齐姐漫画:排序算法(一)




插入排序
借用《算法导论》里的例子,就是我们打牌的时候,每新拿一张牌都会把它按顺序插入,这,其实就是插入排序。

齐姐声明:虽然我们用打牌的例子,但是可不能学胡适先生啊。

对于数组来说怎么做呢?
有一个重要的思想,叫做挡板法,就是用挡板把数组分成两个区间:
挡板左边:已排序
挡板右边:未排序
那么排序分三步走:
最初挡板是在数组的最左边,保证已排序区间里一个数都没有,或者也可以包含一个数啦;
核心思想就是:
依次遍历未排序区间里的元素,在已排序区间里找到正确的位置插入;重复这个过程,直到未排序区间为空。
举个例子:{5, 2, 1, 0}
第一步,挡板最初在这里:

第二步, 把 2 插入已排序区间的正确位置,变成:
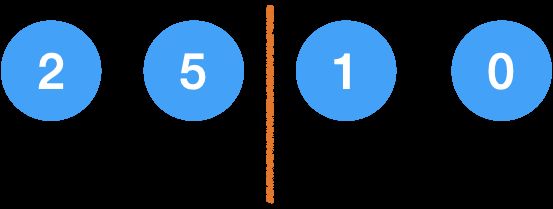
重复这个步骤,把 1 排好:

最后把 0 排好:

那代码也很简单:
public void insertionSort(int[] input) {
if(input == null || input.length <= 1) {
return;
}
for(int i = 1; i < input.length; i++) {
int tmp = input[i];
int j = i - 1;
while(j >= 0 && input[j] > tmp) {
input[j+1] = input[j];
j --;
}
input[j+1] = tmp;
}
}
我们来分析一下这个算法的时空复杂度。
时间复杂度
关于时间复杂度大 O 有两个要点:
是描述随着自变量的增长,所需时间的增长率;
是渐近线复杂度,就是说
不看系数
只看最高阶项
那么我们关心的 worst case 的情况就是:
如果数组是近乎倒序的,每次插入都要在数组的第一个位置插入,那么已排序区间内的所有的元素都要往后移动一位,这一步平均是 O(n),那么重复 n 次就是 O(n^2).
空间复杂度
重点是一个峰值的概念,并不是累计使用的空间。
这里是 O(1) 没什么好说的。
引入一个概念:sorted in place,也就是原地排序。
原地排序就是指空间复杂度为 O(1) 的算法,因为没有占用额外的空间,就是原地打转嘛。
其实 in-place 的思想并不是只在排序算法里有,只不过排序算法是一个最广为人知的例子罢了。本质上就是一个节省使用空间的思想。
但是对于排序算法,只分析它的时空复杂度是不够的,还有另外一个重要指标:
稳定性
意思是元素之间的相对顺序是否保持了不变。
比如说:{5, 2, 2, 1, 0}
这个数组排序完成后这里面的两个 2 的相对顺序没有变,那么这个排序就是一个稳定排序。
那有同学可能就想,顺序变了又有什么关系呢?
其实,在实际工作中我们排序的对象不会只是一个数字,而是一个个的对象 (object),那么先按照对象的一个性质来排序,再按照另一个性质来排序,那就不希望原来的那个顺序被改变了。好像有点抽象,我们举个例子。
比如在股票交易系统里,有买卖双方的报价,那是如何匹配的呢?
先按照价格排序;
在相等的价格中,按照出价的时间顺序来排序。
那么一般来说系统会维持一个按时间排序的价格序列,那么此时只需要用一个具有稳定性的排序算法,再按照价格大小来排序就好了。因为稳定性的排序算法可以保持大小相同的两个对象仍维持着原来的时间顺序。
那么插入排序是否是稳定性的排序呢?
答案是肯定的。因为在我们插入新元素的时候是从后往前检查,并不是像打牌的时候随便插一个位置不能保证相对顺序。
大家可以看下面的动画[1] 就非常清楚了~

优化
插入排序其实是有很大的优化空间的,你可以搜一下“希尔排序”。
在刚开始学习的时候,深度固然重要,但因为广度不够,如果学的太深可能会很痛苦,一个知识点就无穷无尽的延展,这并不是一个高效的学习方式。
所以如果时间有限,就要做好深度和广度的平衡:
在常用常考的知识点上多花时间精力,追求深度;
在一些拓展性的知识点上点到为止,先知道有这么回事就行。
保持 open minded 的心态,后期就会有质的提高。


选择排序
选择排序也是利用了“挡板法”这个经典思想。
挡板左边是已排序区间,右边是未排序区间,那么每次的“选择”是去找右边未排序区间的最小值,找到之后和挡板后面的第一个值换一下,然后再把挡板往右移动一位,保证排好序的这些元素在挡板的左边。
比如之前的例子:{5, 2, 0, 1}
我们用一个挡板来分隔数组是否排好序,
用指针 j 来寻找未排序区间的最小值;

