【天池比赛】街景字符编码识别
一、赛题理解
1.1、注册报名
赛题链接:https://tianchi.aliyun.com/competition/entrance/531795/introduction
1.2、解析赛题数据
报名之后可以获取到比赛中用到的数据,训练集(图片+标签),验证集(图片+标签),测试集(仅图片),其中标签为json文件,可以转换为自己需求的标注文件。
训练集:
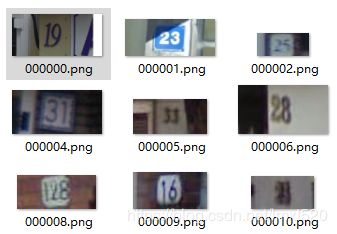
标签:
000000.png: {"height": [219, 219], "label": [1, 9], "left": [246, 323], "top": [77, 81], "width": [81, 96]},
000001.png: {"height": [32, 32], "label": [2, 3], "left": [77, 98], "top": [29, 25], "width": [23, 26]},
标签解析:
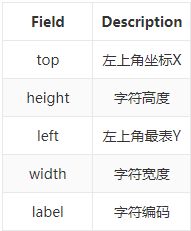
验证集与训练集格式相同。
将标签中的标注框信息绘制到图片中结果如下,每个字符一个检测框,由此可以直接简单粗暴的使用目标检测来解决。

1.3、评分标准

题目中的评分标准为准确率,由此在训练过程中只需要提高精度,不用考虑速度,可以使用rcnn等两阶段系列的网络来进行训练。
二、数据读取及扩增
pytorch中数据读取需要用到Dataset这个类,这个类为所有的datasets的基类存在,通过继承这个类来实现。
源码如下
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
getitem接收一个index,然后返回图片数据和标签,这个index通常指的是一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息。可以为自己创建的txt信息或者直接从标注文件中读取的信息。
读取数据的基本流程如下:
- 制作存储了图片的路径和标签信息的txt
- 将这些信息转化为list,该list每一个元素对应一个样本
- 通过getitem函数,读取数据和标签,并返回数据和标签
在这个字符识别的项目中,标注信息保存在json文件中,可以直接解析json文件,通过以图片名为key来搜索对应的标签,然后组成dataset输入所需要的的list。
示例代码
class SVHNDataset(Dataset):
def __init__(self, img_path, img_label, transform=None):
self.img_path = img_path #图片路径
self.img_label = img_label #对应的图片标签
# 判断是否需要增广,可以在调用该类时直接传入增广的方式,在pytorch中,提供了transform的方法
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
#这里使用的是PIL读取的图片,为确保图片通道格式正确,这里将通道转换为RGB(PIL读取的图片本省就是RGB格式的,转换操作可以省略,使用opencv读取时,图片通道为BGR,转换通道的操作必不可少),总之这个操作获取到的是图片信息
img = Image.open(self.img_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
# 解析标签,提供的baseline方法是将图片的标签统一扩增为6位,缺失的补充为10,然后就可以直接的作为图片分来来解决
lbl = np.array(self.img_label[index], dtype=np.int)
lbl = list(lbl) + (5 - len(lbl)) * [10]
return img, torch.from_numpy(np.array(lbl[:5]))
def __len__(self):
return len(self.img_path)
在上边定义完继承Datasets的数据解析类之后,下边需要根据调用这个类来读取训练,验证,测试数据。baseline代码如下:
#读取图片,获取图片列表,并排序
train_path = glob.glob(r'mchar_train\*.png')
train_path.sort()
#由于标注信息为json文件,结果只需要提供检测结果,不需要字符的位置信息,而且这里提供的是分类的方法,所以直接读取图片的标签,没有使用到每个字符的位置坐标框。
train_json = json.load(open(r'mchar_train.json'))
train_label = [train_json[x]['label'] for x in train_json]
print(len(train_path), len(train_label))
#调用前边定义好的基类,并且使用DataLoader来加载图片和标签信息。
