C语言总结-----关键字与内存管理
目录
一、关键字
(一)const(恒定不变)
(二)结构体strcut
(三)union共用体/联合体
(四)enum枚举
(五)typedef:给类型起别名
二、内存管理
(一)野指针
(二)栈、堆、数据区、代码区
(三)堆内存申请
一、关键字
(一)const(恒定不变)
1.修饰只读变量:有不可变性
const int max = 10;
int array[max]; //以前定义数组是不能用变量,加了const之后可以
未const之前,变量在可读可写区,加了const之后区域未变,但变成了可读。
const修饰的只读变量必须在定义的同时初始化
2.修饰一般变量:简单类型的只读变量,const可在前,也可在后
int const i = 2;
或
const int i = 2;
3.修饰指针
const int * p; // p可变,p指向的对象不可变
int const * p; // p可变,p指向的对象不可变
int * const p; // p不可变,p指向的对象可变
const int * const p; //指针p和p指向的对象都不可变
这里给出一个记忆和理解的方法:
先忽略类型名(编译器解析的时候也是忽略类型名),我们看const离哪个近,离谁近就修饰谁。
const (int) *p //const 修饰*p,p是指针,*p是指针指向的对象,不可变。
(int) const * p; //const 修饰*p,p是指针,*p是指针指向的对象,不可变。
(int) * const p; //const 修饰p,p不可变,p指向的对象可变
const (int)* const p // 前一个const修饰*p,后一个const修饰p,指针p和p指向的对象都不可变
4.修饰数组
定义或说明一个只读数组可采用如下格式:
int const a[5] = {1,2,3,4,5};
或
const int a[5] = {1,2,3,4,5}
5.修饰函数的参数
不希望这个参数值在函数体内被意外改变时使用
例如:
void Fun(const int *p);
告诉编译器*p在函数体中不能改变,从而防止了使用者的一些无意的或错误的修改。
(二)结构体strcut
1、结构体概念:存放一组不同类型的数据。
- 结构体的定义形式为:
struct 结构体名{
构体所包含的变量或数组
};
- 结构体是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或数组都称为结构体的成员(Member)。请看下面的一个例子:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
};
stu 为结构体名,它包含了 5 个成员,分别是 name、num、age、group、score。结构体成员的定义方式与变量和数组的定义方式相同,只是不能初始化。注意大括号后面的分号;不能少,这是一条完整的语句。结构体也是一种数据类型,它由程序员自己定义,可以包含多个其他类型的数据。像 int、float、char 等是由C语言本身提供的数据类型,不能再进行分拆,我们称之为基本数据类型;而结构体可以包含多个基本类型的数据,也可以包含其他的结构体,我们将它称为混合数据类型。
2、结构体的三种定义方式:
结构体变量
既然结构体是一种数据类型,那么就可以用它来定义变量。例如:
① struct stu stu1, stu2;
定义了两个变量 stu1 和 stu2,它们都是 stu 类型,都由 5 个成员组成。注意关键字struct不能少。
②你也可以在定义结构体的同时定义结构体变量:
struct stu{
} stu1, stu2;
将变量放在结构体定义的最后即可。
③如果只需要 stu1、stu2 两个变量,后面不需要再使用结构体名定义其他变量,那么在定义时也可以不给出结构体名,如下所示:
struct{ //没有写 stu
} stu1, stu2;
这样做书写简单,但是因为没有结构体名,后面就没法用该结构体定义新的变量。
3、内存字节对齐
为了提高运算速度,计算机内允许部分内存空间的浪费。例如:
struct demo1{ struct demo2{
char a; char a;
char b; int b;
int c; char c;
}; };

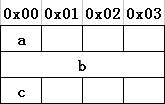
4、结构体使用点号 . 获取单个成员
5、结构体数组
所谓结构体数组,是指数组中的每个元素都是一个结构体。
在实际应用中,结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个车间的职工等。
定义结构体数组和定义结构体变量的方式类似,请看下面的例子:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[5];
表示一个班级有5个学生。
结构体数组在定义的同时也可以初始化,例如:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[5] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};
当对数组中全部元素赋值时,也可不给出数组长度
结构体数组的使用也很简单,例如,获取 Wang ming 的成绩:
class[4].score;
修改 Li ping 的学习小组:
class[0].group = 'B';
6、结构体和指针
(1)结构体指针含义:
指针也可以指向一个结构体,定义的形式一般为:
struct 结构体名 *变量名;
下面是一个定义结构体指针的实例:
struct stu{
} stu1 = { "Tom", 12, 18, 'A', 136.5 };
struct stu *pstu = &stu1;
注意:结构体变量名和数组名不同,数组名在表达式中会被转换为数组指针,而结构体变量名不会,无论在任何表达式中它表示的都是整个集合本身,要想取得结构体变量的地址,必须在前面加&,所以给 pstu 赋值只能写作:
struct stu *pstu = &stu1;
而不能写作:
struct stu *pstu = stu1;
(2)通过结构体指针获取结构体成员
通过结构体指针可以获取结构体成员,一般形式为:
1、(*pointer).memberName
或者:
2、pointer->memberName (常用)
第一种写法中,. 的优先级高于*,(*pointer)两边的括号不能少。
第二种写法中,->是一个新的运算符,它可以通过结构体指针直接取得结构体成员;这也是->在C语言中的唯一用途。
(三)union共用体/联合体
- 共用体(Union),定义格式为:
union 共用体名
{
成员列表
};
- 结构体和共用体的区别在于:
1、结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
2、结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉(保存最后一个成员的信息)。
(四)enum枚举
1、例如,列出一个星期有几天:
enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun };
可以看到,仅仅给出了名字,却没有给出对应的值,这是因为枚举值默认从 0 开始,往后逐个加 1(递增)。
2、我们也可以给每个名字都指定一个值:
enum week{ Mon = 1, Tues = 2, Wed = 3, Thurs = 4, Fri = 5, Sat = 6, Sun = 7 };
3、更为简单的方法是只给第一个名字指定值:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };
这样枚举值就从 1 开始递增,跟上面的写法是等效的。
(五)typedef:给类型起别名
语法格式为:
typedef oldName newName;
例如:
1、typedef int INTEGER;
INTEGER a, b;等效于int a, b;
typedef 还可以给数组、指针、结构体等类型定义别名。
2、typedef char ARRAY20[20];
ARRAY20 a1, a2, s1, s2;它等价于:char a1[20], a2[20], s1[20], s2[20];
3、为结构体类型定义别名:
typedef struct stu{
char name[20];
int age;
char sex;
} STU;
STU body1,body2;它等价于:struct stu body1, body2;
4、为指针类型定义别名:
typedef int (*PTR_TO_ARR)[4];表示 PTR_TO_ARR 是类型int * [4]的别名,它是一个二维数组指针类型。
PTR_TO_ARR p1, p2;
5、为函数指针类型定义别名:
typedef int (*PTR_TO_FUNC)(int, int);
PTR_TO_FUNC pfunc;
typedef与define的区别:
typedef 在表现上有时候类似于 #define,但它和宏替换之间存在一个关键性的区别。正确思考这个问题的方法就是把 typedef 看成一种彻底的“封装”类型,声明之后不能再往里面增加别的东西。
(1) 可以使用其他类型说明符对宏类型名进行扩展,但对 typedef 所定义的类型名却不能这样做。例如:
#define INTERGE int
unsigned INTERGE n; //没问题
typedef int INTERGE;
unsigned INTERGE n; //错误,不能在 INTERGE 前面添加 unsigned
(2) 在连续定义几个变量的时候,typedef 能够保证定义的所有变量均为同一类型,而 #define 则无法保证。例如:
#define PTR_INT int *
PTR_INT p1, p2;
经过宏替换以后,第二行变为:
int *p1, p2;
这使得 p1、p2 成为不同的类型:p1 是指向 int 类型的指针,p2 是 int 类型。
相反,在下面的代码中:
typedef int * PTR_INT
PTR_INT p1, p2;
p1、p2 类型相同,它们都是指向 int 类型的指针。
二、内存管理
(一)野指针
野指针是指向“垃圾”内存的指针,不是NULL。
1、野指针的两种成因
(1)指针变量没有被初始化。
如:char *p;这时p的指向是随机的,对它进行操作很危险。
(2)指针被free之后,没有设置为NULL。
如:free(p);这时p的指向也是随机的。
2、解决办法
初始化时如不知道指针的指向或者free后,将指针赋值为NULL。在对该指针进行操作之前,使用 if 进行判断。如:if(p != NULL)
(二)栈、堆、数据区、代码区
内存一共4G:(1)内核1G (2)栈、堆、数据区、代码区总共3G
栈:保存局部变量(函数内变量和形参)。栈上的内容只在函数的范围内存在,当函数运行结束,这些内容也会自动被销毁。其特点是效率高,但空间大小有限。
堆:为 malloc 系列函数分配的内存(malloc,realloc,calloc)。其生命周期由 free 决定。在没有释放之前一直存在,直到程序结束。其特点是使用灵活,空间比较大,但容易出错。---动态内存分配
数据区:bss(未初始化的全局变量,为0)、初始化的全局变量、static变量(静态局部变量)---静态内存分配 读取、写入。
代码区:存放CPU要执行的指令。读取、执行。
(三)堆内存申请
1.malloc函数
malloc 函数的原型:
(void *)malloc(int size)
malloc 函数的返回值是一个 void 类型的指针,参数为 int 类型数据,即申请分配的内存大小,单位是字节(byte)。内存分配成功之后,malloc 函数返回这块内存的首地址。需要一个指针来接收这个地址。但是由于函数的返回值是 void *类型的,所以必须强制转换成你所接收的类型。
比如:
char *p = (char *)malloc(100);
在堆上分配了 100 个字节内存,返回这块内存的首地址,把地址强制转换成 char *类型后赋给 char *类型的指针变量 p。同时告诉我们这块内存将用来存储 char 类型的数据。也就是说你只能通过指针变量 p 来操作这块内存。
注意:
1、malloc 函数申请内存有不成功的可能,在使用指向这块内存的指针时,必须用 if( NULL != p )语句来验证内存确实分配成功了。
2、调用之前加上头文件 #include
2.free()函数
切断与内存的联系