第一轮 j 最初指向 5,然后遍历整个未排序区间,最终指向 0,那么 0 就和挡板后的第一个元素换一下,也就是和 5 交换一下位置,挡板向右移动一位,结束第一轮。
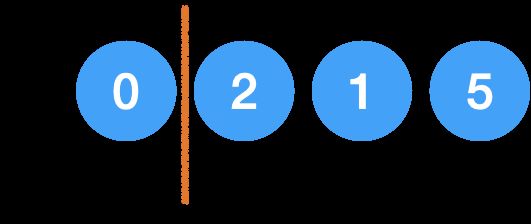
第二轮,j 从挡板后的2开始遍历,最终指向1,然后1和挡板后的第一个元素 2 换一下,挡板向右移动一位,结束第二轮。
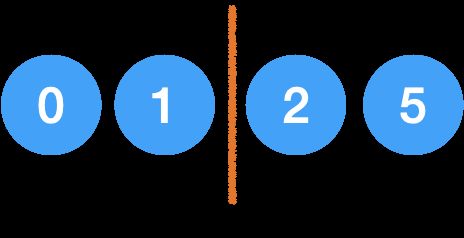
第三轮,j 从2开始遍历,最终指向2,然后和2自己换一下,挡板向右移动一位,结束第三轮。
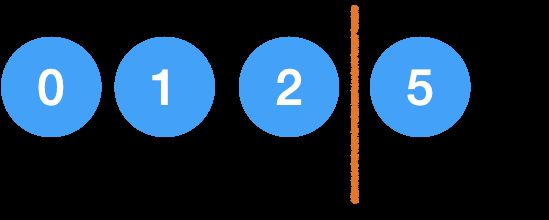
还剩一个元素,不用遍历了,就结束了。
选择排序与之前的插入排序对比来看,要注意两点:
挡板必须从 0 开始,而不能从 1 开始。虽然在这两种算法中,挡板的物理意义都是分隔已排序和未排序区间,但是它们的已排序区间里放的元素的意义不同:
选择排序是只能把当前的最小值放进来,而不能放其他的;
插入排序的第一个元素可以为任意值。
所以选择排序的挡板左边最开始不能有任何元素。
在外层循环时,
选择排序的最后一轮可以省略,因为只剩下最大的那个元素了;
插入排序的最后一轮不可省略,因为它的位置还没定呢。
class Solution {
public void selectionSort(int[] input) {
if(input == null || input.length <= 1) {
return;
}
for(int i = 0; i < input.length - 1; i++) {
int minValueIndex = i;
for(int j = i + 1; j < input.length; j++) {
if(input[j] < input[minValueIndex]) {
minValueIndex = j;
}
}
swap(input, minValueIndex, i);
}
}
private void swap(int[] input, int x, int y) {
int tmp = input[x];
input[x] = input[y];
input[y] = tmp;
}
}

时间复杂度
最内层的 if 语句每执行一次是 O(1) ,那么要执行多少次呢?
当 i = 0 时,是 n-1 次;
当 i = 1 时,是 n-2 次;
...
最后是 1 次;
所以加起来,总共是:
(n-1) + (n-2) + … + 1 = n*(n-1) / 2 = O(n^2)
是这样算出来的,而不是一拍脑袋说两层循环就是 O(n^2).
空间复杂度
这个很简单,最多的情况是 call swap() 的时候,然后 call stack 上每一层就用了几个有限的变量,所以是 O(1)。
那自然也是原地排序算法了。
稳定性
这个答案是否定的,选择排序并没有稳定性。
因为交换的过程破坏了原有的相对顺序,比如: {5, 5, 2, 1, 0} 这个例子,第一次交换是 0 和 第一个 5 交换,于是第一个 5 跑到了数组的最后一位,且再也无翻身之地,所以第一个 5 第二个 5 的相对顺序就已经打乱了。
这个问题在石头哥的那篇谷歌面经文章里有被考到哦,如果还没有看过这篇面经文章的,在公众号里回复「谷歌」二字,就可以看到了。
优化
选择排序的其中一步是选出每一轮的最小值,那么这一步如果使用 heapify() 来优化,就可以从 O(n) 优化到 O(logn),这其实就变成了 heapSort.




推荐阅读
1、回炉重铸, 91 天见证不一样的自己
2、别再暴力匹配字符串了,高效的KMP才是真的香!
3、揭开「拓扑排序」的神秘面纱
4、你不知道的 React 最佳实践
5、或许是一本可以彻底改变你刷 LeetCode 效率的题解书
6、迎接Vue3.0 | 在Vue2与Vue3中构建相同的组件
7、扒一扒这种题的外套(343. 整数拆分)


如果觉得文章不错,帮忙点个在看呗
参考资料
[1]
排序动画: https://visualgo.net/en/sorting