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path, train_label,
#以下操作为数据增广操作,可以根据电脑配置自行取舍,当然,使用的增广方式越多,数据集种类就越多,结果相应的也就越好。
transforms.Compose([
transforms.Resize((64, 128)),#将图片重置为64*128,以此来固定网络的输入,当图片大小不固定时,网络输入层通道数就无法直接设置
transforms.RandomCrop((60, 120)),#随机裁剪,将resize之后的图片随机裁剪出60*120大小的图片
transforms.ColorJitter(0.3, 0.3, 0.2),#修改图片亮度,对比度,饱和度
transforms.RandomRotation(10),#随机旋转
transforms.ToTensor(),#将PIL Image或者 ndarray 转换为tensor,并且归一化至[0-1]
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#对数据按通道进行标准化,即先减均值,再除以标准差,注意是 chw
])),
batch_size=40, #每一个batch设置为40张图片,这个值可以根据电脑配置来自行设置
shuffle=True, #是否打乱顺序
num_workers=0,#读取的线程个数
)
pytorch自带的数据增广的方式有很多,可以参考官方文档来自行选取。当然也可以使用opencv进行数据增广的操作,该操作相对独立,和pytorch没有太大关系,在数据量较少的情况下,可以采用两种方式并行的方法,来增加数据量。
三、神经网络设计
数据读取之后,就可以把数据传入网络中了,如上可知,直接将问题转化为分类问题,可以采用经典的分类网络来解决。在之前的总结中,介绍了LeNet-5和AlexNet网络,可做为参考。
本baseline直接调用的pytorch中自带的resnet18的网络,直接调用的语句如下:
model_conv = models.resnet18(pretrained=True)
#将resnet18中的最后一层平均池化层进行修改
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
#抛弃最后一层的全连接层,自带的全连接层输出是1000,输出只有11个
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
ResNet为卷积残差网络,解决了卷积中层数越深,模型效果越差的问题(深层网络导致的梯度衰减)
简单的神经网络由输入层,隐含层,输出层构成:
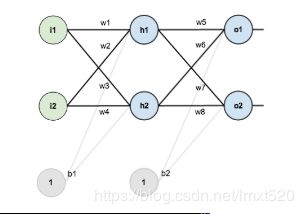
反向传播原理,先通过正向传播计算出结果output,然后与样本比较得出误差值
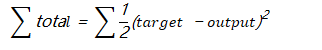
根据误差结果,利用链式求导 使结果误差反向传播从而得出权重w调整的梯度。下图是输出结果到隐含层的反向传播过程(隐含层到输入层的反向传播过程也是类似)

通过不断迭代,对参数矩阵进行不断调整后,使得输出结果的误差值更小,使输出结果与事实更加接近。
神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失(假如采用Sigmoid函数,对于幅度为1的信号,每向后传递一层,梯度就衰减为原来的0.25,层数越多,衰减越厉害),导致无法对前面网络层的权重进行有效的调整。
3.1、深度残差网络的提出
为解决梯度衰减的问题,假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。
基本结构如下:
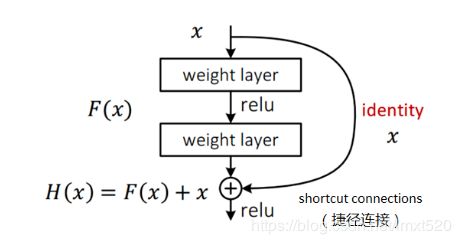
回归到本赛题中,采用的Resnet18就是残差网络的一个最简单的网络,此外还有ResNet34,ResNet50,
ResNet101,ResNet152等。其中的18,34,50,101,代表的是网络的深度,包括卷积层和全连接层,不包括池化层和BN层。以下为ResNet论文中给出的结构列表。

了解了上述列表之后,将baseline中的网络层打印出出来,如下
SVHN_Model(
(cnn): Sequential(
# 卷积层,in_channel=3,out_channel=64,卷积核7*7,步长2*2,扩边3*3,不使用bias
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# 添加bn层
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# ReLU线性修正单元,
(2): ReLU(inplace)
# 池化层,为3*3的核,步长为2,扩边1
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
.
.
.
