《c++并发编程实战解析》 无锁数据结构 doubly-buffered-data
多线程环境设计数据结构相比单线程,需要额外注意的是利用多线程提升并发度同时保持数据结构不变性,即满足如下两个原则:
1、正确性,保证多线程并发访问没有 data race
2、性能,保护最小的数据,提供最大的性能
《c++并发编程实战》提供了一种【无锁数据结构】,注意这里无锁的含义不是真正无锁,而是利用数据结构特性保证运行时并发抢锁的线程数量最小,达到一种常态下访问数据结构不被锁阻塞的状态
使用场景:
1、读远多于写
2、数据小,一般最大为几K字节的元数据
3、数据可以应用到一致性状态机,即byte级别判断为相等的两份数据,执行同种操作后仍保持一致
和传统读写锁的区别和优势:single unix的读写锁要求有线程在获取写锁阻塞时,后续读锁阻塞,从而防止写锁被饿死,这样造成了一个后果,若有写请求到来,则写操作完成前,无法处理新的读请求,从而造成系统【颠簸】,在有写请求的时候对外表现为性能下降,读延迟增加。DoublyBufferData将数据保存两份,分成前端和后端,读请求读前端,写请求到来写后端,用c++11 memory_order语义保证写请求完成后新的读请求可以立刻读取最新的结果同时无data race,是一种典型的【空间换时间】模式
数据结构图示:
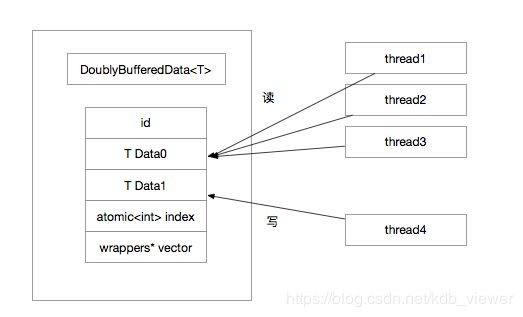
原理描述:
1、DoublyBufferedData中包含foreground和background两份数据,index值为0或1,指示读请求应该访问的数据,如index为0表示此时应该读取data0,data0是只读的,因此多线程访问不需要并发保护,这里是无锁的
2、当有线程请求修改,首先根据 !index 获取background并做修改,background没有读者,因此这里可以放心修改,修改完成后,data0是旧数据,data1是新数据,使用memory_order_release语义修改index = !index,这样后续使用memory_order_acquire语义访问index的线程可以看到修改(inter-thread的sychronization-with关系)
3、对于此前正在访问data0的线程,通过遍历wrappers可以得到这些线程各自对应的wrapper,进而等待所有这些线程访问结束
4、到这里,所有之前读data0的请求都结束了,所有后续的读请求都请求到data1,此时可以放心的修改data0,从而完成一次修改操作
代码:
1、DoublyBufferedDataWrapperBase:
提供线程私有存储的ABC类,T是数据类型,TLS用于线程私有存储,可用于保存上下文,没有特殊要求不需要使用TLS
template
class DoublyBufferedDataWrapperBase {
public:
TLS& user_tls() { return _user_tls; }
protected:
TLS _user_tls;
}; 2、Wrapper:
每个线程使用一个wrapper对数据进行访问,包含一个pthread_mutex_t,因为读没有并发,因此这个锁是没有竞争的,近似于无锁访问
template
class DoublyBufferedData::Wrapper
: public DoublyBufferedDataWrapperBase {
friend class DoublyBufferedData;
public:
explicit Wrapper() : _control(NULL) {
pthread_mutex_init(&_mutex, NULL);
}
~Wrapper() {
if (_control != NULL) {
_control->RemoveWrapper(this);
}
pthread_mutex_destroy(&_mutex);
}
inline void BeginRead() {
pthread_mutex_lock(&_mutex);
}
inline void EndRead() {
pthread_mutex_unlock(&_mutex);
}
inline void WaitReadDone() {
LOCK_GUARD(mutex);
}
private:
DoublyBufferedData* _control;
pthread_mutex_t _mutex;
}; 3、WrapperTLSGroup
全局管理器,每个希望使用DoublyBufferedData的数据向这个类申请一个全局唯一id,访问此数据的thread根据这个id申请自己的wrapper,每个线程内的wrapper用block组织,一个block大小4k字节,超过4k的数据独占block,否则一个block内分配多个wrapper
template
class DoublyBufferedData::WrapperTLSGroup {
public:
const static size_t RAW_BLOCK_SIZE = 4096;
const static size_t ELEMENTS_PER_BLOCK = (RAW_BLOCK_SIZE + sizeof(T) - 1) / sizeof(T);
struct __declspec(align(64)) ThreadBlock {
inline DoublyBufferedData::Wrapper* at(size_t offset) {
return _data + offset;
};
private:
DoublyBufferedData::Wrapper _data[ELEMENTS_PER_BLOCK];
};
inline static WrapperTLSId key_create() {
LOCK_GUARD(_s_mutex);
WrapperTLSId id = 0;
if (!_get_free_ids().empty()) {
id = _get_free_ids().back();
_get_free_ids().pop_back();
} else {
id = _s_id++;
}
return id;
}
inline static int key_delete(WrapperTLSId id) {
LOCK_GUARD(_s_mutex);
if (id < 0 || id >= _s_id) {
errno = EINVAL;
return -1;
}
_get_free_ids().push_back(id);
return 0;
}
inline static DoublyBufferedData::Wrapper* get_or_create_tls_data(WrapperTLSId id) {
if (unlikely(id < 0)) {
CHECK(false) << "Invalid id=" << id;
return NULL;
}
if (_s_tls_blocks == NULL) {
_s_tls_blocks = new (std::nothrow) std::vector;
if (BAIDU_UNLIKELY(_s_tls_blocks == NULL)) {
LOG(FATAL) << "Fail to create vector, " << berror();
return NULL;
}
thread_atexit(_destroy_tls_blocks);
}
const size_t block_id = (size_t)id / ELEMENTS_PER_BLOCK;
if (block_id >= _s_tls_blocks->size()) {
