VMware 安装Ubuntu1404虚拟机 + Hadoop2.6.1 安装
通过虚拟机来实施模拟集群环境,虽然说是虚机模拟,但是在虚机上的hadoop的集群搭建过程也可以使用在实际的物理节点中,思想是一样的。
安装hadoop的准备条件:
1,安装VMware WorkStation软件
2,在虚拟机上安装linux操作系统
3 ,准备三个虚拟机节点
其实这一步骤非常简单,如果你已经完成了第2步,此时你已经准备好了第一个虚拟节点,然后在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制,形成第二和第三个虚拟机节点。
很多人也许会问,这三个结点有什么用,原理很简单,按照hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop程序中的namenode、secondorynamenode和jobtracker任务。用外两个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了,所以模拟hadoop集群至少要有3个结点,如果电脑配置非常高,可以考虑增加一些其它的结点。slave结点主要将运行hadoop程序中的datanode和tasktracker任务。
所以,在准备好这3个结点之后,需要分别将linux系统的主机名重命名(因为前面是复制和粘帖操作产生另两上结点,此时这3个结点的主机名是一样的),重命名主机名的方法:
sudo gedit /etc/hostname通过修改hostname文件即可,这三个点结均要修改,以示区分。
以下是我对三个结点的ubuntu系统主机分别命名为:master, node1, node2
hadoop@master:~$
hadoop@node1:~$
hadoop@node2:~$4,安装JDK并配置环境变量
解压下载的JDK到 home 目录并配置环境变量如下:
export JAVA_HOME=/home/hadoop/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$JRE_HOME/bin:$PATH在master节点配置好后,通过scp命令,复制到node1和node2节点并修改相应的环境变量。(下面的远程复制命令要在master节点下执行)
scp -r jdk1.8.0_171 hadoop@node1:~/
scp -r jdk1.8.0_171 hadoop@node2:~/安装过程主要有以下几个步骤:
一、 配置hosts文件
二、 建立hadoop运行帐号
三、配置ssh免密码连入
四、下载并解压hadoop安装包
五、配置namenode,修改site文件
六、配置hadoop-env.sh文件
七、配置masters和slaves文件
八、向各节点复制hadoop
九、格式化namenode
十、启动hadoop
十一、用jps检验各后台进程是否成功启动
十二、通过网站查看集群情况
下面我们对以上过程,各个击破吧!~~
一、配置hosts文件
先简单说明下配置hosts文件的作用,它主要用于确定每个结点的IP地址,方便后续master结点能快速查到并访问各个结点。在上述3个虚机结点上均需要配置此文件。由于需要确定每个结点的IP地址,所以在配置hosts文件之前需要先查看当前虚机结点的IP地址是多少,可以通过ifconfig命令进行查看,如本实验中,master结点的IP地址为:
如果IP地址不对,可以通过ifconfig命令更改结点的物理IP地址,示例如下:![]()
通过上面命令可以将IP改为192.168.1.100。将每个结点的IP地址设置完成后,就可以配置hosts文件了,hosts文件路径为;/etc/hosts,我的hosts文件配置如下,大家可以参考自己的IP地址以及相应的主机名完成配置。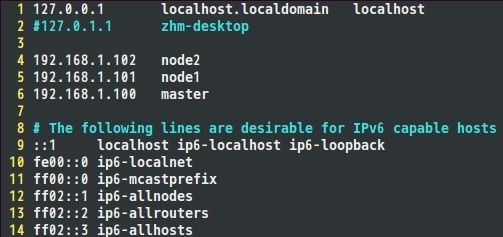
二、 建立hadoop运行帐号
即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:
sudo groupadd hadoop
//设置hadoop用户组
sudo useradd –s /bin/bash –d /home/zhm –m zhm –g hadoop –G admin
//添加一个zhm用户,此用户属于hadoop用户组,且具有admin权限。
sudo passwd zhm
//设置用户zhm登录密码
su zhm
//切换到zhm用户中上述3个虚机结点均需要进行以上步骤来完成hadoop运行帐号的建立。
另一种方法:
添加一个hadoop用户,并赋予相应权利,我们接下来hadoop hbase的安装都要在hadoop用户下操作,所以hadoop用户要将hadoop的文件权限以及文件所有者赋予给hadoop用户。
1.每个虚拟机系统上都添加 hadoop 用户,并添加到 sudoers
sudo adduser hadoop
sudo gedit /etc/sudoers找到对应添加如下:
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL2.切换到 hadoop 用户
su hadoop三、配置ssh免密码连入
这一环节最为重要,而且也最为关键,因为本人在这一步骤裁了不少跟头,走了不少弯路,如果这一步走成功了,后面环节进行的也会比较顺利。
SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数
据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据。总而言之,这是一种非对称算法,想要破解还是非常有难度的。Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
OK,废话就不说了,下面看看如何配置SSH免密码登录吧!
