
boolean requestSendStarted = !(e instanceof ConnectionShutdownException);
if (!recover(e, requestSendStarted, request)) throw e;
releaseConnection = false;
continue;
} finally {
// We're throwing an unchecked exception. Release any resources.
if (releaseConnection) {
streamAllocation.streamFailed(null);
streamAllocation.release();
}
}
// Attach the prior response if it exists. Such responses never have a body.
if (priorResponse != null) {
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder()
.body(null)
.build())
.build();
}
// 检查是否符合要求
Request followUp = followUpRequest(response);
if (followUp == null) {
if (!forWebSocket) {
streamAllocation.release();
}
// 返回结果
return response;
}
//不符合,关闭响应流
closeQuietly(response.body());
// 是否超过最大限制
if (++followUpCount > MAX_FOLLOW_UPS) {
streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
if (followUp.body() instanceof UnrepeatableRequestBody) {
streamAllocation.release();
throw new HttpRetryException("Cannot retry streamed HTTP body", response.code());
}
// 是否有相同的连接
if (!sameConnection(response, followUp.url())) {
streamAllocation.release();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(followUp.url()), callStackTrace);
} else if (streamAllocation.codec() != null) {
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
}
request = followUp;
priorResponse = response;
}
}
在这里我们看到response = ((RealInterceptorChain) chain).proceed(request, streamAllocation, null, null),很明显proceed执行的就是我们传进来的新拦截器链,从而形成责任链,这样也就能明白拦截器链是如何依次执行的。
其实RetryAndFollowUpInterceptor 主要负责的是失败重连,但是要注意的,不是所有的网络请求失败后都可以重连,所以RetryAndFollowUpInterceptor内部会帮我们进行检测网络请求异常和响应码情况判断,符合条件即可进行失败重连。
StreamAllocation: 建立执行Http请求所需的对象,主要用于
1. 获取连接服务端的Connection2.连接用于服务端进行数据传输的输入输出流
通过责任链模式不断传递,直到在ConnectInterceptor中具体使用,
(1)全局的连接池,(2)连接线路Address,(3)堆栈对象
streamAllocation = new StreamAllocation( client.connectionPool(), createAddress(request.url()), callStackTrace);
这里的createAddress(request.url())是根据Url创建一个基于Okio的Socket连接的Address对象。状态处理情况流程如下
1、首先执行whie(true)循环,如果取消网络请求canceled,则释放streamAllocation 资源同时抛出异常结束
2、执行下一个拦截器链,如果发生异常,走到catch里面,判断是否恢复请求继续执行,否则退出释放
3、 如果priorResponse不为空,则结合当前返回Response和之前响应返回后的Response
(这就是为什么最后返回的是一个完整的Response)
4、调用followUpRequest查看响应是否需要重定向,如果不需要重定向则返回当前请求
5、followUpCount 重定向次数+1,同时判断是否达到最大重定向次数。符合则释放streamAllocation并抛出异常
6、sameConnection检查是否有相同的链接,相同则StreamAllocation释放并重建
7、重新设置request,并把当前的Response保存到priorResponse,继续while循环
由此可以看出RetryAndFollowUpInterceptor主要执行流程:
1)创建StreamAllocation对象
2)调用RealInterceptorChain.proceed(...)进行网络请求
3)根据异常结果或则响应结果判断是否要进行重新请求
4)调用下一个拦截器,处理response并返回给上一个拦截器
BridgeInterceptor(桥接拦截器)
负责设置编码方式,添加头部,Keep-Alive 连接以及应用层和网络层请求和响应类型之间的相互转换
/**
* Bridges from application code to network code. First it builds a network request from a user
* request. Then it proceeds to call the network. Finally it builds a user response from the network
* response.
*/
public final class BridgeInterceptor implements Interceptor {
private final CookieJar cookieJar;
public BridgeInterceptor(CookieJar cookieJar) {
this.cookieJar = cookieJar;
}
@Override
//1、cookie的处理, 2、Gzip压缩
public Response intercept(Interceptor.Chain chain) throws IOException {
Request userRequest = chain.request();
Request.Builder requestBuilder = userRequest.newBuilder();
RequestBody body = userRequest.body();
if (body != null) {
MediaType contentType = body.contentType();
if (contentType != null) {
requestBuilder.header("Content-Type", contentType.toString());
}
long contentLength = body.contentLength();
if (contentLength != -1) {
requestBuilder.header("Content-Length", Long.toString(contentLength));
requestBuilder.removeHeader("Transfer-Encoding");
} else {
requestBuilder.header("Transfer-Encoding", "chunked");
requestBuilder.removeHeader("Content-Length");
}
}
if (userRequest.header("Host") == null) {
requestBuilder.header("Host", hostHeader(userRequest.url(), false));
}
if (userRequest.header("Connection") == null) {
requestBuilder.header("Connection", "Keep-Alive");
}
// If we add an "Accept-Encoding: gzip" header field we're responsible for also decompressing
// the transfer stream.
