一、集合框架分析List系列
一、集合框架
1、集合类基础
(1)为什么出现集合类?
面向对象对事物的体现都是以对象的形式,为了方便对多个对象的操作,就对对象进行存储。集合就是存储对象最常用的一种方式。
(2)数组和集合都是容器,两者有何不同?
- 数组长度固定,而集合长度是可变的。
- 数组值可以存储对象,还可以存储基本数据类型;而集合只能存储对象。
- 数组存储数据类型是固定的,而集合存储的数据类型不固定。
(3)集合类的特点:
- 集合只能存储对象。
- 集合的长度是可变的。
- 集合可以存储不同类型的对象。
(4)集合类框架(重要):
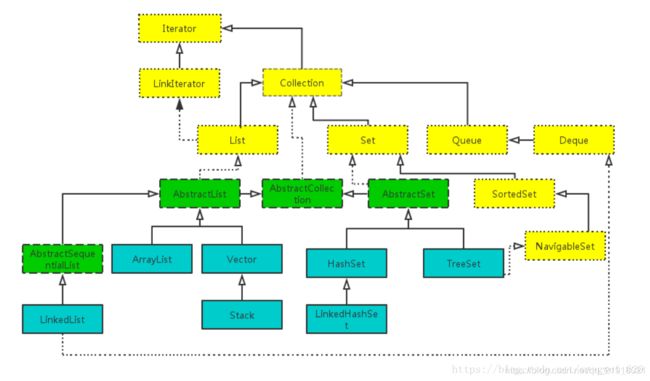

2、java集合框架概述
从上面的集合框架图可以看到,Java集合框架主要包括两种类型的容器。
一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection接口又有3种子类型,List、Set和Queue,再下面是一些抽象类,最后是具体实现类,常用的有ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap等等。
3、Collection接口
首先看一下Collection的源码结构(去掉了部分注释):
public interface Collection<E> extends Iterable<E> {
// Query Operations
/**
* Returns the number of elements in this collection.
*/
int size();
/**
* Returns true if this collection contains no elements.
* @return true if this collection contains no elements
*/
boolean isEmpty();
/**
* Returns true if this collection contains the specified element.
* More formally, returns true if and only if this collection
* contains at least one element e such that
*/
boolean contains(Object o);
/**
* Returns an iterator over the elements in this collection.
*/
Iterator<E> iterator();
/**
* Returns an array containing all of the elements in this collection.
*/
Object[] toArray();
/**
* Returns an array containing all of the elements in this collection;
*/
<T> T[] toArray(T[] a);
// Modification Operations
/**
* Ensures that this collection contains the specified element (optional
* operation).
*/
boolean add(E e);
/**
* Removes a single instance of the specified element from this
* collection, if it is present (optional operation).
*/
boolean remove(Object o);
// Bulk Operations
/**
* Returns true if this collection contains all of the elements
* in the specified collection.
*/
boolean containsAll(Collection<?> c);
/**
* Adds all of the elements in the specified collection to this collection
* (optional operation).
*/
boolean addAll(Collection<? extends E> c);
/**
* Removes all of this collection's elements that are also contained in the
* specified collection (optional operation).
*/
boolean removeAll(Collection<?> c);
/**
* Removes all of the elements of this collection that satisfy the given
* predicate. Errors or runtime exceptions thrown during iteration or by
* the predicate are relayed to the caller.
* @since 1.8
*/
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
/**
* Retains only the elements in this collection that are contained in the
* specified collection (optional operation).
*/
boolean retainAll(Collection<?> c);
/**
* Removes all of the elements from this collection (optional operation).
* The collection will be empty after this method returns.
*/
void clear();
// Comparison and hashing
/**
* Compares the specified object with this collection for equality.
*/
boolean equals(Object o);
/**
* Returns the hash code value for this collection.
*/
int hashCode();
/**
* Creates a {@link Spliterator} over the elements in this collection.
