c++汉字字符处理
问题:实现Apriori算法时的数据集为中文,所以需要用到汉字字符处理。现搜集整合如下。
#include 测试结果: 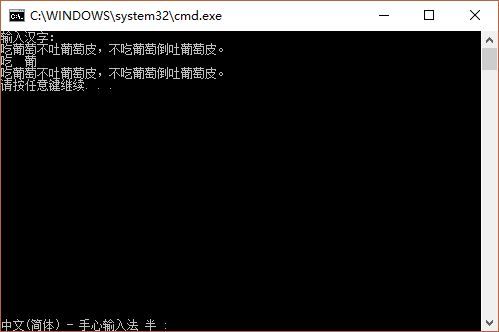
- 转载1 关于C中文字符的处理
- 一 引入问题
- 二 解决引入问题所需的知识
- 三 汉字的编码方式及在vcc中的处理
- 汉字编码方式的介绍
- vc中汉字的编码方式
- 新的内码标准Unicode
- 内码的相互转换
- 四 vc中的MutiByte Charater Set 和 Wide Character Set
- MultiByte Charater Set方式
- Wide Character Set
- 五 引入问题的错误分析
- 转载2 C读写汉字C处理中文字符
- 扩展1 unicode-ansi-utf-8-unicode-big-endian编码的区别
- 扩展2 各种字符集编码
- 扩展3 Unicode 和 UTF-8 有何区别知乎
转载1 关于C++中文字符的处理
一 引入问题
代码 wchar_t a3=L”中国”,编译时出错,出错信息为:数组越界。但wchar_t 是一个宽字节类型,数组a的大小应为6个字节,而两个汉字的的unicode码占4个字节,再加上一个结束符,最多6个字节,所以应该不会越界。难道是编译器出问题了?
二 解决引入问题所需的知识
主要需两方面的知识
1. 字符尤其是汉字的编码,以及语言和工具的支持情况
2. vc/c++中MutiByte Charater Set 和 Wide Character Set有关内存分配的情况.
三 汉字的编码方式及在vc/c++中的处理
1.汉字编码方式的介绍
对英文字符的处理,7位ASCII码字符集中的字符即可满足使用需求,且英文字符在计算机上的输入及输出也非常简单,因此,英文字符的输入、存储、内部处理和输出都可以只用同一个编码(如ASCII码)。
而汉字是一种象形文字,字数极多(现代汉字中仅常用字就有六、七千个,总字数高达5万个以上),且字形复杂,每一个汉字都有”音、形、义”三要素,同音字、异体字也很多,这些都给汉字的的计算机处理带来了很大的困难。要在计算机中处理汉字,必须解决以下几个问题:首先是汉字的输入,即如何把结构复杂的方块汉字输入到计算机中去,这是汉字处理的关键;其次,汉字在计算机内如何表示和存储?如何与西文兼容?最后,如何将汉字的处理结果从计算机内输出?
为此,必须将汉字代码化,即对汉字进行编码。对应于上述汉字处理过程中的输入、内部处理及输出这三个主要环节,流程如下:
(1) 输入码
作用是,利用它和现有的标准西文键盘结合来输入汉字。输入码也称为外码。主要归为四类:
数字编码
数字编码是用等长的数字串为汉字逐一编号,以这个编号作为汉字的输入码。例如,区位码、电报码等都属于数字编码。拼音码
拼音码是以汉字的读音为基础的输入办法。字形码
字形码是以汉字的字形结构为基础的输入编码。例如,五笔字型码(王码)。音形码
音形码是兼顾汉字的读音和字形的输入编码。
(2) 交换码
用于汉字外码和内部码的交换。交换码的国家标准代号为GB2312-8090。
(3) 内部码
内部码是汉字在计算机内的基本表示形式,是计算机对汉字进行识别、存储、处理和传输所用的编码。内部码也是双字节编码,将国标码两个字节的最高位都置为”1”,即转换成汉字的内部码。
(4) 字形码
字形码是表示汉字字形信息(汉字的结构、形状、笔划等)的编码,用来实现计算机对汉字的输出(显示、打印)。
2.vc中汉字的编码方式
vc/c++正是采用了GB2312内部码作为汉字的编码方式,因此vc/c++中的各种输入输出方法,如cin/wcin,cout/wcout,scanf/wsanf,printf/wprintf…都是基于GB2312的,如果汉字的内码不是这种编码方式,那么利用上述各种方法就不会正确的解析汉字。
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | “ | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | |
| 9 | HT | 41 | ) | 73 | I | 105 | |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
| NUL空 | VT 垂直制表 | SYN 空转同步 |
|---|---|---|
| STX 正文开始 | CR 回车 | CAN 作废 |
| ETX 正文结束 | SO 移位输出 | EM 纸尽 |
| EOY 传输结束 | SI 移位输入 | SUB 换置 |
| ENQ 询问字符 | DLE 空格 | ESC 换码 |
| ACK 承认 | DC1 设备控制1 | FS 文字分隔符 |
| BEL 报警 | DC2 设备控制2 | GS 组分隔符 |
| BS 退一格 | DC3 设备控制3 | RS 记录分隔符 |
| HT 横向列表 | DC4 设备控制4 | US 单元分隔符 |
| LF 换行 | NAK 否定 | DEL 删除 |
仔细观察ASCII字符表,从第161个字符开始,后面的字符并不经常为用户所使用,负值也未使用。GB2312编码方式充分利用这一特性,将161-255(-95~-1)之间的数值空间作为汉字的标识码。既然255-161 = 94不能满足汉字容量的要求,就将每两个字符并在一块(即一个汉字占两个字节),显然,94* 94 =8836基本上已经满足了常用汉字个数的要求。计算机处理字符时,当连续处理到两个大与160(或-95~-1)的字节时,就认为这两个字节存放了一个汉字字符。可以用下面的Demo程序来模拟vc/c++中输出汉字字符的过程。
unsigned char input[50];
cin>>input;
int flag=0;
for(int i =0 ;i < 50 ;i++)
{
if(input[i] > 0xa0 && input[i] != 0)
{
if(flag == 1)
{
cout<<"chinese character"<
flag = 0;
}
else
{
flag++;//一字节,前四位识别,后四位确定并输出,见上一段if程序
}
}
else if(input[i] == 0)
{
break;
}
else
{
cout<<"english character"<
flag=0;
}