boolean transparentGzip = false;
if (userRequest.header("Accept-Encoding") == null && userRequest.header("Range") == null) {
transparentGzip = true;
requestBuilder.header("Accept-Encoding", "gzip");
}
// 所以返回的cookies不能为空,否则这里会报空指针
List cookies = cookieJar.loadForRequest(userRequest.url());
if (!cookies.isEmpty()) {
// 创建Okhpptclitent时候配置的cookieJar,
requestBuilder.header("Cookie", cookieHeader(cookies));
}
if (userRequest.header("User-Agent") == null) {
requestBuilder.header("User-Agent", Version.userAgent());
}
// 以上为请求前的头处理
Response networkResponse = chain.proceed(requestBuilder.build());
// 以下是请求完成,拿到返回后的头处理
// 响应header, 如果没有自定义配置cookie不会解析
HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers());
Response.Builder responseBuilder = networkResponse.newBuilder()
.request(userRequest);
}
从这里可以看出,BridgeInterceptor在发送网络请求之前所做的操作都是帮我们传进来的普通Request添加必要的头部信息Content-Type、Content-Length、Transfer-Encoding、Host、Connection(默认Keep-Alive)、Accept-Encoding、User-Agent,使之变成可以发送网络请求的Request。
我们具体来看HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers()),调用Http头部的receiveHeaders静态方法将服务器响应回来的Response转化为用户响应可以使用的Response
public static void receiveHeaders(CookieJar cookieJar, HttpUrl url, Headers headers) {
// 无配置则不解析
if (cookieJar == CookieJar.NO_COOKIES) return;
// 遍历Cookie解析
List cookies = Cookie.parseAll(url, headers);
if (cookies.isEmpty()) return;
// 然后保存,即自定义
cookieJar.saveFromResponse(url, cookies);
}
当我们自定义Cookie配置后,receiveHeaders方法就会帮我们解析Cookie并添加到header头部中保存
// 前面解析完header后,判断服务器是否支持Gzip压缩格式,如果支持将交给Okio处理
if (transparentGzip
&& "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding"))
&& HttpHeaders.hasBody(networkResponse)) {
GzipSource responseBody = new GzipSource(networkResponse.body().source());
Headers strippedHeaders = networkResponse.headers().newBuilder()
.removeAll("Content-Encoding")
.removeAll("Content-Length")
.build();
responseBuilder.headers(strippedHeaders);
// 处理完成后,重新生成一个response
responseBuilder.body(new RealResponseBody(strippedHeaders, Okio.buffer(responseBody)));
}
return responseBuilder.build();
}
- transparentGzip判断服务器是否支持Gzip压缩
- 满足判断当前头部Content-Encoding是否支持gzip
- 判断Http头部是否有body体
满足上述条件,就将Response.body输入流转换成GzipSource类型,获得解压过后的数据流后,移除响应中的header Content-Encoding和Content-Length,构造新的响应返回。
由此可以看出BridgeInterceptor主要执行流程:
1)负责将用户构建的Request请求转化成能够进行网络访问的请求
2)将符合条件的Request执行网络请求
3)将网络请求响应后的Response转化(Gzip压缩,Gzip解压缩)为用户可用的Response
CacheInterceptor(缓存拦截器)
负责进行缓存处理
/** Serves requests from the cache and writes responses to the cache. */
public final class CacheInterceptor implements Interceptor {
final InternalCache cache;
public CacheInterceptor(InternalCache cache) {
this.cache = cache;
}
@Override public Response intercept(Chain chain) throws IOException {
// 通过Request从缓存中获取Response
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis(); // 获取系统时间
// 缓存策略类,该类决定了是使用缓存还是进行网络请求
// 根据请求头获取用户指定的缓存策略,并根据缓存策略来获取networkRequest,cacheResponse;
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
// 网络请求,如果为null就代表不用进行网络请求
Request networkRequest = strategy.networkRequest;
// 获取CacheStrategy缓存中的Response,如果为null,则代表不使用缓存
Response cacheResponse = strategy.cacheResponse;
if (cache != null) {//根据缓存策略,更新统计指标:请求次数、使用网络请求次数、使用缓存次数
cache.trackResponse(strategy);
}
if (cacheCandidate != null && cacheResponse == null) {
//cacheResponse不读缓存,那么cacheCandidate不可用,关闭它
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
// If we're forbidden from using the network and the cache is insufficient, fail.