*/
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
/**
* Returns a sequential {@code Stream} with this collection as its source.
* @return a sequential {@code Stream} over the elements in this collection
* @since 1.8
*/
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
/**
* Returns a possibly parallel {@code Stream} with this collection as its
* source. It is allowable for this method to return a sequential stream.
* @since 1.8
*/
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}
Collection接口是处理对象集合的根接口,其中定义了很多对元素进行操作的方法,AbstractCollection是提供Collection部分实现的抽象类。上图展示了Collection接口中的全部方法。
有几个比较常用的方法,比如方法:
- add()添加一个元素到集合中,
- addAll()将指定集合中的所有元素添加到集合中,
- contains()方法检测集合中是否包含指定的元素,
- toArray()方法返回一个表示集合的数组。
Collection接口有三个子接口,下面详细介绍。
4、List
List接口扩展自Collection,它可以定义一个允许重复的有序集合,从List接口中的方法来看,List接口主要是增加了面向位置的操作,允许在指定位置上操作元素,同时增加了一个能够双向遍历线性表的新列表迭代器ListIterator。
public interface List<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
/**
* Returns an iterator over the elements in this list in proper sequence.
*
* @return an iterator over the elements in this list in proper sequence
*/
Iterator<E> iterator();
/**
* Returns an array containing all of the elements in this list in proper
* sequence (from first to last element).
*/
Object[] toArray();
/**
* Returns an array containing all of the elements in this list in
* proper sequence (from first to last element);
*/
<T> T[] toArray(T[] a);
// Modification Operations
/**
* Appends the specified element to the end of this list (optional
* operation).
*/
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
/**
* Appends all of the elements in the specified collection to the end of
* this list, in the order that they are returned by the specified
* collection's iterator (optional operation).
*/
boolean addAll(Collection<? extends E> c);
/**
* Inserts all of the elements in the specified collection into this
* list at the specified position (optional operation).
*/
boolean addAll(int index, Collection<? extends E> c);
/**
* Removes from this list all of its elements that are contained in the
* specified collection (optional operation).
*/
boolean removeAll(Collection<?> c);
/**
* Retains only the elements in this list that are contained in the
* specified collection (optional operation). In other words, removes
* from this list all of its elements that are not contained in the
* specified collection.
*/
boolean retainAll(Collection<?> c);
/**
* Replaces each element of this list with the result of applying the
* operator to that element. Errors or runtime exceptions thrown by
* the operator are relayed to the caller.
*
* @implSpec
* The default implementation is equivalent to, for this {@code list}:
* {@code
* final ListIterator li = list.listIterator();
* while (li.hasNext()) {
* li.set(operator.apply(li.next()));
* }
* }
*
* If the list's list-iterator does not support the {@code set} operation
* then an {@code UnsupportedOperationException} will be thrown when
* replacing the first element.
* @since 1.8
*/
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
/**
* Sorts this list according to the order induced by the specified
* {@link Comparator}.
* @since 1.8
*/
@SuppressWarnings({"unchecked", "rawtypes"})
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
/**
* Removes all of the elements from this list (optional operation).
* The list will be empty after this call returns.
*
* @throws UnsupportedOperationException if the clear operation
* is not supported by this list
*/
void clear();
boolean equals(Object o);
int hashCode();
E get(int index);
E set(int index, E element);
/**
* Inserts the specified element at the specified position in this list
* (optional operation).
*/
void add(int index, E element);
/**
* Removes the element at the specified position in this list (optional
* operation).
*/
E remove(int index);
// Search Operations
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
*/
int indexOf(Object o);
/**
* Returns the index of the last occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
*/
int lastIndexOf(Object o);
// List Iterators
/**
* Returns a list iterator over the elements in this list (in proper
* sequence).
*/
ListIterator<E> listIterator();
/**
* Returns a list iterator over the elements in this list (in proper
* sequence), starting at the specified position in the list.