(1) 每个结点分别产生公私密钥。
键入命令:
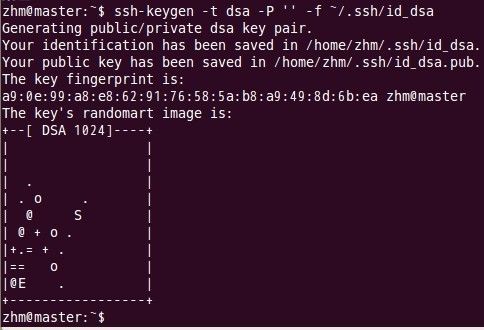
以上命令是产生公私密钥,产生目录在用户主目录下的.ssh目录中,如下:

Id_dsa.pub为公钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,过程如下:

用上述同样的方法在剩下的两个结点中如法炮制即可。
(2) 单机回环ssh免密码登录测试
即在单机结点上用ssh进行登录,看能否登录成功。登录成功后注销退出,过程如下:
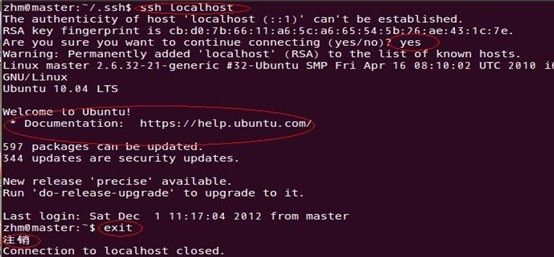
注意标红圈的指示,有以上信息表示操作成功,单点回环SSH登录及注销成功,这将为后续跨子结点SSH远程免密码登录作好准备。
用上述同样的方法在剩下的两个结点中如法炮制即可。
(3) 让主结点(master)能通过SSH免密码登录两个子结点(slave)
为了实现这个功能,两个slave结点的公钥文件中必须要包含主结点的公钥信息,这样
当master就可以顺利安全地访问这两个slave结点了。操作过程如下:

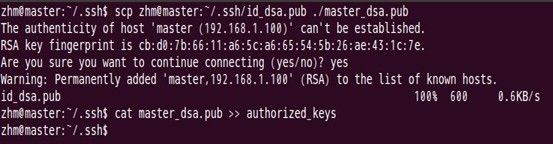
如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,这一过程需要密码验证。接着,将master结点的公钥文件追加至authorized_keys文件中,通过这步操作,如果不出问题,master结点就可以通过ssh远程免密码连接node1结点了。在master结点中操作如下:
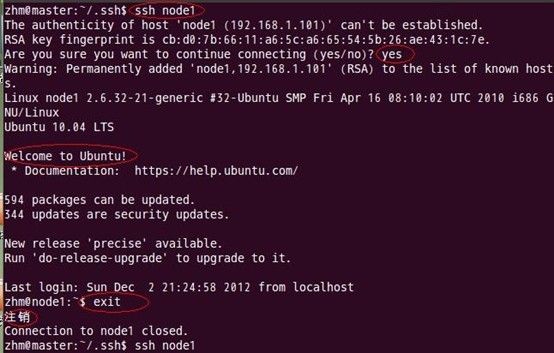
由上图可以看出,node1结点首次连接时需要,“YES”确认连接,这意味着master结点连接node1结点时需要人工询问,无法自动连接,输入yes后成功接入,紧接着注销退出至master结点。要实现ssh免密码连接至其它结点,还差一步,只需要再执行一遍ssh node1,如果没有要求你输入”yes”,就算成功了,过程如下:

如上图所示,master已经可以通过ssh免密码登录至node1结点了。对node2结点也可以用同样的方法进行,如下图:
Node2结点复制master结点中的公钥文件。

Master通过ssh免密码登录至node2结点测试:
第一次登录时:
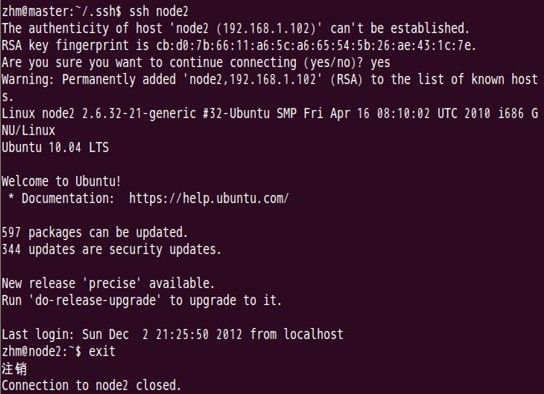
第二次登录时:
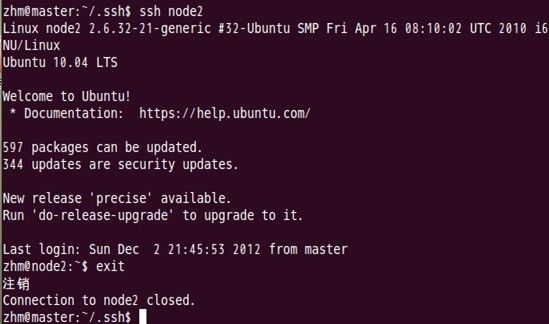
表面上看,这两个结点的ssh免密码登录已经配置成功,但是我们还需要对主结点master也要进行上面的同样工作,这一步有点让人困惑,但是这是有原因的,具体原因现在也说不太好,据说是真实物理结点时需要做这项工作,因为jobtracker有可能会分布在其它结点上,jobtracker有不存在master结点上的可能性。
对master自身进行ssh免密码登录测试工作:
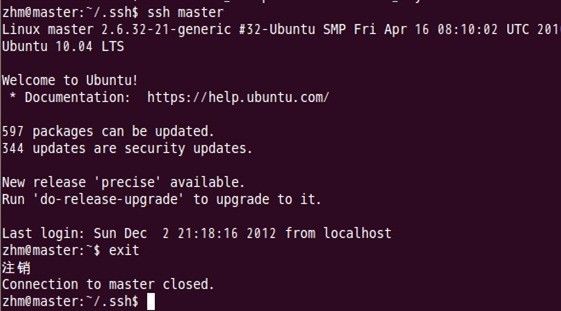
至此,SSH免密码登录已经配置成功。
四、安装并运行Hadoop
介绍Hadoop的安装之前,先介绍一下Hadoop对各个节点的角色定义。
Hadoop分别从三个角度将主机划分为两种角色。第一,最基本的划分为Master和Slave,即主人和奴隶;第二,从HDFS的角度,将主机划分为NameNode和DataNode(在分布式文件系统中,目录的管理很重要,管理目录相当于主任,而NameNode就是目录管理者);第三,从MapReduce角度,将主机划分为JobTracker和TaskTracker(一个Job经常被划分为多个Task,从这个角度不难理解它们之间的关系)。
Hadoop有三种运行方式:单机模式、伪分布与完全分布式。乍看之下,前两种并不能体现云计算的优势,但是它们便于程序的测试与调试,所以还是有意义的。
我的博客中有介绍单机模式和伪分布式方式这里就不赘述,本文主要着重介绍分布式方式配置。
(1)解压下载好的hadoop,放到home目录下
(2)配置 hadoop 的环境变量
sudo gedit /etc/profile配置如下:
export HADOOP_HOME=/home/hadoop/hadoop-2.6.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:/home/hadoop/hbase-1.2.4/bin:$PATH
