左 . 算法---哈希函数/哈希表/布隆过滤器/一致性哈希算法 专题
哈希函数:
常见的功能就是 打乱分布 均匀随机 输入无穷大 输出却在一定范围内
即使出现碰撞 但是每个输出对应的输入个数 概率均匀分布 没有太大偏向
一个重要的性质: 如果在input域上均匀分布 那么经过哈希并%m 运算后(在0~m-1范围内) 在输出域上同样均匀分布

哈希表:
经典结构:
根据key算出具体的hashcode值(h)----决定了value的存放位置
若 h 位置处为空 则直接将key1-value1 放入
若h位置处不为空 检查是否已有key1 若已有 则更新其对应value值 否则 直接按照链表格式,节点连在上一节点后面

经典应用:
场景题: 如果现在有一个超级大的文件,需要统计其中重复的字符串 ,我们要怎么办?
目前已知的: 可以供给1000台计算机 读取细节不用关心 只需要设计大概系统
思路 :哈希的分流特性
具体操作: 将大文件读取很多行 每一行都计算哈希值 并模1000 则这些字符串均匀分布在0-999范围内
给电脑编号0-999 对应分布在一个范围内的一些字符串用同一台电脑进行处理 达到大数据分流的效果(类似于分布式)
每台电脑只统计自己处理的重复字符串 最后将结果进行汇总即可

总结:
大数据相关的问题 有一半都是借助于哈希来解决 因为哈希具有“相同的肯定相同 不同的均匀分布”特性
在桶不够用时可以进行扩容 代价也还可以接受 一般是O(lognN)
设计一个RandomPool结构:

思路:
因为 getRandom()函数要求等概率随机返回结构中的任意一个key
所以 一张哈希表在小样本情况下无法做到随机 需要至少两张哈希表
举例:
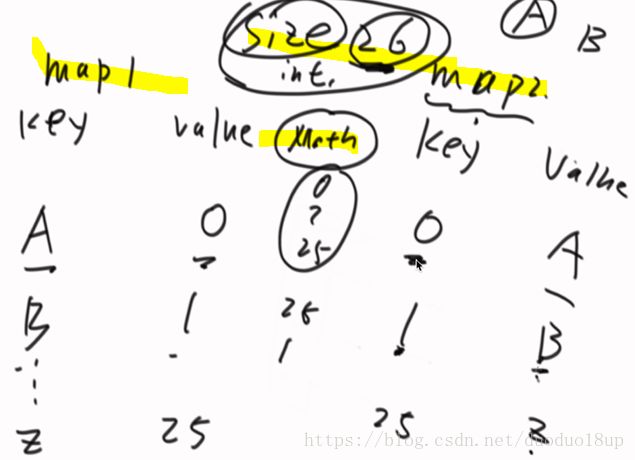
现在有26个字符串
分别按照顺序放入两个表中 两个表的key value 是对应的
用size统计此时表中数据个数 最后getRandom()时候直接 Math.random()*26 来获取map2中对应key的value
部分代码:

解决难点: 删除过程中会在原有随机结构中出现好多洞 导致随机性变差 如何解决此问题?
思路:

z最终的总代码:


布隆过滤器:
初识布隆过滤器:
举例: 假如有一个100亿 的url的黑名单,希望用户在搜索这些url时,会将 在黑名单中的url 过滤出去,不进行显示。
每个url都是64字节。 应该如何实现这个操作?
最直观的想法: 就是查找用户搜索的url 是否在黑名单中,根据具体情况返回布尔值 true or false.

思路1 :
考虑直接用哈希表 进行存储。 不用存value,直接存key ,则至少需要内存为 6400亿字节的hashset 数据结构(即640G)
这个内存很大,实际中我们可能需要多台电脑来操作(分布式)。
或利用哈希函数进行分流 但仍然很麻烦。
思路2 :
布隆过滤器(某种类型的集合,但是存在失误率)
存在的唯一失误率: 如果确实在黑名单里的url肯定能够正确判断 但可能出现: 不在黑名单中的url但是它返回true 的情况~
一般这种类型的题目:
最好先说 哈希表的经典解法 ------多台电脑分流之类的
改进: 因为经典方法耗费内存太大----那询问是否允许较低的失误率----允许的话则可以采用布隆过滤器
布隆过滤器的细节:
结构:其实是一个bit数组 数组中存的是bit(0/1)

举例:

新建int数组 但其实相当于32000长度的bit数组
想要将第30000bit位上的数组描黑 -----则先确定在哪个大桶内-----再确定在那个桶中的哪个位上---原来数字和第bitIndex bit位上为1 的数字进行位或-----即得结果
实现:
拿基础类型即可实现

要想再大 可以拿矩阵来表示 直接如上1000*1000*64bit
黑名单问题的解决:



1 先准备一个长度为m bit 的数组 (范围为0--m-1)
2 布隆过滤器 预先准备多个hash函数 (hash1 ---hash2---hash3....hashk)
3 将黑名单中的url1(假设为第一条url) 分别经过上述k 个hash函数 计算出对应的k个 哈希值 ---并在数组中对应位置上描黑
4 将黑名单中所有的url都进行第3步操作 记录完毕
如何判断用户搜索的url是否在黑名单中?
同样将url经过第3步操作去看计算出的k个值对应的位置上是否都被描黑 若有一个不符合 则不是黑名单中的 否则 就在黑名单中


相关的参数大小:



如何解决误判问题:

相关问题:
![]()

一致性哈希:

一般应用在服务器集群上 用以实现数据缓存
应用场景举例:
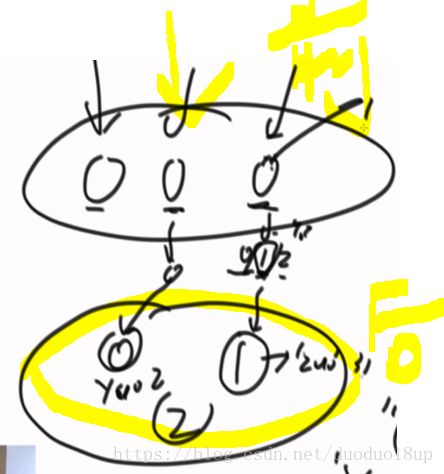
前端收到大量用户请求 ,该如何让后台的服务器进行储存和处理呢?
使用哈希---计算出对应哪个服务器处理----查询时---计算哈希---去找对应的服务器去查找
具体原理:

可能出现的问题及解决方法:

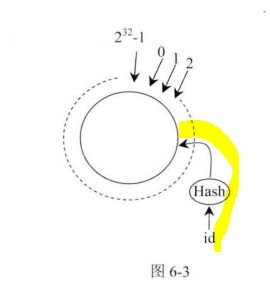
具体确定归属的细节:


增加机器时候的处理方法:



机器负载不均时的处理(虚拟节点机制):



一致性哈希常用于负载均衡 分布式 服务器~~
并查集:
并查集中集合的初始化过程:

并查集的代表节点
在并查集中查一个节点属于哪个集合?

如何路径压缩?

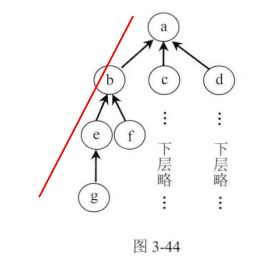

集合如何合并?


代码:
1 .初始化并查集:

2 .查找某个节点所在集合的代表节点:
 非递归版本代码
非递归版本代码 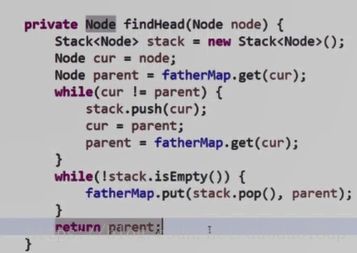
3 .集合的合并

用途:


岛问题:

正常方法(递归法):
设置一个感染函数G 假设遇到一片1(可能上下左右均有) 则均感染为2 并计数+1 继续前进


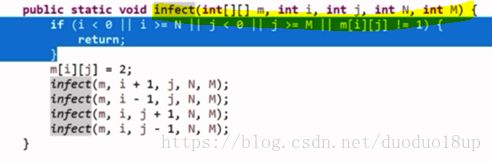
总结:此方法类似于DFS,就是深度搜索 没有什么新意
而且矩阵一旦特别大则不实用 仅适合单cpu运行
如何能够多cpu并行运行,提高速度和效率呢?
并查集方法:
考虑分别的岛个数 和 边界处可能 合并的岛个数:
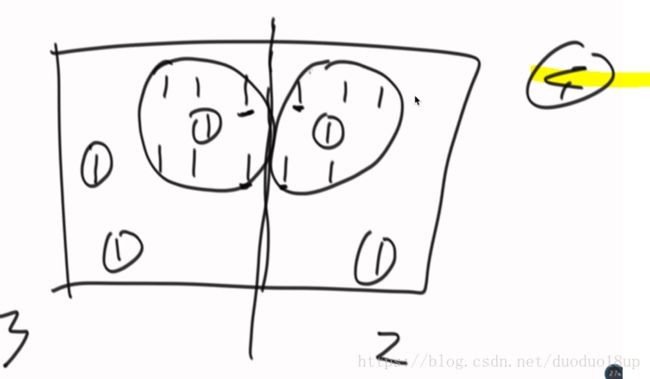
大概原理: 分别统计各自部分的岛个数----在边界处标明是受哪个元素“感染”的,然后检查集合并合并 ,总数-1

此处用并查集的优势: 涉及到大量集合合并 判断是否是一个集合的运算
总结:
用多个cpu 分成多个部分 最终就只要每一个负责统计自己部分 的岛个数 并记录四周的边界情况即可