// 如果我们禁止使用网络和缓存不足,则返回504。
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
// If we don't need the network, we're done.
// 不使用网络请求 且存在缓存 直接返回响应
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
如果开始之前,你对Http缓存协议还不太懂,建议先去了解在回来看讲解会更好理解
上面的代码可以看出,CacheInterceptor的主要作用就是负责缓存的管理,期间也涉及到对网络状态的判断,更新缓存等,流程如下
1.首先根据Request中获取缓存的Response来获取缓存(Chain就是Interceptor接口类中的接口方法,主要处理请求和返回请求)
2.获取当前时间戳,同时通过 CacheStrategy.Factory工厂类来获取缓存策略
public final class CacheStrategy {
/** The request to send on the network, or null if this call doesn't use the network. */
public final @Nullable Request networkRequest;
/** The cached response to return or validate; or null if this call doesn't use a cache. */
public final @Nullable Response cacheResponse;
CacheStrategy(Request networkRequest, Response cacheResponse) {
this.networkRequest = networkRequest;
this.cacheResponse = cacheResponse;
}
public CacheStrategy get() {
CacheStrategy candidate = getCandidate();
if (candidate.networkRequest != null && request.cacheControl().onlyIfCached()) {
// We're forbidden from using the network and the cache is insufficient.
return new CacheStrategy(null, null);
}
return candidate;
}
/** Returns a strategy to use assuming the request can use the network. */
private CacheStrategy getCandidate() {
//如果缓存没有命中(即null),网络请求也不需要加缓存Header了
if (cacheResponse == null) {
//没有缓存的网络请求,查上文的表可知是直接访问
return new CacheStrategy(request, null);
}
// Drop the cached response if it's missing a required handshake.
// 如果缓存的TLS握手信息丢失,返回进行直接连接
if (request.isHttps() && cacheResponse.handshake() == null) {
return new CacheStrategy(request, null);
}
//检测response的状态码,Expired时间,是否有no-cache标签
if (!isCacheable(cacheResponse, request)) {
return new CacheStrategy(request, null);
}
CacheControl requestCaching = request.cacheControl();
// 如果请求指定不使用缓存响应并且当前request是可选择的get请求
if (requestCaching.noCache() || hasConditions(request)) {
// 重新请求
return new CacheStrategy(request, null);
}
CacheControl responseCaching = cacheResponse.cacheControl();
// 如果缓存的response中的immutable标志位为true,则不请求网络
if (responseCaching.immutable()) {
return new CacheStrategy(null, cacheResponse);
}
long ageMillis = cacheResponseAge();
long freshMillis = computeFreshnessLifetime();
if (requestCaching.maxAgeSeconds() != -1) {
freshMillis = Math.min(freshMillis, SECONDS.toMillis(requestCaching.maxAgeSeconds()));
}
long minFreshMillis = 0;
if (requestCaching.minFreshSeconds() != -1) {
minFreshMillis = SECONDS.toMillis(requestCaching.minFreshSeconds());
}
long maxStaleMillis = 0;
if (!responseCaching.mustRevalidate() && requestCaching.maxStaleSeconds() != -1) {
maxStaleMillis = SECONDS.toMillis(requestCaching.maxStaleSeconds());
}
if (!responseCaching.noCache() && ageMillis + minFreshMillis < freshMillis + maxStaleMillis) {
Response.Builder builder = cacheResponse.newBuilder();
if (ageMillis + minFreshMillis >= freshMillis) {
builder.addHeader("Warning", "110 HttpURLConnection \"Response is stale\"");
}
long oneDayMillis = 24 * 60 * 60 * 1000L;
if (ageMillis > oneDayMillis && isFreshnessLifetimeHeuristic()) {
builder.addHeader("Warning", "113 HttpURLConnection \"Heuristic expiration\"");
}
return new CacheStrategy(null, builder.build());
}
Headers.Builder conditionalRequestHeaders = request.headers().newBuilder();
Internal.instance.addLenient(conditionalRequestHeaders, conditionName, conditionValue);
Request conditionalRequest = request.newBuilder()
.headers(conditionalRequestHeaders.build())
.build();
return new CacheStrategy(conditionalRequest, cacheResponse);
}
CacheStrategy缓存策略维护两个变量networkRequest和cacheResponse,其内部工厂类Factory中的getCandidate方法会通过相应的逻辑判断对比选择最好的策略,如果返回networkRequest为null,则表示不进行网络请求;而如果返回cacheResponse为null,则表示没有有效的缓存。
3.紧接上文,判断缓存是否为空,则调用trackResponse(如果有缓存,根据缓存策略,更新统计指标:请求次数、使用网络请求次数、使用缓存次数)
4.缓存无效,则关闭缓存
5.如果networkRequest和cacheResponse都为null,则表示不请求网络而缓存又为null,那就返回504,请求失败
6.如果当前返回网络请求为空,且存在缓存,直接返回响应
// 紧接上文
Response networkResponse = null;
try {
//执行下一个拦截器
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
// If we have a cache response too, then we're doing a conditional get.
