GANFuzz:A GAN-based industrial network protocol fuzzing framework
GANFuzz:A GAN-based industrial network protocol fuzzing framework
1.简介
1.GANFuzz,提出了一种新的测试用例生成方法,并在此基础上构建了一个模糊框架。
2.为了提高代码覆盖率和测试深度,提出了三种从不同维度对协议消息进行分类的聚类策略,利用这三种策略,所学习的生成模型可以生成更为多样化和格式良好的测试用例。
3.在实验中,使用GANFuzz原型测试了几个Modbus-TCP模拟器,成功地揭示了一些新的缺陷和已知的问题。
2.背景知识
GAN
RNN作为generator
CNN作为discriminator
3.方法
3.1 步骤
1.对msg进行聚类。在给定一个真实的协议msg集作为训练数据的情况下,我们采用三种聚类策略来提供三种方法来对数据进行分类。对于每一种策略,我们所关注的特征和功能w.r.t协议消息是不同的。它允许我们从不同的维度进行模糊处理。它有助于提高代码覆盖率和测试深度。
2.学习协议语法。我们使用生成对抗网络和SeqGan算法对将协议语法学习问题进行建模为估计生成模型的过程。通过深度学习训练,生成模型从真实的协议消息中自动揭示协议语法。
3.生成测试用例。学习的生成模型能够生成类似于真实协议消息的序列。利用生成模型可以生成模糊测试用例。
3.2 聚类msg
- NoClustering:只产生一个聚类,试图在一个生成模型中学习所有消息类型的语法。这很困难,因为属于不同类的协议消息在长度和结构上可能会有很大的差异。因此,它训练出了最粗糙的生成模型,此学习模型生成的消息格式可能不正确,被测系统可能会拒绝绝大多数消息。尽管这种策略有缺点,但它仍然值得执行,与其他两个模型相比最多样化的测试用例,代码覆盖率高。
- SameLengthClustering:按消息长度对消息进行聚类。首先,将相同长度的数据分到同一组中。然后,其数据量小于给定阈值(例如2000)的组被合并到较长的相邻组,而组包含的数据多于阈值的组保持不变。这种聚类策略看起来很粗糙,但对于许多inp在许多情况下确实是有效和简洁的,inp相同消息类型的长度是相似或相同的。与NoClustering策略相比,该策略能够更好地学习协议语法,从而获得更好的测试深度。
- AdvancedClustering:首先构建消息的字符集,再把字符映射到整数。然后将每条消息转换为矢量表示,其中每个字符由相应的整数表示。之后,通过最大整数数除法来对向量进行归一化。最后,以欧几里德距离为相似性度量,使用k-means聚类算法对向量进行分类。与其他两种聚类策略相比,该聚类策略提供了更合理的消息划分,可以应用于更一般的情况。使用这种策略,更有可能将具有相同功能的消息聚集在一起,这使我们能够分别处理每种消息类型的语法,以便我们的生成模型能够更好地理解协议语法。因此,我们倾向于获得最完整的测试数据。由于这些优点,更有可能挖掘出严重的错误并获得最佳的测试深度。另外,为了提高聚类效率,我们使用了CUDA并行编程。
3.3 学习协议语法
3.3.1 用GAN进行协议语法学习建模
给定一组协议消息,把每个消息都可以看作是来自样本结果的未知分布函数Qm。由此,协议文法的学习问题转化为求解分布函数Qm的问题。
为了求解Qm函数,我们训练生成模型Gθ来产生新的消息,而训练判别模型Dφ作为分类器来区分生成的消息和实际的消息,其中θ,φ是生成器和鉴别器的参数。Qm可以通过适当地训练GAN来近似,直到生成器能够生成与真实消息非常相似的数据。
然而,由于协议消息是离散数据,不可微分,因此在训练过程中不能直接应用反向传播。为了解决这个问题,我们使用Seq-Gan算法,它使用强化学习技术来更新生成器的参数,而不是从鉴别器直接反向传播到生成器。

图1:应用GAN来模拟INPs的语法学习问题,其中G表示生成器,D表示鉴别器。$x_i$,$y_i $是集合V中的字符,这些字符串,如$x_1x_2x_3…x_{42}$和$y_1y_2y_3…y_{43}$分别表示真实的消息和生成的消息。生成器被建模为一个随机决策过程,其中状态是到目前为止生成的消息片段,而动作是下一个要生成的字符。生成器使用来自鉴别器的rewards更新其参数。奖励是概率值$p^n_y$,这表示鉴别器将假消息视为真实消息的可能性有多大。rewards来自两方面。一个是来自完全生成的消息,其奖励是鉴别器的输出,另一个是来自中间令牌,其奖励是通过使用带有推出策略的蒙特卡罗搜索从鉴别器获得的。采用Policy gradient方法对带rewards的生成器参数进行更新。