}输入:Hello中国 (“中国”对应的GB2312内码为:214 208,185 250)
输出:english character
english character
english character
english character
english character
chinese character
chinese character
vc/c++中的英文字符仍然采用ASCII编码方式。可以设想,其他国家程序员利用vc/c++编写程序输入本国字符时,vc/c++则会采用该国的字符编码方式来处理这些字符。
问题又产生了,韩国的vc/c++程序在中国的vc/c++上运行时,如果没有相应的内码库,则对韩语字符的显示有可能出现乱码。我个人猜测,vc安装程序中应该带有不同国家的内码库,这样一来肯定会占用很大的空间。如果所有的国家使用统一的编码方式,且所有的程序设计语言和开发工具都支持这种编码方式该多好!而现实中,确实已经有这种编码方式了,且许多新的语言也都支持这种编码方式,如Java、C#等,它就是下面的Unicode编码
3.新的内码标准—Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
在Unicode 5.0.0版本中,已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其中平面15和平面16上只是定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。所谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA。
平面0也有一个专用区:0xE000-0xF8FF,有6400个码位。平面0的0xD800-0xDFFF,共2048个码位,是一个被称作代理区(Surrogate)的特殊区域。代理区的目的用两个UTF-16字符表示BMP以外的字符。在介绍UTF-16编码时会介绍。
如前所述在Unicode 5.0.0版本中,238605-65534*2-6400-2048=99089。余下的99089个已定义码位分布在平面0、平面1、平面2和平面14上,它们对应着Unicode定义的99089个字符,其中包括71226个汉字。平面0、平面1、平面2和平面14上分别定义了52080、3419、43253和337个字符。平面2的43253个字符都是汉字。平面0上定义了27973个汉字。
在Unicode中:汉字“字”对应的数字是23383(十进制),十六进制表示为5B57。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“Unicode Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。
例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
char data_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97};//UTF-8编码
char16_t data_utf16[]={0x6C49,0x5B57}; //UTF-16编码
char32_t data_utf32[]={0x00006C49,0x00005B57};//UTF-32编码这里用char、char16_t、char32_t分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以char、char16_t、char32_t作为编码单位。(注: char16_t 和 char32_t 是 C++ 11 标准新增的关键字。如果你的编译器不支持 C++ 11 标准,请改用 unsigned short 和 unsigned long。)“汉字”的UTF-8编码需要6个字节。“汉字”的UTF-16编码需要两个char16_t,大小是4个字节。“汉字”的UTF-32编码需要两个char32_t,大小是8个字节。
Unicode 编码系统可分为编码方式和实现方式两个层次。
编码方式(此文作于08年)
Unicode 的编码方式与 ISO 10646 的通用字符集(Universal Character Set,UCS)概念相对应,目前的用于实用的 Unicode 版本对应于 UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示 216 个字符。基本满足各种语言的使用。实际上目前版本的 Unicode 尚未填充满这16位编码,保留了大量空间作为特殊使用或将来扩展。实现方式
Unicode 的实现方式不同于编码方式。
目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。
一个字符的 Unicode 编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对 Unicode 编码的实现方式有所不同。
Unicode 的实现方式称为Unicode转换格式(Unicode Translation Format,简称为 UTF)。如,UTF-8 编码,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他 Unicode 字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1进行识别。
Java与C#语言都是采用Unicode编码方式,在这两种语言中定义一个字符,在内存中存放的就是这个字符的两字节Unicode码。如下所示:
char a=’我’; => 内存中存放的Unicode码为:25105
4.内码的相互转换
(1) vc中的实现方法
利用Windows系统提供的API:::MultiByteToWideChar和::WideCharToMultiByte
::MultiByteToWideChar:实现当前码到Unicode码的转换;
::WideCharToMultiByte:实现Unicode码到当前码的转换;
(2) Java中的实现方法
String vcString=new String(javaString.getBytes(“UTF-8”),”gb2312”);
java的编码应该是UTF-8
(3) C#中的实现方法
??