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): AdaptiveAvgPool2d(output_size=1)
)
# 将输出层由原来的512->1000修改为512->11,并且使用bias参数
(fc1): Linear(in_features=512, out_features=11, bias=True)
(fc2): Linear(in_features=512, out_features=11, bias=True)
(fc3): Linear(in_features=512, out_features=11, bias=True)
(fc4): Linear(in_features=512, out_features=11, bias=True)
(fc5): Linear(in_features=512, out_features=11, bias=True)
)
3.2、网络替换
尝试resnet18之后,感觉正确率只有0.36左右,所以想要尝试其他网络。首先就是使用更深的残差网络ResNet101,由上边的表格可以知道,ResNet101的最后一层输出为2048,所以直接简单粗暴的替换是会出现问题的,所以需要在最后的全连接层前边添加2048->512的全连接层,这样网络中的参数就可以对应起来了。
3.3、目标检测网络尝试
由于使用分类网络的效果不尽如人意,遂尝试目标检测的方法来解决。在检测网络中,比较简单易上手的就是darknet的yolov3,可以从darknet官网下载,直接安装,下载预训练模型,配置好网络参数之后就可以尝试了,darknet官网也提供了使用方法。我自己在使用过程中,由于anchors直接采用的coco数据集的,预训练模型也是同样,导致效果一直不佳,下一步准备自己训练预处理模型,自行使用kmeans++方法得出图片的anchors,并且替换过去,尝试下效果。
四、模型预测和验证
4.1、训练前期准备
在模型训练中一般需要将数据分为三部分,训练集(训练和调整参数),验证集(验证精度和调整超参),测试集(验证泛化能力),三部分数据相互独立,训练集中数据不可以在验证集和测试集中出现。
划分比例
-
没有验证集时,训练集和测试集一般为7:3
-
含有验证集时(数据量不大,万级别以下),训练集:验证集:测试集 = 6:2:2
-
在数据量百万级别,训练集:验证集:测试集=98:1:1
注:以上的比例需要按照分类的数量来进行拆分的,比如在mnist数据集中,训练集和测试集中标记为1的数据集的量按照7:3来进行拆分,标记为2的也一样。
验证集的划分方法
- 留出法
直接按照固定的比例进行拆分,简单粗暴,但是只能获取到一份验证集,可能导致在验证集上过拟合,适用于量级较大的情况。 - 交叉验证法
将数据集分为K份,每次使用时训练集取其中的k-1份,验证集取其中的1份,循环K次进行训练,可以提升验证集的精度,但是训练次数较多,不适用大量数据。一般k常取10。 - 自助采样法
通过有放回的将数据集手动的拆分为训练集和测试集,效果与交叉验证相似,需要手动操作,同样适用于数据量较少的训练工作。
在本测试中,已经将训练集和测试集给定了,但是可以按照需求自行将数据集合并,然后按照交叉验证的方法进行多次训练验证,以提升模型的精度。
模型的训练前提是需要准备好的数据和设计好的网络,在前边已经将数据使用pytorch进行加载到train_loader这个对象里边,网络也按照baseline中采用的resnet18网络。
4.2、模型训练
pytorch中数据训练操作相对简单,选定模型,损失函数,优化器,然后就可以循环多个epoch来进行训练了。代码如下:
# 选择模型为上述定义的SVHN
model = SVHN_Model1()
# 选择损失函数,这里采用的是交叉熵损失
criterion = nn.CrossEntropyLoss()
# 选择优化器,采用的是adam优化方法
optimizer = torch.optim.Adam(model.parameters(), 0.001)
# 循环10个epoch
for epoch in range(10):
#设置为train模式,resnet18含有bn层,由于含有bn层和dropout层时,训练和验证的forward的不相同,所以需要制定是训练还是验证模式
model.train()
#迭代的方法从train_loader中加载训练图片和label,每次加载batch个数据。这里的batch为40.input为图片信息,target为标注信息
for i, (input, target) in enumerate(train_loader):
#转换类型,
target = target.long()
#将数据传入模型实例化中,返回5为预测值
c0, c1, c2, c3, c4 = model(input)
#使用已经设置好的损失函数来计算,分类任务,最后的输出层为6个,可以将6个数字的损失函数汇总来计算,也可以求平均。
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3]) + \
criterion(c4, target[:, 4])
# loss /= 6
#将梯度置0,把loss关于weight的倒数变成0,为了不影响下一次的使用,每一个batch处理一次,因为每个batch是相互独立的
optimizer.zero_grad()
#反向传播
loss.backward()
#更新优化器的学习率
optimizer.step()
#至此,一个batch循环结束了
通过对baseline的解析,大致了解了torch的训练过程
-
选择模型
-
定义损失函数
-
选择有优化器,并且将网络参数传入优化器
