深入学习Gremlin(3):has条件过滤
第3期 Gremlin Steps:
hasLabel(labels…)、hasId(ids…)、has(key, value)、has(label, key, value)、has(key, predicate)、hasKey(keys…)、hasValue(values…)、has(key)、hasNot(key)
本系列文章的Gremlin示例均在HugeGraph图数据库上执行,环境搭建可参考准备Gremlin执行环境,本文示例均以其中的“TinkerPop关系图”为初始数据。
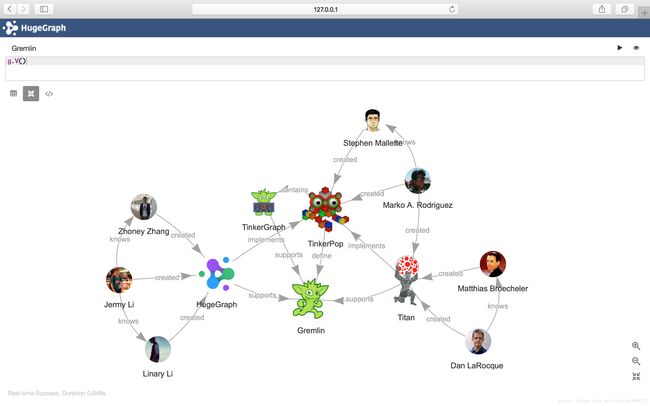
上一期:深入学习Gremlin(2):边的遍历操作
Has Step说明
在众多Gremlin的语句中,有一大类是filter类型,顾名思义,就是对输入的对象进行条件判断,只有满足过滤条件的对象才可以通过filter进入下一步。
has语句是filter类型语句的代表,能够以顶点和边的属性作为过滤条件,决定哪些对象可以通过。has语句包括很多变种:
hasLabel(labels…): 满足一个label就可以通过hasId(ids…): 满足一个ID就可以通过has(key, value): 有“key=value”property的通过has(label, key, value): 有“key=value”且label的通过has(key, predicate): 有key且对应的value满足predicatehasKey(keys…): properties包含所有的key才能通过hasValue(values…): properties包含所有的value才能通过has(key): 有这个属性的通过hasNot(key): 没有这个属性的通过has(key, traversal): Remove the traverser if its object does not yield a result through the traversal off the property value
TinkerPop规范中,也可以对Vertex Property进行has()操作,前提是图支持meta-property。HugeGraph不支持meta-property,因此本文不会有Vertex Property相关的has()示例。
实例讲解
在HugeGraph中,按property的值查询之前,应该对property建立索引,否则将无法查到结果并引发异常。(有两个例外,Vertex的PrimaryKeys和Edge的SortKeys,具体参见HugeGraph官网)
// 对‘person’的‘addr’属性建立secondary索引,可以对Text类型property按值进行查询
graph.schema().indexLabel('personByCity').onV('person').by('addr').secondary().ifNotExist().create()
// 对‘person’的‘age’属性建立range索引,可以对Number类型property进行范围查询
graph.schema().indexLabel('personByAge').onV('person').by('age').range().ifNotExist().create()
- 1
- 2
- 3
- 4
1. hasLabel(label...),通过label来过滤顶点或边,满足label列表中一个即可通过
// 查询label为"person"的顶点
g.V().hasLabel('person')
- 1
- 2
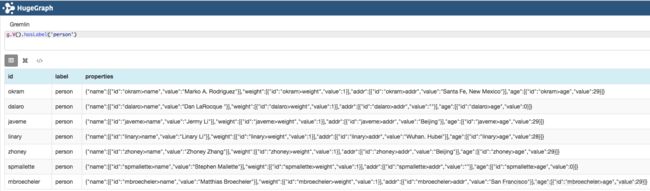
// 查询label为"person"或者"software"的顶点
g.V().hasLabel('person', 'software')
- 1
- 2
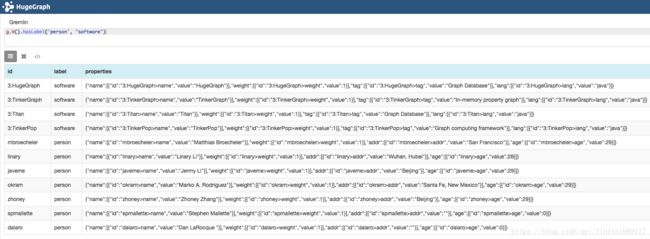
2. hasId(ids…),通过id来过滤顶点或者边,满足id列表中的一个即可通过
// 查询id为"zhoney"的顶点
g.V().hasId('zhoney')
- 1
- 2

