【理解归纳】tensorflow-gpu 1.14.0版本安装与anaconda包与环境的管理
一开始我用的是cpu版本的tensorflow2.0.0,直接调模型的语法非常简洁,再者我的笔记本是有gpu的(现在哪台笔记本还能没gpu。。。)
于是想充分利用gpu来提速,再延续tensoflow2的简洁语法,装一个tensoflow-gpu 2.0.0
结果10小时过去了,愣是没弄成功!import tensorflow要么还是cpu版本,要么就直接导入失败,说找不到模块。
装失败的原因非常多,有配件版本不匹配,显卡驱动没装上,不懂环境管理的操作等等
后面想着,也不管什么简洁语法了,只要是tensorflow-gpu就行,别说1点几,哪怕是零点几的版本也好,求求你给我装上吧!!!
终于又过了5小时,在同学兔兔兔兔兔子拯救世界的不辞辛劳的帮助与演示、操作下,我总算装成功了tensorflow-gpu 1.14.0

看着结果一行行蹦出来,看到“True”的那一瞬间真是感慨万千,有种十月怀胎的小孩终于呱呱坠地的感觉
首先声明我的电脑配置:
GPU是GeForce GTX 1050,最高支持10.0版本的CUDA
Pyhton=3.6.3
即将安装的是1.14.0版本的tensorflow-gpu,配套CUDA为10.0,cuDNN为7.6
接下来我就说一说自己对今天整个过程的认识
一、GPU版本的tensorflow有什么不同?为什么?
优点:
使用了GPU的tensorflow,犹如一把宝剑再装上一颗传奇宝石,对于大量的数据集,在训练过程中可以大幅度提升速度。比如同样是对10000张图片进行训练,CPU版本的tensorflow需要5分钟才能完成一轮,但GPU版本可能只需要30秒,速度大幅提升。如果一口气训练个100轮,那就是数小时的时间节省了。
为什么这么快?(比喻层面)
如果把GPU比作一辆车,CUDA就是车的驱动系统,驱动系统上有很多东西,比如方向盘,离合器,发动机等等,而cuDNN(英伟达深度学习框架)这个东西就是车的方向盘,如果我们需要,也可以安装别的构件,比如离合器,操作杆,但是要记住,像cuDNN这样的都是组件,是额外加到驱动系统CUDA上去的,CUDA才是承载这些组件的核心,而GPU就是核心CUDA背后的硬件支持
而tensorflow-gpu,就是驾驶员,我们运行代码时,tensorflow就去调用那个深度学习框架来加速,而深度学习框架是建立在CUDA上的,而CUDA又是建立在硬件GPU上的。所以tensoflow的版本和cuDNN的一对一性质很强,而cuDNN又依赖于CUDA的版本,CUDA又取决于GPU的类型,就很头秃,到底哪个tensorflow该配哪个系列的版本,众说纷纭。。。
背后怎么操作的?(个人理解)
GPU版本的tensorflow安装之后,包里面有一些.py文件会去调取电脑的硬件结构进行数据部署,比如get_available_gpu(), load_data2(gpu_device[i])。
我们知道python有os,sys等包,是直接对计算机深层做操作的,权限相当高,于是在这个过程中,后台就会运行一些程序,比如进入系统的cmd窗口,直接运行cudart_64等文件来进行cuDNN的操作。
既然说到cmd运行文件,那肯定又要提到 配置环境变量了
我们经常在anaconda prompt里敲下python,然后进入python的编辑环境,开始写简单的测试代码,这背后其实就是一个叫做“环境变量”的东西在起作用,直接敲python,电脑就知道这肯定不是一个动宾结构的命令(比如cd E:\File),而是要打开某个文件,于是系统就去一个库里面找了,这个库里有一堆的文件夹(也就是路径),系统会从上往下挨个进去看一遍,里面有没有python.exe这个文件可以打开,找不到就换下一个文件夹再试试,直到找完这个库。当然往往能够找到。这个库是啥呢?其实就是系统的 “环境变量”的Path,在左下角的搜索框中输入huanjing
进入,点击 环境变量,进入这个页面
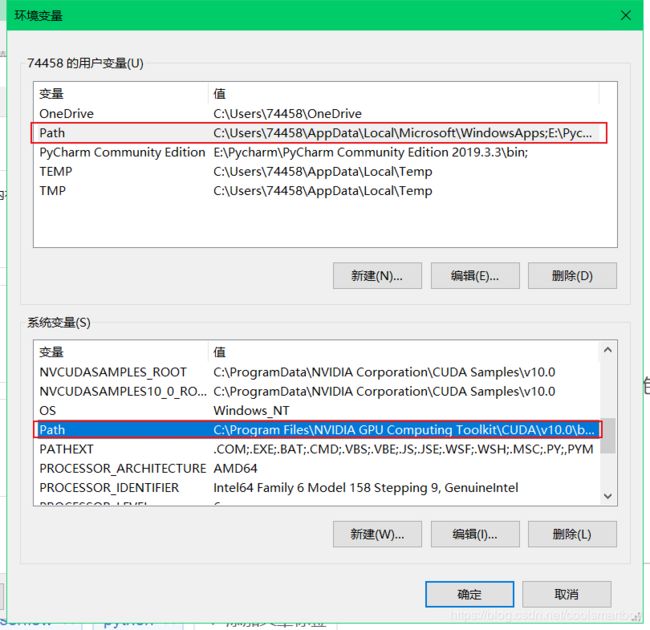
这两个Path都是检索库,编辑其中一个是这样的

