Logstash 6.x讲解及使用(配合FileBeats, Redis等)
概念:
Logstash是一个开源的数据收集引擎,它具备实时数据传输能力。可以实现数据传输、格式处理、格式化输出,同时有强大的插件功能,常用于日志处理。
安装:
1、前提:安装jdk8,此处略
2、从官网下载Logstash tar包:
https://www.elastic.co/downloads/logstash
3、解压到指定目录
tar -zxvf logstash-6.5.3.tar.gz
4、其实这样就已经安装好,简单吧。。。。
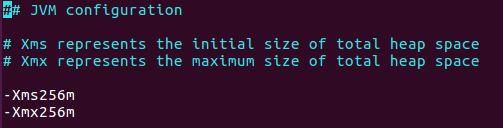
注意:如果是在自己测试机器上,内存比较小,可以修改logstash config/jvm.options文件,修改Xms, Xmx,如下:
验证安装:
在终端输入:
./bin/logstash -e 'input { stdin {} } output { stdout { }}'等logstash启动后(出现Successfully started Logstash API endpoint {:port=>9600}说明启动成功)
输入:Hello World
这时会输出:
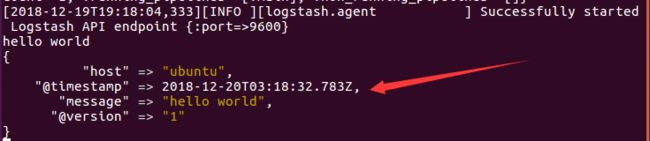
说明安装成功
工作流程:
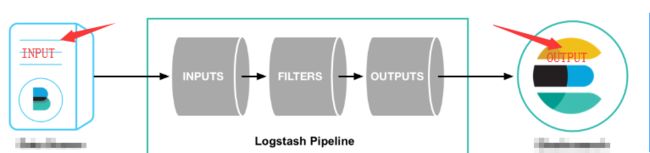
这是截的官网的图,修改了下,其中标注部分的Input跟Output可以有多种来源,多种输出,具体如下:
Logstash工作的三个阶段:
Inputs 数据输入端:
1、file:从文件中读取
2、syslog:监听在514端口的系统日志信息,并解析成RFC3164格式
3、redis:从redis-server list中获取
4、beat:接收来自Filebeat的事件
Filter 数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等,常用的过滤器如下:
1、grok:通过正则解析和结构化任何文件。Grok目前是logstash最好的方式对非结构化日志数据解析成结构化和可查询化。logstash内置了120个匹配模式,满足大部分需求
2、mutate:在事件字段执行一般的转换。可以重命名、删除、替换和修改事件字段
3、drop:完全丢弃事件,如debug事件
4、clone:复制事件,可能添加或者删除字段
5、geoip:添加有关IP地址地理位置信息
Output 是Logstash工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用,常用的有:
1、elasticsearch:发送事件数据到ElasticSearch,便于查询、分析、绘图
2、file:将事件数据写入到磁盘文件上
3、mongodb:将事件数据发送至高性能NoSQL mongodb,便于永久存储、查询、分析、大数据分片
4、redis:将数据发送至redis-server
5、statsd:发送事件数据到statsd
6、graphite:发送事件数据到graphite
启动方式:
1、通过手动指定配置文件启动
./bin/logstash -f ./test.conf
2、以dameon方式运行,只需要在后面加&
./bin/logstash -f ./test.conf &
3、以命令行方式(刚才验证是否安装成功)
./bin/logstash -e 'input {stdin{}} output {stdout{}}'
配置文件语法讲解:
logstash使用{}来定义配置区域,区域内又可以包含其插件的区域配置:
#logstash包括三部分:input、filter、output
#input、output为必须包括,filter可选
input{
stdin{}
}
output{
stdout{}
}
#如果需要对数据进行操作,则需要加上filter段
input{
stdin{}
}
filter{
#里面可以包含各种数据处理的插件,如文本格式处理grok、键值定义kv、字段添加、geoip获取地理位置信
#息等等
}
output{
stdout{}
}
# 可以定义多个输入源与多个输出位置
input{
stdin{}
file{
path => ["/var/log/message"]
type => "system"
}
}
output{
stdout{}
file{
path => "/var/data/mysystem.log.gz"
gzip => true
}
}
配置文件中的grok:
比如需要对apache中日志进行格式化,可以做如下配置:
(这里使用Kibana中的grok debugger。Kibana也就是ELK中的K)
比如数据为:
2018-08-08 00:18:13,061 ERROR [org.vancebox.exception.ExceptionResolver] -
at org.apache.tomcat.util.buf.ByteChunk.flushBuffer(ByteChunk.java:462)
at org.apache.tomcat.util.buf.ByteChunk.append(ByteChunk.java:366)
at org.apache.catalina.connector.OutputBuffer.writeBytes(OutputBuffer.java:413)
... 43 more
>
grok语句为:
%{TIMESTAMP_ISO8601:access_time} %{LOGLEVEL:loglevel} \[%{DATA:exception_info}\] - \<%{MESSAGE:message}\>
#其中Message为自定义语句
MESSAGE [\s\S]*格式化后输出数据为:
{
"exception_info": "org.vancebox.exception.ExceptionResolver",
"loglevel": "ERROR",
"message": "ClientAbortException: java.net.SocketException: Broken pipe\r\n\tat org.apache.catalina.connector.OutputBuffer.========>太长略了",
"access_time": "2018-08-08 00:18:13,061"
}
FileBeat基础介绍使用:
fileBeat可以用来收集日志,跟logstash功能类似,但是运行更轻量,无需java环境 也省内存。除了fileBeat还有其他beats,比如winlogBeats等。
官网:https://www.elastic.co/downloads/beats
下载后解压即可
安装完以后需要做下配置,配置文件是filebeat.yml
比如我需要采集d盘log目录下的所有日志文件数据,并且输出到es中,可做如下配置:
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- D:\logtemp\*
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
hosts: ["192.168.61.196:9200"]inputs是采集,output是输出
一般做法是 filebeat采集到数据,发往redis,然后logstash从redis中取数据 做过滤,过滤完以后发送到elasticSearch
fileBeats中的redis配置如下:
#-------------------------- Redis output --------------------------
output.redis:
hosts: ["192.168.61.200"]
port: 6379
password: "123456"
key: "fb-test"logstash中redis的input配置如下:
input {
redis {
host => "192.168.61.200"
port => 6379
password => "123456"
data_type => "list" #数据类型,支持string和list
key => "fb-test" #key名称
db => 0 #指定redis库编号
}
}
filter {
}
output {
elasticsearch {
action => "index"
hosts => "192.168.61.196:9200"
index => "etest04"
}
stdout {}
}