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (cache != null) {
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) {
// Offer this request to the cache.
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
if (HttpMethod.invalidatesCache(networkRequest.method())) {
try {
cache.remove(networkRequest);
} catch (IOException ignored) {
// The cache cannot be written.
}
}
}
return response;
}
下部分代码主要做了这几件事:
1)执行下一个拦截器,即ConnectInterceptor
2)责任链执行完毕后,会返回最终响应数据,如果返回结果为空,即无网络情况下,关闭缓存
3)如果cacheResponse缓存不为空并且最终响应数据的返回码为304,那么就直接从缓存中读取数据,否则关闭缓存
4)有网络状态下,直接返回最终响应数据
5)如果Http头部是否有响应体且缓存策略是可以缓存的,true=将响应体写入到Cache,下次直接调用
6)判断最终响应数据的是否是无效缓存方法,true,则从Cache清除掉
7)返回Response
ConnectInterceptor
负责与服务器建立链接
/** Opens a connection to the target server and proceeds to the next interceptor. */
public final class ConnectInterceptor implements Interceptor {
public final OkHttpClient client;
public ConnectInterceptor(OkHttpClient client) {
this.client = client;
}
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
// 建立执行Http请求所需要的对象
// 主要用于 ①获取连接服务端的Connection ②连接用于服务端进行数据传输的输入输出流
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
上面我们讲到重定向拦截器时,发现RetryAndFollowUpInterceptor创建初始化StreamAllocation,但没有使用,只是跟着拦截器链传递给下一个拦截器,最终会传到ConnectInterceptor中使用。从上面代码可以看出ConnectInterceptor主要执行的流程:
1.ConnectInterceptor获取Interceptor传过来的StreamAllocation,streamAllocation.newStream。
2.将刚才创建的用于网络IO的RealConnection对象以及对于与服务器交互最为关键的HttpCodec等对象传递给后面的拦截。
ConnectInterceptor的Interceptor代码很简单,但是关键代码还是在streamAllocation.newStream(…)方法里,在这个方法完成所有链接的建立。
public HttpCodec newStream(
OkHttpClient client, Interceptor.Chain chain, boolean doExtensiveHealthChecks) {
int connectTimeout = chain.connectTimeoutMillis();
int readTimeout = chain.readTimeoutMillis();
int writeTimeout = chain.writeTimeoutMillis();
int pingIntervalMillis = client.pingIntervalMillis();
boolean connectionRetryEnabled = client.retryOnConnectionFailure();
try {
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, pingIntervalMillis, connectionRetryEnabled, doExtensiveHealthChecks);
HttpCodec resultCodec = resultConnection.newCodec(client, chain, this);
synchronized (connectionPool) {
codec = resultCodec;
return resultCodec;
}
} catch (IOException e) {
throw new RouteException(e);
}
}
这里的流程主要就是
1.调用findHealthyConnection来创建RealConnection进行实际的网络连接(能复用就复用,不能复用就新建)
2.通过获取到的RealConnection来创建HttpCodec对象并通过同步代码中返回
我们具体往findHealthyConnection看
/**
* Finds a connection and returns it if it is healthy. If it is unhealthy the process is repeated
* until a healthy connection is found.
* 找到一个健康的连接并返回它。 如果不健康,则重复该过程直到发现健康的连接。
*/
private RealConnection findHealthyConnection(int connectTimeout, int readTimeout,
int writeTimeout, boolean connectionRetryEnabled, boolean doExtensiveHealthChecks)
throws IOException {
while (true) {
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,
connectionRetryEnabled);
// If this is a brand new connection, we can skip the extensive health checks.