(3)配置三台主机的Hadoop文件,内容如下。
#文件路径
/home/master/hadoop-2.6.1/etc/hadoop/Hadoop-env.sh
#配置如下
# The java implementation to use.
export JAVA_HOME=/home/hadoop/jdk1.8.0_171
export HADOOP_HOME=/home/hadoop/hadoop-2.6.1
export PATH=$PATH:/home/hadoop/hadoop-2.6.1/bin#文件路径
/home/hadoop/hadoop-2.6.1/etc/hadoop/core-site.xml
#配置如下
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/tmpvalue>
property>
configuration>
#文件路径
/home/hadoop/hadoop-2.6.1/etc/hadoop/hdfs-site.xml
#配置如下
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
configuration>#文件路径
/home/master/hadoop-2.7.1/etc/hadoop/mapred-site.xml
#配置如下
<configuration>
<property>
<name>mapred.job.trackername>
<value>master:9001value>
property>
configuration>#文件路径
/home/hadoop/hadoop-2.6.1/etc/hadoop/masters
#没有手动添加一个master文件
#配置如下
master#文件路径
/home/master/hadoop-2.7.1/etc/hadoop/slaves
#配置如下
node1
node2
(4)向 node1 和 node2 节点复制 hadoop2.6.1 整个目录至相同的位置
下面的命令要在hadoop@master节点hadoop目录下使用
scp -r hadoop-2.6.1 hadoop@node1:~/
scp -r hadoop-2.6.1 hadoop@node2:~/(5)启动Hadoop
在hadoop@master节点上执行下列命令
hadoop@master:~$ hadoop namenode -format如果提示:hadoop: command not found
需要source一下环境变量文件:source /etc/profile
执行结果如下:
hadoop@master:~$ hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
17/02/02 02:59:44 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.190.128
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.1
STARTUP_MSG: classpath = /home/hadoop/hadoop-2.7.1/etc/hadoop:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jsr305-3.0.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/hadoop-auth-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/avro-1.7.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jsch-0.1.42.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/gson-2.2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/curator-client-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/hadoop-annotations-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/curator-framework-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/commons-collections-3.2.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/zookeeper-3.4.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/lib/junit-4.11.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-nfs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/hadoop-hdfs-2.7.1-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/hdfs/hadoop-hdfs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/javax.inject-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/commons-collections-3.2.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-api-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-registry-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-client-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/yarn/hadoop-yarn-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/junit-4.11.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.1-tests.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.1.jar:/home/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.1.jar:/home/master/hadoop-2.7.1/contrib/capacity-scheduler/*.jar:/home/master/hadoop-2.7.1/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a; compiled by 'jenkins' on 2015-06-29T06:04Z
STARTUP_MSG: java = 1.7.0_76
************************************************************/
17/02/02 02:59:44 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
17/02/02 02:59:44 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-ef219bd8-5622-49d9-b501-6370f3b5fc73
17/02/02 03:00:03 INFO namenode.FSNamesystem: No KeyProvider found.