_s_tls_blocks->resize(std::max(block_id + 1, 32ul));
}
ThreadBlock* tb = (*_s_tls_blocks)[block_id];
if (tb == NULL) {
ThreadBlock* new_block = new (std::nothrow) ThreadBlock;
if (BAIDU_UNLIKELY(new_block == NULL)) {
return NULL;
}
tb = new_block;
(*_s_tls_blocks)[block_id] = new_block;
}
return tb->at(id - block_id * ELEMENTS_PER_BLOCK);
}
private:
static void _destroy_tls_blocks() {
if (!_s_tls_blocks) {
return;
}
for (size_t i = 0; i < _s_tls_blocks->size(); ++i) {
delete (*_s_tls_blocks)[i];
}
delete _s_tls_blocks;
_s_tls_blocks = NULL;
}
inline static std::deque& _get_free_ids() {
if (unlikely(!_s_free_ids)) {
_s_free_ids = new (std::nothrow) std::deque();
if (!_s_free_ids) {
abort();
}
}
return *_s_free_ids;
}
private:
static pthread_mutex_t _s_mutex;
static WrapperTLSId _s_id;
static std::deque* _s_free_ids;
static __thread std::vector* _s_tls_blocks;
}; 4、ScopedPtr:
提供给调用者使用的数据结构,调用者通过此类进行数据访问,内部封装并发逻辑
class ScopedPtr {
friend class DoublyBufferedData;
public:
ScopedPtr() : _data(NULL), _w(NULL) {}
~ScopedPtr() {
if (_w) {
_w->EndRead();
}
}
const T* get() const { return _data; }
const T& operator*() const { return *_data; }
const T* operator->() const { return _data; }
TLS& tls() { return _w->user_tls(); }
private:
ScopedPtr(const ScopedPtr&) = delete;
ScopedPtr& operator=(const ScopedPtr&) = delete;
const T* _data;
Wrapper* _w;
};5、DoublyBufferData:
数据存储单元,内部包含T[0]和T[1]两份数据,调用用户函数进行数据修改
template
class DoublyBufferedData {
class Wrapper;
class WrapperTLSGroup;
typedef int WrapperTLSId;
public:
DoublyBufferedData();
~DoublyBufferedData();
int Read(ScopedPtr* ptr);
template size_t Modify(Fn& fn);
template size_t Modify(Fn& fn, const Arg1&);
template
size_t Modify(Fn& fn, const Arg1&, const Arg2&);
template size_t ModifyWithForeground(Fn& fn);
template
size_t ModifyWithForeground(Fn& fn, const Arg1&);
template
size_t ModifyWithForeground(Fn& fn, const Arg1&, const Arg2&);
private:
template
struct WithFG0 {
WithFG0(Fn& fn, T* data) : _fn(fn), _data(data) { }
size_t operator()(T& bg) {
return _fn(bg, (const T&)_data[&bg == _data]);
}
private:
Fn& _fn;
T* _data;
};
template
struct WithFG1 {
WithFG1(Fn& fn, T* data, const Arg1& arg1)
: _fn(fn), _data(data), _arg1(arg1) {}
size_t operator()(T& bg) {
return _fn(bg, (const T&)_data[&bg == _data], _arg1);
}
private:
Fn& _fn;
T* _data;
const Arg1& _arg1;
};
template
struct WithFG2 {
WithFG2(Fn& fn, T* data, const Arg1& arg1, const Arg2& arg2)
: _fn(fn), _data(data), _arg1(arg1), _arg2(arg2) {}
size_t operator()(T& bg) {
return _fn(bg, (const T&)_data[&bg == _data], _arg1, _arg2);
}
private:
Fn& _fn;
T* _data;
const Arg1& _arg1;
const Arg2& _arg2;
};
template
struct Closure1 {
Closure1(Fn& fn, const Arg1& arg1) : _fn(fn), _arg1(arg1) {}
size_t operator()(T& bg) { return _fn(bg, _arg1); }
private:
Fn& _fn;
const Arg1& _arg1;
};
template
struct Closure2 {
Closure2(Fn& fn, const Arg1& arg1, const Arg2& arg2)
: _fn(fn), _arg1(arg1), _arg2(arg2) {}
size_t operator()(T& bg) { return _fn(bg, _arg1, _arg2); }
private:
Fn& _fn;
const Arg1& _arg1;
const Arg2& _arg2;
};
const T* UnsafeRead() const
{ return _data + _index.load(base::memory_order_acquire); }
Wrapper* AddWrapper(Wrapper*);
void RemoveWrapper(Wrapper*);
T _data[2];
base::atomic _index;
WrapperTLSId _wrapper_key;
std::vector _wrappers;
pthread_mutex_t _wrappers_mutex;
pthread_mutex_t _modify_mutex;
};