// 如果这是一个全新的联系,我们可以跳过广泛的健康检查
synchronized (connectionPool) {
if (candidate.successCount == 0) {
return candidate;
}
}
// Do a (potentially slow) check to confirm that the pooled connection is still good. If it
// isn't, take it out of the pool and start again.
// 做一个(潜在的慢)检查,以确认汇集的连接是否仍然良好。 如果不是,请将其从池中取出并重新开始。
if (!candidate.isHealthy(doExtensiveHealthChecks)) {
noNewStreams();
continue;
}
return candidate;
}
}
1.首先开启while(true){}循环,循环不断地从findConnection方法中获取Connection对象
2.然后在同步代码块,如果满足candidate.successCount ==0(就是整个网络连接结束了),就返回
3.接着判断如果这个candidate是不健康的,则执行销毁并且重新调用findConnection获取Connection对象
不健康的RealConnection条件为如下几种情况:
①RealConnection对象的socket没有关闭 ②socket的输入流没有关闭 ③socket的输出流没有关闭 ④http2时连接没有关闭
我们接着看findConnection中具体做了什么操作
/**
* Returns a connection to host a new stream. This prefers the existing connection if it exists,
* then the pool, finally building a new connection.
*/
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
boolean connectionRetryEnabled) throws IOException {
boolean foundPooledConnection = false;
RealConnection result = null;
Route selectedRoute = null;
Connection releasedConnection;
Socket toClose;
synchronized (connectionPool) {
if (released) throw new IllegalStateException("released");
if (codec != null) throw new IllegalStateException("codec != null");
if (canceled) throw new IOException("Canceled");
// Attempt to use an already-allocated connection. We need to be careful here because our
// already-allocated connection may have been restricted from creating new streams.
//选择尝试复用Connection
releasedConnection = this.connection;
toClose = releaseIfNoNewStreams();
//判断可复用的Connection是否为空
if (this.connection != null) {
// We had an already-allocated connection and it's good.
result = this.connection;
releasedConnection = null;
}
if (!reportedAcquired) {
// If the connection was never reported acquired, don't report it as released!
// 如果连接从未被报告获得,不要报告它被释放
releasedConnection = null;
}
//如果RealConnection不能复用,就从连接池中获取
if (result == null) {
// Attempt to get a connection from the pool.
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
foundPooledConnection = true;
result = connection;
} else {
selectedRoute = route;
}
}
}
closeQuietly(toClose);
if (releasedConnection != null) {
eventListener.connectionReleased(call, releasedConnection);
}
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result);
}
if (result != null) {
// If we found an already-allocated or pooled connection, we're done.
return result;
}
// If we need a route selection, make one. This is a blocking operation.
boolean newRouteSelection = false;
if (selectedRoute == null && (routeSelection == null || !routeSelection.hasNext())) {
newRouteSelection = true;
routeSelection = routeSelector.next();
}
synchronized (connectionPool) {
if (canceled) throw new IOException("Canceled");
if (newRouteSelection) {
// Now that we have a set of IP addresses, make another attempt at getting a connection from
// the pool. This could match due to connection coalescing.
// 遍历所有路由地址,再次尝试从ConnectionPool中获取connection
List routes = routeSelection.getAll();
for (int i = 0, size = routes.size(); i < size; i++) {
Route route = routes.get(i);
Internal.instance.get(connectionPool, address, this, route);
if (connection != null) {
foundPooledConnection = true;
result = connection;
this.route = route;
break;
}
}
}
if (!foundPooledConnection) {
if (selectedRoute == null) {
selectedRoute = routeSelection.next();
}
// Create a connection and assign it to this allocation immediately. This makes it possible
// for an asynchronous cancel() to interrupt the handshake we're about to do.
route = selectedRoute;
refusedStreamCount = 0;
result = new RealConnection(connectionPool, selectedRoute);
acquire(result, false);
}
}
// If we found a pooled connection on the 2nd time around, we're done.
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result);
return result;
}
// Do TCP + TLS handshakes. This is a blocking operation.
//进行实际网络连接
result.connect(
connectTimeout, readTimeout, writeTimeout, connectionRetryEnabled, call, eventListener);
routeDatabase().connected(result.route());
Socket socket = null;
synchronized (connectionPool) {
reportedAcquired = true;
// Pool the connection.