四 vc中的MutiByte Charater Set 和 Wide Character Set
1.MultiByte Charater Set方式
这种方式以按字节为单位存放字符,即如果一个字符码为两字节,则在内存中占两字节,字符码为一字节,就占一字节。例如,字符串“中国abc”的编码为:中(0xd6、0xd0)、国(0xb9、0xfa)、a(0x61)、b(0x62)、c(0x63)、\0(0x00),就存为如下方式: 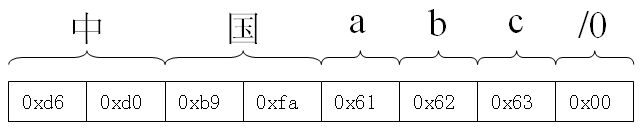
对应的类型,方法有:char、scanf、printf、cin、cout …
2.Wide Character Set
这种方式是以两字节为单位存放字符,即如果一个字符码为两字节,则在内存中占四字节,字符码为一字节,就占两字节。例如,字符串“中国abc”就存为如下方式: 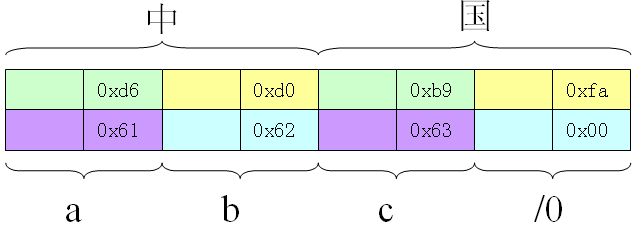
对应的类型,方法有:wchar_t、wscanf、wprintf、wcin、wcout …
造成上面存储方式的根本原因在于,wchar_t类型其实是一个unsigned short 类型。如,存储上面字符串的数组的定义为:wchar_t buffer[8] 等价于unsigned short buffer[8].而所有以字母w开头的方法也都是以unsigned short类型,即两字节为单位来处理字符,因此,存储在wchar_t类型数组中的字符串无法用cout显示,只能用wcout方法来显示。
由于Unicode码也是采用两个字节,因此Wide Character Set方式能够很好的支持Unicode码的存储,但是在vc的环境下要将一个Unicode码存入两字节而不是四字节内存中,必须通过上面的API函数::MultiByteToWideChar。首先,将当前的编码转换为Unicode码,然后,将每个字符的Unicode码放入每一个wchar_t类型的变量中。以下是一个实例代码:
char input[50];
cin>>input;
int size;
size=::MultiByteToWideChar(CP_ACP,0,input,strlen(input)+1,NULL,0);
if(size==0)
return -1;
wchar_t *widebuff=new wchar_t[size];
::MultiByteToWideChar(CP_ACP,0,input,strlen(input)+1,widebuff,size);输入:中国abc
Debug断点调试:
size==6
数组widebuff[0-size]占12字节,存放了6个字符的Unicode码,码值为:
中(0x4e2d) 国(0x56fd) a(0x0061) b(0x0062) c(0x0063) d(0x0000)
这时,数组的大小size等于输入的字符个数加上一个结束符,符合我们的想象。
五 引入问题的错误分析
没有理解编译器中的编码方式
虽然vc/c++中汉字的编码占两个字节,但并不是Unicode码,是GB2312码。没有理解MutiByte Charater Set 和 Wide Character Set的存储原则;
在vc/c++中,“中国”按char5来对待,而wchar_t a3实际上是三个unsigned short类型的变量,因此赋值时会越界。
转载2 C++读写汉字,C++处理中文字符
扩展1 unicode-ansi-utf-8-unicode-big-endian编码的区别
2010年上传的文章,但是真的深入浅出,推荐。