一旦生成器更新,就可以改进鉴别器了。我们使用从生成器生成的假消息和真实消息作为鉴别器的训练数据。我们训练鉴别器以最大化真实数据和生成数据被正确分类的概率。
综上所述,通过采用GAN和SeqGan算法,我们可以对上述协议语法学习问题进行建模。
3.3.2 确定模型
在进行实际的模型训练之前,我们必须先确定GAN的两个组成部分。在我们的设置中,我们使用RNN作为生成器,LSTM作为cell,CNN作为判别模型。CNN和RNN的结构细节应根据协议消息的结构复杂度来确定。通常,协议消息越长,RNN模型应该包含的隐藏状态越多,CNN模型中可能会添加更多的卷积层。在我们的实验中,RNN由一个嵌入层和一个包含32个隐藏状态的LSTM层组成,CNN由一个嵌入层、卷积层、max池和softmax层组成。
3.3.3 训练模型
由于我们要求训练数据长度相等,为了保持消息的完整性,我们首先计算最大消息长度,然后使用不包含在字符集V中的特殊字符将短于最大长度的消息填充到最大长度。然后,将训练数据转化为数值表示。
训练分三步进行。首先,在真实的消息数据集上对多次epoch的生成器进行预训练。epoch是指对训练数据集中的所有协议消息进行迭代。然后,我们使用预先训练的生成器生成与训练数据集相同数量的数据。这些生成的数据和真实的消息一起被用以预先训练判别器。在预训练后,我们交替训练判别器和生成器,即每次训练完一次epoch的生成模型后,我们就开始训练多次epoch的判别模型。我们重复这个过程,直到生成模型能够创建与真实消息非常相似的数据。
一般来说,训练GAN的目的是估计能够产生尽可能接近原始数据的生成模型。但在这项工作中,由于学习的最终目的是执行模糊测试,我们不仅要得到最佳的生成模型,还要得到半好的生成模型。不同的模型对协议语法有不同程度的理解,可以生成不同相似度的测试数据,增加了测试用例的随机性,增加了测试用例的多样性,从而提高了模糊结果。为此,我们将交替过程重复不同的时间(例如,5、10、15、20次)。
通过这一对抗性训练过程,我们可以获得能够生成类似于协议消息的序列的生成模型。换言之,学习的生成函数$G_θ$接近于分布函数$Q_m$,这意味着我们的学习模型很好地掌握了协议语法。
3.4 生成测试用例
到目前为止,对于每一种聚类策略,我们都得到了不同程度地覆盖语法的生成模型。我们准备使用学习的生成模型来生成新的数据,这些数据是我们方法中的测试用例。通过使用RNN,我们可以学习输入序列的条件分布。因此,为了生成新的数据,我们需要首先给出一个前缀字符$x_1$,然后查询条件分布来采样下一个token,并重复这个过程直到达到最大长度。一旦有了生成模型,就可以生成任意多的新序列。
4. FUZZING框架结构
GANFuzz,工业网络协议模糊化框架。
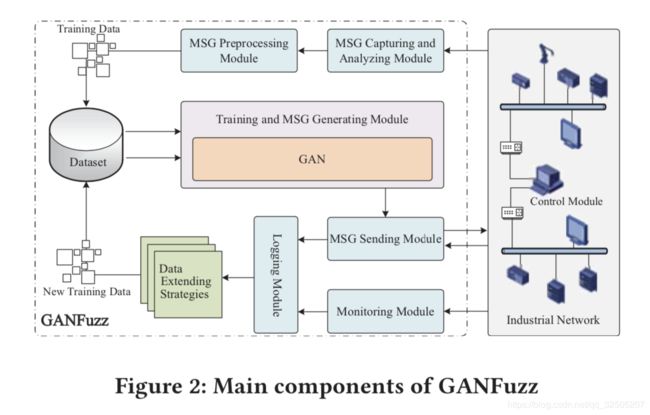
如图2所示,GAN-Fuzz由消息捕获和分析模块(MCAM)、消息预处理模块(MPM)、训练和消息生成模块(TMGM)、消息发送模块(MSM)、日志模块(LM)和监控模块(MM)组成。这些模块相互协作完成整个模糊测试过程。在运行GANFuzz时,首先启动消息捕获和分析模块准备训练数据,并收集当前工业网络中工业设备的地址信息。之后,消息预处理模块将训练数据转化为数值表示,并传递给训练和消息生成模块。然后,训练和消息生成模块启动了深度学习训练。训练后,训练和消息生成模块查询学习到的生成器生成测试数据,由消息发送模块发送到目标工业设备。同时,监控模块监督异常事件的发生,日志模块记录所有发生的事件。我们详细阐述了每个组件的工作流程和实现细节如下。