//获取成功后放入到连接池当中
Internal.instance.put(connectionPool, result);
// If another multiplexed connection to the same address was created concurrently, then
// release this connection and acquire that one.
if (result.isMultiplexed()) {
socket = Internal.instance.deduplicate(connectionPool, address, this);
result = connection;
}
}
closeQuietly(socket);
eventListener.connectionAcquired(call, result);
return result;
}
代码量很多,重点我都标识出来方便理解,大致流程如下:
1.首先判断当前StreamAllocation对象是否存在Connection对象,有则返回(能复用就复用)
2.如果1没有获取到,就去ConnectionPool中获取
3.如果2也没有拿到,则会遍历所有路由地址,并再次尝试从ConnectionPool中获取
4.如果3还是拿不到,就尝试重新创建一个新的Connection进行实际的网络连接
5.将新的Connection添加到ConnectionPool连接池中去,返回结果
从流程中可以,findConnection印证了其命名,主要都是在如何寻找可复用的Connection连接,能复用就复用,不能复用就重建,这里我们注重关注result.connect(),它是怎么创建一个可进行实际网络连接的Connection
public void connect(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled, Call call,
EventListener eventListener) {
//检查链接是否已经建立,protocol 标识位代表请求协议,在介绍OkHttpClient的Builder模式下参数讲过
if (protocol != null) throw new IllegalStateException("already connected");
RouteException routeException = null;
//Socket链接的配置
List connectionSpecs = route.address().connectionSpecs();
//用于选择链接(隧道链接还是Socket链接)
ConnectionSpecSelector connectionSpecSelector = new ConnectionSpecSelector(connectionSpecs);
while (true) {
try {
//是否建立Tunnel隧道链接
if (route.requiresTunnel()) {
connectTunnel(connectTimeout, readTimeout, writeTimeout, call, eventListener);
if (rawSocket == null) {
// We were unable to connect the tunnel but properly closed down our resources.
break;
}
} else {
connectSocket(connectTimeout, readTimeout, call, eventListener);
}
establishProtocol(connectionSpecSelector, pingIntervalMillis, call, eventListener);
eventListener.connectEnd(call, route.socketAddress(), route.proxy(), protocol);
break;
} catch (IOException e) {
closeQuietly(socket);
closeQuietly(rawSocket);
socket = null;
rawSocket = null;
source = null;
sink = null;
handshake = null;
protocol = null;
http2Connection = null;
eventListener.connectFailed(call, route.socketAddress(), route.proxy(), null, e);
}
}
}
我们这里留下重点代码来讲解
1.首先判断当前protocol协议是否为空,如果不为空,则抛出异常(链接已存在)
2.创建Socket链接配置的list集合
3.通过2创建好的list构造了一个ConnectionSpecSelector(用于选择隧道链接还是Socket链接)
4.接着执行while循环,route.requiresTunnel()判断是否需要建立隧道链接,否则建立Socket链接
5.执行establishProtocol方法设置protocol协议并执行网络请求
ConnectionPool
不管protocol协议是http1.1的Keep-Live机制还是http2.0的Multiplexing机制都需要引入连接池来维护整个链接,而OkHttp会将客户端和服务端的链接作为一个Connection类,RealConnection就是Connection的实现类,ConnectionPool连接池就是负责维护管理所有Connection,并在有限时间内选择Connection是否复用还是保持打开状态,超时则及时清理掉
Get方法
//每当要选择复用Connection时,就会调用ConnectionPool的get方法获取
@Nullable RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection, true);
return connection;
}
}
return null;
}
首先执行for循环遍历Connections队列,根据地址address和路由route判断链接是否为可复用,true则执行streamAllocation.acquire返回connection,这里也就明白之前讲解findConnection时,ConnectionPool时怎么查找并返回可复用的Connection的
/**
* Use this allocation to hold {@code connection}. Each call to this must be paired with a call to
* {@link #release} on the same connection.
*/
public void acquire(RealConnection connection, boolean reportedAcquired) {
assert (Thread.holdsLock(connectionPool));
if (this.connection != null) throw new IllegalStateException();
this.connection = connection;
this.reportedAcquired = reportedAcquired;
connection.allocations.add(new StreamAllocationReference(this, callStackTrace));
}
public final List> allocations = new ArrayList<>();
首先就是把从连接池中获取到的RealConnection对象赋值给StreamAllocation的connection属性,然后把StreamAllocation对象的弱引用添加到RealConnection对象的allocations集合中去,判断出当前链接对象所持有的StreamAllocation数目,该数组的大小用来判定一个链接的负载量是否超过OkHttp指定的最大次数。
Put方法
我们在讲到findConnection时,ConnectionPool如果找不到可复用的Connection,就会重新创建一个Connection并通过Put方法添加到ConnectionPool中
void put(RealConnection connection) {
assert (Thread.holdsLock(this));
if (!cleanupRunning) {
cleanupRunning = true;
// 异步回收线程
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
private final Deque connections = new ArrayDeque<>();
在这里我们可以看到,首先在进行添加队列之前,代码会先判断当前的cleanupRunning(当前清理是否正在执行),符合条件则执行cleanupRunnable异步清理任务回收连接池中的无效连接,其内部时如何执行的呢?
