数据清洗——处理缺失值
我们最初的数据会因为各种各样的原因——信息无法获取,被遗漏——而产生缺失值。pandas使用NaN(Not a Number)来表示缺失值。处理缺失值的方式主要有两个——过滤缺失值或补全缺失值。
下表是处理缺失值的相关函数列表:
| 函数名 | 描述 |
|---|---|
| dropna | 根据每个标签的值是否是缺失数据来筛选轴标签 |
| fillna | 用某些值填充缺失值 |
| isnull | 返回表明哪些值是缺失值的布尔值 |
| notnull | isnull的反函数 |
一、过滤缺失值
将存在遗漏信息属性值的对象(元组,记录)删除,从而得到一个完备的信息表。显而易见,这种方法会丢弃大量隐藏在这些对象中的信息,所以,在缺失数据占比较大的情况下最好不要用。在对象有多个属性缺失值、被删除的含缺失值的对象与初始数据集的数据量相比非常小的情况下非常有效。
dropna是过滤缺失值时非常有用的函数。默认情况下会删除包含缺失值的行。
data = pd.Series([1, np.nan, 3.5, np.nan, 9])
data.dropna()

data = pd.DataFrame([[1, 4, 5], [2, np.nan, np.nan],
[np.nan, np.nan, np.nan], [np.nan, 5, 6]])
data.dropna()

传入how='all’时,将删除所有值均为NaN的行:
data.dropna(how='all')

传入axis=1,删除列:
data = pd.DataFrame([[1, 4, 5], [2, np.nan, np.nan],
[9, np.nan, np.nan], [9, 5, 6]])
data.dropna(axis=1)
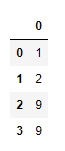
传入thresh=n,只保留至少有n个非NAN值的行:
data = pd.DataFrame([[1, 4, 5], [2, np.nan, np.nan],
[9, np.nan, 8], [9, 5, 6]])
data

data.dropna(thresh=2)
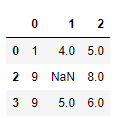
data.dropna(thresh=3)

用subset删除指定列中包含缺失值的行:
data.dropna(subset=[2])

二、补全缺失值
过滤缺失值会造成信息缺失,所以我们有时会用多种方式补全漏洞,而不是过滤。我们主要使用fillna方式来补全。
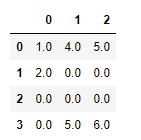
可以用常数补全:
data = pd.DataFrame([[1, 4, 5],
[2, np.nan, np.nan],
[np.nan, np.nan, np.nan],
[np.nan, 5, 6]])
data.fillna(0)
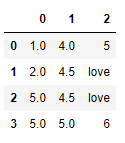
可以用字典为不同的列设置不同的填充值:
data.fillna({0: 5, 1: data[1].mean(), 2: 'love'})
上面例子中的缺失值都是数值,数值型的缺失值最好用该属性所有对象的平均值来填充,而非数值型的缺失值最好用该属性的所有对象取值最多的值来填充(众数)。