-
循环次数,定义epoch
-
选择是否是训练或者验证(看是否需要)
-
枚举循环训练集数据和标签信息,每次循环一个batch,在dataloader中定义。
-
将数据信息传入网络中,并返回训练结果的值
-
将预测值和训练值使用损失函数计算loss
-
反向传播,优化参数
-
-
4.3、模型验证
训练完一个epoch后,将验证集数据传入网络中进行验证,同样需要获取到模型预测的值和验证集的标签值,将两个值进行对比,计算得到预测的正确率。
验证代码如下:
#将模型改为验证方法
model.eval()
val_loss = []
# 不记录模型梯度信息
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
c0, c1, c2, c3, c4, c5 = model(data[0])
loss = criterion(c0, data[1][:, 0]) + \
criterion(c1, data[1][:, 1]) + \
criterion(c2, data[1][:, 2]) + \
criterion(c3, data[1][:, 3]) + \
criterion(c4, data[1][:, 4]) + \
criterion(c5, data[1][:, 5])
loss /= 6
#获取验证集的loss
val_loss.append(loss.item())
4.4、模型保存读取
pytorch中模型保存与读取的操作很简单,只需要一个指令即可,但是分为两种方式,一种只保存模型参数,另一种可以保存整个网络
#1.只保存模型的参数,序列化为字典,只有可修改参数的层可以被序列化,save的对象为state_dict,
torch.save(model_object.state_dict(), 'model.pt')
#当调用只保存参数的模型时,需要先导入对应的网络
model.load_state_dict(torch.load(' model.pt'))
#2.保存完整模型,save的对象是网络model
torch.save(model,PATH)
#直接初始化新的神经网络对象
model = torch.load(PATH)
五、 深度学习的集成学习方法
5.1、概念
深度学习中存在的问题:
-
神经网络具有很高的方差,不易复现出结果,而且模型的结果对初始化参数异常敏感。
-
使用集成模型可以有效降低神经网络的高方差(variance)。
集成模型的作用:
- 训练多个模型,并将预测结果结合到一起,能够降低方差。
- 多模型集成能起到作用的前提是,每个模型有自己的特点,每个模型预测出的误差是不同的。
- 简单的集成方式就是将预测结果取平均,该方法起作用的原因是,不同的模型通常不会在测试集上产生相同的错误。
- 结合多个模型使得最终的预测结果添加了一个偏差(bias),而这个偏差又会与神经网络的方差(variance)相抵消,使得模型的预测对训练数据的细节、训练方案的选择和单次训练运行的偶然性不太敏感。
- 集成模型的结果会比任意单模型的结果都要好。
5.2、集成模型方法
在机器学习中常用的集成学习方法有Stacking、Bagging和Boosting,这些集成方法与具体的验证集划分联系紧密,大致都是将训练集分为多分,然后分别训练模型,最后按照一定的规则进行集成。
常用的拆分方法为10折交叉验证法,将训练集拆分为10份,分别使用同一个网络,同样的初始化参数来训练。然后将得到的10个cnn模型选择下边的方法进行集成:
-
对预测的概率值进行平均,然后解码为具体字符
该操作需要在网络中获取预测值分布的那一层进行截取数据,在本比赛中为最后的全连接层,然后将10个cnn模型的值全部获取,然后针对每一位相加求平均,将最后的结果概率最高的那个为最终的结果。
-
对预测的字符进行投票,得到最终的字符
该操作不需要在卷积网络上进行,只需要在最后获取结果时,将10个cnn模型得到的结果进行投票,出现次数最多的为当前的结果。该操作相对简单。
5.3、深度学习中的集成学习
-
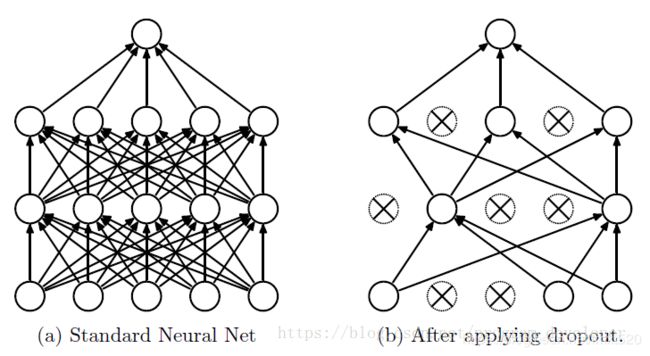
Dropout
Dropout是训练深度学习中防止过拟合常用的技巧,在每个卷积层中随机的阻止一些网络参数的传播,这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
-
TTA(测试集数据增广)
在进行测试过程中,通过对测试数据的增广,同一份数据可以获取多份结果,然后将多份结果进行平均,来增大预测的概率。
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
# 使用一种测试集的多种方式进行预测
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
c0, c1, c2, c3, c4, c5 = model(data[0])
output = np.concatenate([c0.data.numpy(), c1.data.numpy(),
c2.data.numpy(), c3.data.numpy(),
c4.data.numpy(), c5.data.numpy()], axis=1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
-
snapshot(快照)
在模型训练过程中,可以在每个epoch中保存模型,并且可以计算出当前模型的acc和loss,可以设置一个阈值,当准确率高于这个阈值时,就保存一次模型,这样就可以在一份训练集,一个网络中获取到多个效果还算不错的模型。有了多个模型就可以进行上述的多模型集成操作。
未完待续。。。。。