看到了吧?一堆的文件夹在那,等着电脑去挨个检索,不过检索时,用户变量的Path优先,用户变量找不到了就去系统变量中找
所以说我们需要为安装好的CUDA和cuDNN配置好环境变量,让cmd可以直接打开里面的文件,这样tensorflow在运行时才能打开所需要的文件
落地到具体操作上,那就是去英伟达官网下载10.0版本的CUDA安装包和7.6.5的cuDNN压缩包

安装cuda时,路径切记要默认,哪怕你的c盘小的不行也要留出空间,选择自定义安装,每个选项都展开,不要安装Visual Studio和Geforce Experience。
打开cuDNN,里面有lib,bin等文件夹。打开bin,把里面的东西复制,然后打开cuda的bin文件夹,在里面粘贴。同理把cuDNN
另外两个文件的内容也放到cuda的对应文件夹里。再把https://cn.dll-files.com/cudart64_101.dll.html链接里的文件加入到cuda的bin中
再将以下命令添加到系统环境变量的Path里面
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include
现在离成功安装tensorflow-gpu还差两步:pip install ‘本地tensorflow轮子文件’,以及更新英伟达的驱动程序并重启。下次更新再写剩下的,太晚了
————————————————————————————————————————————————————
时隔一月,再回来更新。
上文提到cuda和cuDNN的安装,这两者是使用gpu的基础。装好了这两者就好说了!先去百度找到自己的Python版本(比如我的是3.6)对应要装的gpu版本的tf,比如tensorflow-1.14.0-gpu的whl文件,注意不能直接去pip install,这样会导致装一些别的东西导致失败,然后本地安装该whl文件。比如下载下来的这个whl路径是C:\Desktop\tf-1.14.0-gpu.whl,那么就进入自己需要的那个虚拟环境,pip install C:\Desktop\tf-1.14.0-gpu.whl即可。
这里说到虚拟环境,那么我再介绍一下对虚拟环境的理解
在anaconda的anaconda prompt中,我们可以进行建立、进入、删除等对环境的管理操作。那么到底什么是虚拟环境呢?
所谓环境,其实就是你写代码时调用的各种包构成的整体,Python本身也可以看成一种包,比如python3.6和python3.7就是两个不同的包,除此之外这个环境内可能还有numpy,matplotlib这些。如果另一个环境里只有python和pandas这两个包,我们就可以看出这两个环境的不同。
prompt使用特定的语句可以进行环境的新建和激活(进入)。默认情况下我们一直处在一个叫做base的环境中,base之所以叫base,是因为别的环境都可以直接调用base中拥有的包。但是别的不同的两个环境的包就是相互隔离独立,无法互相调用的。
当我们进入新建的环境时(以tf_gpu这个名字为例),在里面pip install或者 conda install,会把包安装到E:\Python\envs\tf_gpu\Lib中。
好,现在在自己的环境中装好了tf,理论上来说就可以直接运行了,但是我们还有一件事要做,那就是更新显卡驱动。百度英伟达显卡驱动更新,找到自己的显卡对应的选项然后下载更新包,全程大概一小时,重启一下,就可以运行tf gpu版本啦!来试试:
import tensorflow as tf
print('GPU',tf.test.is_gpu_available())
如果成功了,也把gpu版本pytorch装一下吧!所需要做的只是找到你想安装的gpu torch版本(比如1.0.1)以及对应的torchvision的whl,安装一下就行了
全文总结一下,想装某个gpu版本的tensorflow,那么你必须要根据你的显卡版本装好配套的cuda以及cuDNN,配置好系统环境变量,再安装好对应的tf.whl文件