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
// 下次清理的间隔时间
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
// 等待释放锁和时间间隔
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
这里我们重点看cleanUp方法是如何清理无效连接的,请看代码
long cleanup(long now) {
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
// Find either a connection to evict, or the time that the next eviction is due.
synchronized (this) {
// 循环遍历RealConnection
for (Iterator i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// If the connection is in use, keep searching.
// 判断当前connection是否正在使用,true则inUseConnectionCount+1,false则idleConnectionCount+1
if (pruneAndGetAllocationCount(connection, now) > 0) {
// 正在使用的连接数
inUseConnectionCount++;
continue;
}
// 空闲连接数
idleConnectionCount++;
// If the connection is ready to be evicted, we're done.
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
//
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// 如果被标记的连接数超过5个,就移除这个连接
// We've found a connection to evict. Remove it from the list, then close it below (outside
// of the synchronized block).
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
//如果上面处理返回的空闲连接数目大于0。则返回保活时间与空闲时间差
// A connection will be ready to evict soon.
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
// 如果上面处理返回的都是活跃连接。则返回保活时间
// All connections are in use. It'll be at least the keep alive duration 'til we run again.
return keepAliveDurationNs;
} else {
// 跳出死循环
// No connections, idle or in use.
cleanupRunning = false;
return -1;
}
}
closeQuietly(longestIdleConnection.socket());
// Cleanup again immediately.
return 0;
}
- for循环遍历connections队列,如果当前的connection对象正在被使用,则
inUseConnectionCount+1 (活跃连接数),跳出当前判断逻辑,执行下一个判断逻辑,否则idleConnectionCount+1(空闲连接数) - 判断
当前的connection对象的空闲时间是否比已知的长,true就记录 - 如果
空闲连接的时间超过5min,空闲连接的数量超过5,就直接从连接池中移除,并关闭底层socket,返回等待时间0,直接再次循环遍历连接池(这是个死循环) - 如果3不满足,
判断idleConnectionCount是否大于0 (返回的空闲连接数目大于0)。则返回保活时间与空闲时间差 - 如果4不满足,判断有没有正在使用的连接,有的话返回保活时间
- 如果5也不满足,当前说明连接池中没有连接,
跳出死循环返回-1
这里可以算是核心代码,引用Java GC算法中的标记-擦除算法,标记处最不活跃的连接进行清除。每当要创建一个新的Connection时,ConnectionPool都会循环遍历整个connections队列,标记查找不活跃的连接,当不活跃连接达到一定数量时及时清除,这也是OkHttp 连接复用的核心。
还有一点要注意,pruneAndGetAllocationCount方法就是判断当前connection对象是空闲还是活跃的
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
List> references = connection.allocations;
for (int i = 0; i < references.size(); ) {
Reference reference = references.get(i);
if (reference.get() != null) {
i++;
continue;
}
// We've discovered a leaked allocation. This is an application bug.
StreamAllocation.StreamAllocationReference streamAllocRef =
(StreamAllocation.StreamAllocationReference) reference;
String message = "A connection to " + connection.route().address().url()
+ " was leaked. Did you forget to close a response body?";
Platform.get().logCloseableLeak(message, streamAllocRef.callStackTrace);
references.remove(i);
connection.noNewStreams = true;
// If this was the last allocation, the connection is eligible for immediate eviction.