- 消息捕获与分析模块(MCAM)负责收集和分析网络通信。首先,对网络流量进行实时捕获以收集通信数据。其次,MCAM从数据中提取设备地址并存储为IP地址和端口对,MSM将在测试阶段使用这些地址和端口对。第三,MCAM将消息的TCP/IP头截取出来,提取特定于协议的命令,并以每行一条消息的格式存储为文本文件。除了包捕获,另一个选项是从本地文件读取数据,包括pcap文件和文本文件。对于pcap文件,MCAM执行与捕获文件相同的分析步骤。对于文本文件,GANFuzz不打算对它们做任何事情,而是直接发送到MPM。MCAM是使用pcapy库实现的。
- MSG预处理模块(MPM)的任务是准备训练数据。首先,MPM采用Advanced Clustering策略来识别离群数据,这些离群数据将从原始数据集中删除。然后,对处理后的数据进行聚类分析。对于这三种集群策略中的每一种,GANFuzz都将结果保存在不同的目录中。最后,MPM通过将消息字符集的每个字符映射成一个唯一的整数,将这些训练数据转换成一种数值矩阵形式,对于不同的聚类结果,传递结果将保存在单独的预定义全局变量中。
- 训练与消息生成模块(TMGM)是GANFuzz的核心模块,负责深度学习训练和测试用例生成。在该模块中,我们实现了我们提出的测试用例生成方法。GANFuzz的当前原型工具提供默认的模型设置。生成器由一个嵌入层和一个包含32个隐藏状态的LSTM层组成。对于鉴别器,它由嵌入层、卷积层、max池和softmax层组成。TMGM利用反向传播算法训练GAN模型利用批大小为64的随机梯度下降来更新参数。为了避免过度拟合,我们使用了dropout和L2正则化。默认配置可以在大多数情况下直接使用。但为了更好的学习效果,建议设计具体的模型结构,并使用良好的训练环境。TMGM按照以下程序进行培训。首先,TMGM在中以数值形式加载所有训练数据,然后根据训练设置执行训练。由于培训总是需要很长的时间,并且在此期间可能会发生异常,因此TMGM会每隔一段时间自动将模型参数导出到检查点文件中,以防止浪费以前的工作。如果在训练期间出现任何异常,GANFuzz将从最近的系统检查点恢复。此外,TMGM将根据设置将模型参数转储到检查点文件。训练后,TMGM通过从不同的检查点文件中读取参数,利用不同的模型生成测试用例。所有生成的测试用例将存储在文本文件中,然后由消息发送模块读取。TMGM是使用TensorFlow开发的,TensorFlow是Google拥有的用于深度学习的开源软件库。
- 消息发送模块(MSM)负责将消息发送到工业网络并接收其返回。一方面,TMGM生成的每个测试用例都被传递给MSM。MSM通过使用MCAM获得的地址信息,用TCP/IP报头包装这些数据。另一方面,MSM接收来自工业设备的响应。测试用例发送完成后,所有的通信将被传送到日志模块。
- 监控模块(MM)监控工业网络在模糊过程中的异常情况。这主要是通过监控和分析交互数据来实现的。MM试图找出是否有任何故障和错误的表现。具体来说,MM在当前原型工具中查找三种异常,包括超时连接、超时返回和异常消息。如果发现这些异常行为的迹象,将发出警报。为了获得更好的模糊效果,还需要手动检查,因为有些异常可能在系统运行轨迹中没有直接指示,只能通过观察其运行情况来发现。
- 日志模块(LM)记录模糊化过程中发生的所有事件。一旦第一个测试用例发出,LM就被激活。然后LM按顺序写下每个测试用例及其返回。同时,LM接收来自MM的信息。MM发现的任何异常和异常都将写入日志文件。此外,聚类算法,如k-means,k-medods在LM中被用来帮助执行日志分析,帮助查找漏洞。另外,LM会挑选那些触发了系统错误或错误行为的消息,以便以后使用。
GANFuzz的一个显著特点是它包含了一个再培训阶段。这个阶段基于这样的逻辑:相似的测试输入可能触发相似的甚至更严重的问题,这有助于获取更多关于错误的信息,从而有助于错误分析。在此期间,采用数据扩展策略获得新的训练数据,包括单点变异和多点变异。单点变异是指在种子消息中随机改变一个字符,而多点变异是指同时改变多个令牌。GANFuzz对LM选择的有问题的消息执行数据扩展策略,以获得新的训练数据,并开始新一轮的训练,进一步对这些数据进行模糊化。
5. 实验
实验对象:MOD_RSSIM v8.01、Modbus Slave v3.10a和Diaslave v2.12,以及Modbus pal v1.6b(最流行的Modbus TCP模拟器)
评价指标:
- 测试输入拒绝率(TIRR):被测系统拒绝的测试用例的百分比。
- 漏洞检测能力(AoVD):