*/
ListIterator<E> listIterator(int index);
/**
* Returns a view of the portion of this list between the specified
* fromIndex, inclusive, and toIndex, exclusive.
*/
List<E> subList(int fromIndex, int toIndex);
/**
* Creates a {@link Spliterator} over the elements in this list.
* @since 1.8
*/
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
}
AbstractList类提供了List接口的部分实现,AbstractSequentialList扩展自AbstractList,主要是提供对链表的支持。下面介绍List接口的两个重要的具体实现类,也是我们可能最常用的类,ArrayList和LinkedList。
5、ArrayList的实现
对于ArrayList而言,它实现List接口、底层使用数组保存所有元素。其操作基本上是对数组的操作。下面我们来分析ArrayList的源代码:
实现的接口
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{}
- ArrayList继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
- ArrayList实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
- ArrayList实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
- ArrayList实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
底层使用数组实现
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer.
*/
private transient Object[] elementData;
构造方法
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this(10);
}
/**
* Constructs an empty list with the specified initial capacity.
*/
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
ArrayList提供了三种方式的构造器:
public ArrayList()可以构造一个默认初始容量为10的空列表;
public ArrayList(int initialCapacity)构造一个指定初始容量的空列表;
public ArrayList(Collection<? extends E> c)构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回它们的顺序排列的。
存储
ArrayList中提供了多种添加元素的方法,下面将一一进行讲解:
- set(int index, E element):该方法首先调用rangeCheck(index)来校验index变量是否超出数组范围,超出则抛出异常。而后,取出原index位置的值,并且将新的element放入Index位置,返回oldValue。
/**
- Replaces the element at the specified position in this list with
- the specified element.
*/
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
/**
- Checks if the given index is in range. If not, throws an appropriate
- runtime exception.
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
- add(E e):该方法是将指定的元素添加到列表的尾部。当容量不足时,会调用grow方法增长容量。
/**
* Appends the specified element to the end of this list.
* * @param e element to be appended to this list
* @return true (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
- add(int index, E element):在index位置插入element。
/**
* Inserts the specified element at the specified position in this
* list.
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
- addAll(Collection c)和addAll(int index, Collection c):将特定Collection中的元素添加到Arraylist末尾。
/**
* Appends all of the elements in the specified collection to the end of
* this list, in the order that they are returned by the
* specified collection's Iterator.
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
/**
* Inserts all of the elements in the specified collection into this
* list, starting at the specified position.
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
在ArrayList的存储方法,其核心本质是在数组的某个位置将元素添加进入。但其中又会涉及到关于数组容量不够而增长等因素。
读取
这个方法就比较简单了,ArrayList能够支持随机访问的原因也是很显然的,因为它内部的数据结构是数组,而数组本身就是支持随机访问。该方法首先会判断输入的index值是否越界,然后将数组的index位置的元素返回即可。
/**
* Returns the element at the specified position in this list.
*/
public E get(int index) {
rangeCheck(index);
return (E) elementData[index];
}
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
删除
ArrayList提供了根据下标或者指定对象两种方式的删除功能。需要注意的是该方法的返回值并不相同,如下:
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
/**
* Removes the first occurrence of the specified element from this list,
* if it is present.