if (references.isEmpty()) {
connection.idleAtNanos = now - keepAliveDurationNs;
return 0;
}
}
return references.size();
}
1.首先for循环遍历RealConnection的StreamAllocation List列表,判断每个StreamAllocation是否为空,false则表示无对象引用这个StreamAllocation,及时清除,执行下一个逻辑判断(这里有个坑,当作彩蛋吧)
2.接着判断如果当前StreamAllocation集合因为1的remove而导致列表为空,即没有任何对象引用,返回0结束
3.返回结果
CallServerInterceptor
负责发起网络请求和接受服务器返回响应
/** This is the last interceptor in the chain. It makes a network call to the server. */
public final class CallServerInterceptor implements Interceptor {
private final boolean forWebSocket;
public CallServerInterceptor(boolean forWebSocket) {
this.forWebSocket = forWebSocket;
}
@Override public Response intercept(Chain chain) throws IOException {
// 拦截器链
RealInterceptorChain realChain = (RealInterceptorChain) chain;
// HttpCodec接口,封装了底层IO可以直接用来收发数据的组件流对象
HttpCodec httpCodec = realChain.httpStream();
// 用来Http网络请求所需要的组件
StreamAllocation streamAllocation = realChain.streamAllocation();
// Connection类的具体实现
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
long sentRequestMillis = System.currentTimeMillis();
realChain.eventListener().requestHeadersStart(realChain.call());
// 先向Socket中写请求头部信息
httpCodec.writeRequestHeaders(request);
realChain.eventListener().requestHeadersEnd(realChain.call(), request);
Response.Builder responseBuilder = null;
//询问服务器是否可以发送带有请求体的信息
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) {
// If there's a "Expect: 100-continue" header on the request, wait for a "HTTP/1.1 100
// Continue" response before transmitting the request body. If we don't get that, return
// what we did get (such as a 4xx response) without ever transmitting the request body.
//特殊处理,如果服务器允许请求头部可以携带Expect或则100-continue字段,直接获取响应信息
if ("100-continue".equalsIgnoreCase(request.header("Expect"))) {
httpCodec.flushRequest();
realChain.eventListener().responseHeadersStart(realChain.call());
responseBuilder = httpCodec.readResponseHeaders(true);
}
if (responseBuilder == null) {
// Write the request body if the "Expect: 100-continue" expectation was met.
realChain.eventListener().requestBodyStart(realChain.call());
long contentLength = request.body().contentLength();
CountingSink requestBodyOut =
new CountingSink(httpCodec.createRequestBody(request, contentLength));
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
// 向Socket中写入请求信息
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
realChain.eventListener()
.requestBodyEnd(realChain.call(), requestBodyOut.successfulCount);
} else if (!connection.isMultiplexed()) {
// If the "Expect: 100-continue" expectation wasn't met, prevent the HTTP/1 connection
// from being reused. Otherwise we're still obligated to transmit the request body to
// leave the connection in a consistent state.
streamAllocation.noNewStreams();
}
}
// 完成网络请求的写入
httpCodec.finishRequest();
if (responseBuilder == null) {
realChain.eventListener().responseHeadersStart(realChain.call());
//读取响应信息的头部
responseBuilder = httpCodec.readResponseHeaders(false);
}
Response response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
realChain.eventListener()
.responseHeadersEnd(realChain.call(), response);
int code = response.code();
//
if (forWebSocket && code == 101) {
// Connection is upgrading, but we need to ensure interceptors see a non-null response body.
response = response.newBuilder()
.body(Util.EMPTY_RESPONSE)
.build();
} else {
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
}
//
if ("close".equalsIgnoreCase(response.request().header("Connection"))
|| "close".equalsIgnoreCase(response.header("Connection"))) {
streamAllocation.noNewStreams();
}
if ((code == 204 || code == 205) && response.body().contentLength() > 0) {
throw new ProtocolException(
"HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
}
return response;
}
其实代码很简单,我们这里只做OkHttp上的讲解,关于HttpCodec(HttpCodec接口,封装了底层IO可以直接用来收发数据的组件流对象)可以去相关文献中了解。流程如下
1.首先初始化对象,同时调用httpCodec.writeRequestHeaders(request)向Socket中写入Header信息
2.判断服务器是否可以发送带有请求体的信息,返回为True时会做一个特殊处理,判断服务器是否允许请求头部可以携带Expect或则100-continue字段(握手操作),可以就直接获取响应信息
3.当前面的"100-continue",需要握手,但又握手失败,如果body信息为空,并写入请求body信息,否则判断是否是多路复用,满足则关闭写入流和Connection
4.完成网络请求的写入
5.判断body信息是否为空(即表示没有处理特殊情况),就直接读取响应的头部信息,并通过构造者模式一个写入原请求,握手情况,请求时间,得到的结果时间的Response
6.通过状态码判断以及是否webSocket判断,是否返回一个空的body,true则返回空的body,否则读取body信息
7.如果设置了连接 close ,断开连接,关闭写入流和Connection
8.返回Response
到此,OkHttp内部5大拦截器的作用已经讲解完成,流程大致如下