17/02/02 03:00:03 INFO namenode.FSNamesystem: fsLock is fair:true
17/02/02 03:00:04 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
17/02/02 03:00:04 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
17/02/02 03:00:04 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
17/02/02 03:00:04 INFO blockmanagement.BlockManager: The block deletion will start around 2017 Feb 02 03:00:04
17/02/02 03:00:04 INFO util.GSet: Computing capacity for map BlocksMap
17/02/02 03:00:04 INFO util.GSet: VM type = 64-bit
17/02/02 03:00:04 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
17/02/02 03:00:04 INFO util.GSet: capacity = 2^21 = 2097152 entries
17/02/02 03:00:04 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
17/02/02 03:00:04 INFO blockmanagement.BlockManager: defaultReplication = 2
17/02/02 03:00:04 INFO blockmanagement.BlockManager: maxReplication = 512
17/02/02 03:00:04 INFO blockmanagement.BlockManager: minReplication = 1
17/02/02 03:00:04 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
17/02/02 03:00:04 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
17/02/02 03:00:04 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
17/02/02 03:00:04 INFO blockmanagement.BlockManager: encryptDataTransfer = false
17/02/02 03:00:04 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
17/02/02 03:00:04 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
17/02/02 03:00:04 INFO namenode.FSNamesystem: supergroup = supergroup
17/02/02 03:00:04 INFO namenode.FSNamesystem: isPermissionEnabled = true
17/02/02 03:00:04 INFO namenode.FSNamesystem: HA Enabled: false
17/02/02 03:00:04 INFO namenode.FSNamesystem: Append Enabled: true
17/02/02 03:00:05 INFO util.GSet: Computing capacity for map INodeMap
17/02/02 03:00:05 INFO util.GSet: VM type = 64-bit
17/02/02 03:00:05 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
17/02/02 03:00:05 INFO util.GSet: capacity = 2^20 = 1048576 entries
17/02/02 03:00:05 INFO namenode.FSDirectory: ACLs enabled? false
17/02/02 03:00:05 INFO namenode.FSDirectory: XAttrs enabled? true
17/02/02 03:00:05 INFO namenode.FSDirectory: Maximum size of an xattr: 16384
17/02/02 03:00:05 INFO namenode.NameNode: Caching file names occuring more than 10 times
17/02/02 03:00:05 INFO util.GSet: Computing capacity for map cachedBlocks
17/02/02 03:00:05 INFO util.GSet: VM type = 64-bit
17/02/02 03:00:05 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
17/02/02 03:00:05 INFO util.GSet: capacity = 2^18 = 262144 entries
17/02/02 03:00:05 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
17/02/02 03:00:05 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
17/02/02 03:00:05 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
17/02/02 03:00:05 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
17/02/02 03:00:05 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
17/02/02 03:00:05 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
17/02/02 03:00:05 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
17/02/02 03:00:05 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
17/02/02 03:00:06 INFO util.GSet: Computing capacity for map NameNodeRetryCache
17/02/02 03:00:06 INFO util.GSet: VM type = 64-bit
17/02/02 03:00:06 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
17/02/02 03:00:06 INFO util.GSet: capacity = 2^15 = 32768 entries
Re-format filesystem in Storage Directory /tmp/dfs/name ? (Y or N) y
17/02/02 03:00:28 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1867851271-192.168.190.128-1485975628037
17/02/02 03:00:28 INFO common.Storage: Storage directory /tmp/dfs/name has been successfully formatted.
17/02/02 03:00:29 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/02/02 03:00:29 INFO util.ExitUtil: Exiting with status 0
17/02/02 03:00:29 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.190.128
************************************************************/说明初始格式化文件系统成功!
启动Hadoop
注意启动Hadoop是在主节点上执行命令,其他节点不需要,主节点会自动按照文件配置启动从节点
hadoop@master:~$ start-all.sh执行结果如下:
hadoop@master:~$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-namenode-master.out
slave1: starting datanode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-datanode-slave1.out
slave2: starting datanode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-datanode-slave2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.1/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-resourcemanager-master.out
slave1: starting nodemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-nodemanager-slave1.out
slave2: starting nodemanager, logging to /home/hadoop/hadoop-2.7.1/logs/yarn-hadoop-nodemanager-slave2.out可以通过jps命令查看各个节点运行的进程查看运行是否成功。
master节点:
hadoop@master:~$ jps
11012 Jps
10748 ResourceManager
10594 SecondaryNameNodenode1节点:
hadoop@slave1:~$ jps
7227 Jps
7100 NodeManager
6977 DataNodenode2节点:
hadoop@slave2:~$ jps
6654 Jps
6496 NodeManager
6373 DataNode你可以通过以下命令或者通过http://master:50070查看集群状态。
Hadoop dfsadmin -report至此Haoop的安装配置已经全部讲完。
参考链接:
1,https://blog.csdn.net/wuruiaoxue/article/details/54833621
2,https://www.cnblogs.com/student-programmer/p/6782580.html
3,https://blog.csdn.net/xiao_bai_9527/article/details/79167562
4,https://blog.csdn.net/sdksdk0/article/details/51498775
5,https://www.cnblogs.com/fishbay/archive/2017/07/24/7229502.html