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
注意:从数组中移除元素的操作,也会导致被移除的元素以后的所有元素的向左移动一个位置。
调整数组容量
从上面介绍的向ArrayList中存储元素的代码中,我们看到,每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。数组扩容有两个方法,其中开发者可以通过一个public的方法ensureCapacity(int minCapacity)来增加ArrayList的容量,而在存储元素等操作过程中,如果遇到容量不足,会调用priavte方法private void ensureCapacityInternal(int minCapacity)实现。
public void ensureCapacity(int minCapacity) {
if (minCapacity > 0)
ensureCapacityInternal(minCapacity);
}
private void ensureCapacityInternal(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
从上述代码中可以看出,数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍(从int newCapacity = oldCapacity + (oldCapacity >> 1)这行代码得出)。这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
Fail-Fast机制
ArrayList也采用了快速失败的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
关于Fail-Fast的更详细的介绍,我将在HashMap中详细说明。
6、LinkedList的实现
LinkedList和ArrayList一样,都实现了List接口,但其内部的数据结构有本质的不同。LinkedList是基于链表实现的(通过名字也能区分开来),所以它的插入和删除操作比ArrayList更加高效。但也是由于其为基于链表的,所以随机访问的效率要比ArrayList差。
看一下LinkedList的类的定义:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{}
LinkedList使用较多的是add、get和remove,源码的分析也将对这三个方法进行分析。
add方法
public boolean add(E e) {
//把e放在链表的最后一个位置
linkLast(e);
return true;
}
void linkLast(E e) {
//last是链表最后一个节点的引用,现在l也指向最后一个节点
final Node<E> l = last;
//调用Node(Node prev, E element, Node next)构造方法
final Node<E> newNode = new Node<>(l, e, null);
//last节点指向newNode
last = newNode;
//如果l为空,则链表为空,直接把newNode链接在首节点后面即可,否则把newNode链接//在l节点的后面
if (l == null)
first = newNode;
else
l.next = newNode;
//链表的元素个数增加1
size++;
//modCount是链表发生结构性修改的次数(结构性修改是指发生添加或者删除操作)
modCount++;
}
可以看出,插入一个节点非常快,直接找到该位置的节点,修改节点的前驱以及后继的引用即可。
get方法
public E get(int index) {
//检查index是否合法
checkElementIndex(index);
//如果合法就返回该节点位置的值
return node(index).item;
}
//获取index位置上的节点
Node<E> node(int index) {
//断言index在链表中
// assert isElementIndex(index);
//从第一个节点开始寻找直到index位置,然后返回index//位置的节点
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//从最后一个节点开始往前寻找节点
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//检查index值的合法性
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//判断index是否存在于链表中
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
可以看出获取index节点的值要从头或尾遍历链表,当数据量很大的时候,效率无疑是低下的。
remove方法
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
//保存x节点的值
final E element = x.item;
//保存x节点的后继
final Node<E> next = x.next;
//保存x节点的前驱
final Node<E> prev = x.prev;
//如果前驱为null,说明要移除的是第一个节点,把First指向下一个节点就行
if (prev == null) {
first = next;
} else {//否则,把x节点前驱的后继指向x的后继,并把x的前驱设置为null
prev.next = next;
x.prev = null;
}
//如果后继为null则要移除的是最后一个节点,则把last的引用指向x节点的前驱就ok
if (next == null) {
last = prev;