// 查询id为“zhoney”或者“3:HugeGraph”的顶点
g.V().hasId('zhoney', '3:HugeGraph')
- 1
- 2

3. has(key, value),通过属性的名字和值来过滤顶点或边
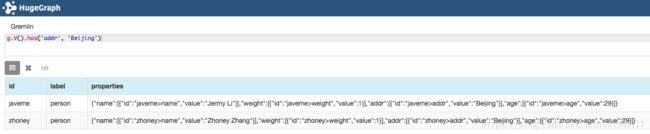
// 查询“addr”属性值为“Beijing”的顶点
g.V().has('addr', 'Beijing')
- 1
- 2
4. has(label, key, value),通过label和属性的名字和值过滤顶点和边
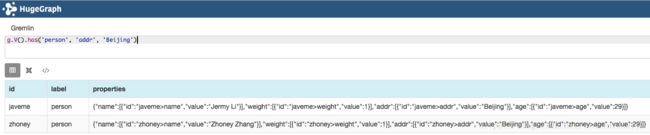
// 查询label为“person”且“addr”属性值为“Beijing”的顶点
g.V().has('person', 'addr', 'Beijing')
- 1
- 2
5. has(key, predicate),通过对指定属性用条件过滤顶点和边
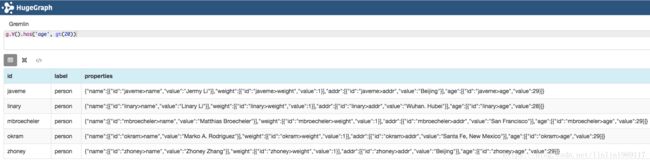
// 查询“addr”属性值为“Beijing”的顶点
g.V().has('age', gt(20))
- 1
- 2
6. hasKey(keys…): properties包含所有的key才能通过
// 查询包含属性“age”的顶点
g.V().hasKey('age')
- 1
- 2

HugeGraph目前不支持hasKey()传递多个key
7. hasValue(values…): properties包含所有的value才能通过
// 查询包含属性值“Beijing”的顶点
g.V().hasValue('Beijing')
- 1
- 2

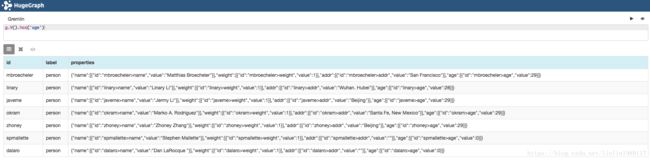
8. has(key): 有这个属性的通过,等价于hasKey(key)
// 查询包含属性“age”的顶点
g.V().has('age')
- 1
- 2
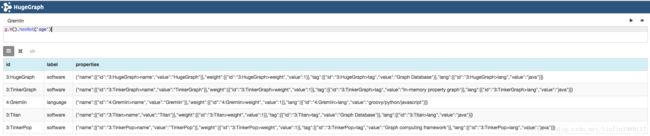
9. hasNot(key): 没有这个属性的通过
// 查询没有属性“age”的顶点
g.V().hasNot('age')
- 1
- 2
由于has()语句对Vertex和Edge的用法一样,本文仅给出了Vertex的示例。Edge的大家可以自行尝试。
下一篇:深入学习Gremlin(4):图查询返回结果数限制