${AoVD} =\frac {100b}{n}$,其中b是产生的异常数量,n是使用的测试输入。它的直观含义是每100个测试用例中发现的异常数。
训练数据:Pymodbus生成的Modbus-TCP请求,并通过调用相应的函数进行响应。随机调用程序中的函数生成50000个请求字符串。
模型训练:使用GANFuzz的默认设置进行模型训练。我们先对生成器进行1次epoch的预训练,然后对鉴别器进行5次历元的预训练,并整体进行3次。其次,我们进行交替训练过程,每次训练生成器1次epoch,训练鉴别器5次epoch。我们通过重复5、10、15、20次交替训练来评估实验结果。
训练配置:英伟达GeForce GTX TITAN X GPU
实验结果:
1.bug
- MOD_RSSIM模拟器2个实现漏洞,偶尔会出现“找不到文件”的错误,这是因为程序没有正确处理文件操作。
- ModbusPal的图形界面崩溃,可能是由于处理图形用户界面时内存泄漏造成的。
- 除了上面提到的问题外,我们还发现了一些其他问题,由于页面限制,我们不打算在这里列出。
2.评价指标
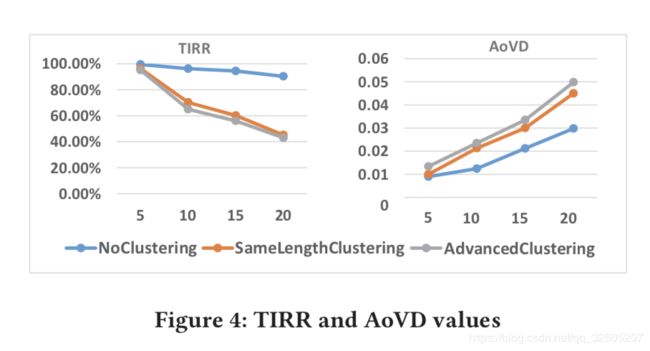
- 迭代交替训练阶段的次数越多,得到的TIRR越低,生成消息越相似
- Advanced Clutering 的性能都优于其他两种策略。此外,经过20次的训练,我们从Advanced Clutering中获得了最低的TIRR(43%),从非聚类策略中获得了最高的TIRR(90%)。最后,SameLengthClustering和advancedcludering策略也产生了类似的结果。
- 在AoVD值方面,随着交替训练次数的增加,AoVD值呈上升趋势。最佳的AoVD值来自Advanced Clutering,而最差的AoVD值来自于No Clutering。SameLength Clutering和Advanced Clutering得到了相似的结果。可以看出,我们从Advanced Clutering中得到的AoVD值为0.05,这意味着我们的方法可以在每10000个测试用例中发现5个bug。即使在No Clutering的情况下,我们也获得了0.03的AoVD值。
| Clutering | Training | Generating |
|---|---|---|
| No Clustering | 15.7h | 6.5min |
| Same Length Clustering | 36.3h | 4.6min |
| Advanced Clustering | 17.6h | 1.8min |
为了更好地比较我们的聚类策略,我们在表1中给出了20个阶段重复交替训练过程的训练时间和生成时间。我们可以看到,Advanced Clutering在训练时间和生成时间上都明显优于SameLengthClustering策略。对于NoClustering策略,虽然它在TIRR和AoVD值方面表现最差,但它的训练时间最短。
总之,尽管GANFuzz仍处于原型版本中,但它能够揭示INPs实现中的错误。我们获得的良好的TIRR和AoVD值也证明了我们方法的潜力和有效性。此外,发现的错误的多样性表明生成的测试用例是多样的,并且结构良好,这表明我们在3.2节中提出的聚类策略能够在实际中获得良好的代码覆盖率和测试深度。如前所述,Advanced Clutering优于其他两种策略。对于SameLengthClustering,尽管它很简单,但它工作得很好。总之,这三种聚类策略都是有效的。
6.总结
本文提出了一种测试工业网络协议实现的测试用例生成方法。我们的方法通过在生成-对抗网络中训练生成模型来估计协议消息的潜在分布函数,从而学习协议语法。有了这样一个生成模型,我们就能够生成格式良好的测试用例。为了提高代码覆盖率和测试深度,我们提出了三种划分训练数据的聚类策略。在此基础上,我们提出了一个自动模糊化框架GANFuzz,它可以应用于公共或私有的工业协议,其性能优于以前的许多模糊化工具。最后,通过对Modbus-TCP协议应用的测试,对本文提出的方法进行了评价。
今后,我们的工作将朝着以下方向开展。首先,我们计划使用WGAN改进。其次,我们打算将我们的方法应用于有状态协议,例如会话初始化协议最后,我们希望为GANFuzz开发一个用户友好的界面,使其更易于使用。