} else {//否则,把x节点的后继的前驱设置为x节点的前驱,并x节点的后继设为null
next.prev = prev;
x.next = null;
}
//把x节点的值设为null,这样x就没有任何引用了,gc处理
x.item = null;
//把链表的size减少1
size--;
//结构性修改的次数增加1
modCount++;
//返回x节点的值,在移除之前已经保存在element中了
return element;
}
5、ArrayList、LinkedList和Vector 的总结
|—>List:列表,元素是有序的(元素带角标索引),可以有重复元素,可以有null元素。
|—>ArrayList(JDK1.2):底层的数据结构是数组数据结构,特点是查询速度快(因为带角标),但是增删速度稍慢,因为当元素多时,增删一个元素则所有元素的角标都得改变,线程不同步。默认长度是10,当超过长度时,按50%延长集合长度。
|—>LinkedList(JDK1.2):底层数据结构式链表数据结构(即后面一个元素记录前一个),
特点:查询速度慢,因为每个元素只知道前面一个元素,但增删速度快。
因为元素再多,增删一个,只要让其前后的元素重新相连即可。线程是不同步的。
|—>Vector(JDK1.0):底层数据结构是数组数据结构.特点是查询和增删速度都很慢。
默认长度是10,当超过长度时,按100%延长集合长度。线程同步。
(Vector功能跟ArrayList功能一模一样,已被ArrayList替代)
List使用注意
|—>ArrayList:
ArrayList是基于数组实现的,是一个动态数组,其容量能够自动增长 ArrayList不是线程安全的,只能用在单线程环境下,多线程环境需要使用Collections同步方法。Collections.synchronizedList(List l)返回一个线程安全的ArrayList。如果是读写比例比较大的话,则可以考虑CopyOnwriteArrayList。
- 默认容量是10
- ArrayList每次增加元素的时候,都需要调用ensureCapacity方法来确保足够的容量。当容量不足的时候,就设置新的容量为旧的的容量的1.5倍加1,如果设置的容量仍然不够,那么直接设置为传入的参数,而后用Arrays.copyOf方法将元素拷贝到新的数组。建议:在能够实现确定元素数量的情况下使用ArrayList,否则使用LinkedList。
- Arrays.copy()方法在方法的内部又创建了一个长度等长的数组,调用System.arraycopy方法完成新数组元素的复制。该方法的实际上调用native方法中C的memmove函数,在复制大数组的时候强烈建议使用该方法进行数组的复制。效率高。
- ArrayList是基于数组实现的,支持随机访问,查找效率高,但是插入删除效率低。
- ArrayList一般应用于查询较多但插入以及删除较少情况,如果插入以及从删除较多则建议使用LinkedList。
(1)当往ArrayList里面存入元素没什么要求时,即只要求有序就行时;
(2)当往ArrayList里面存入元素要求不重复时,比如存入学生对象,当同名同姓时,视为同一个人,则不往里面存储。则定义学生对象时,需复写equals方法
public boolean equals(Object obj)
{
if(!(obj instanceof Student))
return false;
Student stu = (Student)obj;
return this.name.equals(stu.name)&&this.age==stu.age;
}
则往ArrayList集合通过add存入学生对象时,集合底层自己会调用学生类的equals方法,判断重复学生则不存入。所以一般情况下我们重写equals()方法的时候都要去重写hashCode()方法。
注:对于List集合,无论是add、contains、还是remove方法,判断元素是否相同,都是通过复写equals方法来判断!
|—>LinkedList
LinkedList是基于双向循环链表实现的,除了可以当做链表来操作外,还可以当做栈、队列和双端队列使用。同样是非线程安全的。
- 基于双端循环链表,并且头节点不存放数据。
- 在查找和删除元素的时候,分为元素null和不为null进行处理,允许元素为空。
- 不存在容量不足的问题。
- Entry entry(int index)方法返回制定位置处的节点,使用加速动作。源码中先将index与长度size的一半(size>> 2)比较,如果index更小,那么就从位置0开始遍历到inde处,否则从size位置往前遍历,这样可以减少一部分不必要的遍历。实际上提高的效率有限。
- LinkedList是基于链表实现的,插入删除效率比较高,查找效率低。
(1)LinkLedist的特有方法:
boolean offerFirst(E e) 在此列表的开头插入指定的元素。
boolean offerLast(E e) 在此列表末尾插入指定的元素。
E peekFirst() 获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。
E peekLast() 获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。
E pollFirst() 获取并移除此列表的第一个元素;如果此列表为空,则返回 null。
E pollLast() 获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
(2)通过LinkLedist的特有方法,可以实现某些数据特殊方式的存取,比如堆栈和队列。
一般情况下,使用哪种List接口下的实现类呢?
- 如果要求增删快,考虑使用LinkedList。
- 如果要求查询快,考虑使用ArrayList。
- 如果要求线程安全,考虑使用Vector。
至此JAVA集合框架的List已经讲完,剩下的部分放在下一章节进行总结。
本人能力有限,若有文中有错误,希望指正,谢谢。