基于pytorch实现语义切割的FCN、Segment(1)
1、数据集使用Pascal VOCO2012
Pacal数据集就不在过多简介,这是一个用于物体检测、语义切割的共用数据集。数据集预处理
(1)读取数据
root = '/media/josen/data/VOCdevkit/VOC2012'
image_file = 'JPEGImages'
segment_file = 'SegmentationClass'
trainfiles = '/media/josen/data/VOCdevkit/VOC2012/ImageSets/Segmentation/train.txt'
valfiles = '/media/josen/data/VOCdevkit/VOC2012/ImageSets/Segmentation/val.txt'
device = torch.device('cuda:1')
nClasses = 21
def GetFiles(train=True,Seg=True):
if train == True:
#value = np.loadtxt(trainfiles,dtype=np.int32,delimiter='\n')
getmat = pd.read_csv(trainfiles,header=None,delimiter='\t')
value = getmat.iloc[:,-1].values
else :
getmat = pd.read_csv(valfiles,header=None,delimiter='\t')
value = getmat.iloc[:,-1].values
if Seg == True:
sub_file = segment_file
tail = '.png'
else :
sub_file = image_file
tail = '.jpg'
sub = os.path.join(root,sub_file)
files = [os.path.join(sub ,str(i)+tail ) for i in value ]
return files(2)数据的处理,这里有一个处理,我们读取的Segment是一个色彩图片,需要处理一下
def pascal_palette():
palette = {( 0, 0, 0) : 0 ,
(128, 0, 0) : 1 ,
( 0, 128, 0) : 2 ,
(128, 128, 0) : 3 ,
( 0, 0, 128) : 4 ,
(128, 0, 128) : 5 ,
( 0, 128, 128) : 6 ,
(128, 128, 128) : 7 ,
( 64, 0, 0) : 8 ,
(192, 0, 0) : 9 ,
( 64, 128, 0) : 10,
(192, 128, 0) : 11,
( 64, 0, 128) : 12,
(192, 0, 128) : 13,
( 64, 128, 128) : 14,
(192, 128, 128) : 15,
( 0, 64, 0) : 16,
(128, 64, 0) : 17,
( 0, 192, 0) : 18,
(128, 192, 0) : 19,
( 0, 64, 128) : 20 }
return palettedef convert_from_color_segmentation(arr_3d):
arr_2d = np.zeros((arr_3d.shape[0], arr_3d.shape[1]), dtype=np.uint8)
palette = pascal_palette()
for c, i in palette.items():
m = np.all(arr_3d == np.array(c).reshape(1, 1, 3), axis=2)
arr_2d[m] = i
return arr_2d(3)数据继承torch的集成对象Dataset,这是比较简单版本,数据augment请加后面
class GetParasetData(Dataset):
def __init__(self,nclasses=21,size=224,train=True,transform=None):
self.image_name = GetFiles(train=train,Seg=False)
self.image_seg = GetFiles(train=train,Seg=True)
self.transform = transform
self.size = size
self.ncllasses = nclasses
self.len = len(self.image_name)
def __getitem__(self, index):
#img = cv2.imread(self.image_name[index],cv2.COLOR_BGR2RGB)
img = Image.open(self.image_name[index])
#img = np.transpose(img,(2,1,0))
#img = cv2.resize(img,(self.size,self.size))
seg = cv2.imread(self.image_seg[index],cv2.COLOR_BGR2RGB)
seg = cv2.resize(seg,(self.size,self.size) )
seg = convert_from_color_segmentation(seg)
#seg = seg.reshape(-1,self.size,self.size)
#seg = seg.reshape(1,self.size*self.size)
#seg = getSegmentationArr(seg,self.ncllasses,self.size,self.size)
seg = seg.astype(np.int8)
seg = torch.from_numpy(seg)
if self.transform is not None:
img = self.transform(img)
return img , seg
def __len__(self):
return len(self.image_name)
读取数据:
transform = transforms.Compose([transforms.Resize((size,size)),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])
train_data = GetParasetData(size=size,train=True,transform=transform)
train_loader = DataLoader(train_data,batch_size=12,shuffle=True,num_workers=2)
test_data = GetParasetData(size=size,train=False,transform=transform)
test_loader = DataLoader(test_data,batch_size=20,num_workers=2)2、模型建立基于ResNet50的FCN8
加载预训练模型ImageNet训练的models:
from torchvision import models
values = {
'top' : [],
'layers1':[],
'layers2':[],
'layers3':[],
'layers4':[]
}
class FCNBase(nn.Module):
def __init__(self,nClasses):
super(FCNBase,self).__init__()
self.top = nn.Sequential(
nn.Conv2d(512,4096,7,stride=1,padding=3,bias=False),
nn.Dropout(p=0.5),
nn.Conv2d(4096,1024,1,stride=1,padding=0,bias=False),
nn.Dropout(p=0.5),
nn.Conv2d(1024,nClasses,1,stride=1,padding=0,bias=False),
nn.ConvTranspose2d(nClasses,nClasses,2,stride=2,padding=0,bias=False)
)##### 20*20
for m in self.modules():
if isinstance(m,nn.Conv2d) or isinstance(m,nn.ConvTranspose2d):
nn.init.kaiming_normal_(m.weight.data)
if m.bias is not None:
m.bias.detach().zero_()
if isinstance(m,nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self,x):
y = self.top(x)
return y
class FCN8_resnet50(nn.Module):
def __init__(self,value,FCN=FCNBase):
self.values = value
self.getValues()
super(FCN8_resnet50,self).__init__()
self.top = nn.Sequential(*self.values["top"])
self.layer1 = nn.Sequential(*self.values["layers1"])
self.layer2 = nn.Sequential(*self.values["layers2"])
self.layer3 = nn.Sequential(*self.values["layers3"])
self.layer4 = nn.Sequential(*self.values["layers4"])
self.fcn = nn.Sequential(FCN(21))
self.la1 = nn.Conv2d(256,nClasses,1,stride=1,padding=0,bias=False)
nn.init.kaiming_normal_(self.la1.weight.data)
self.trans = nn.ConvTranspose2d(nClasses,nClasses,2,stride=2,padding=0,bias=False)
nn.init.kaiming_normal_(self.trans.weight.data)
self.la2 = nn.Conv2d(128,nClasses,1,stride=1,padding=0,bias=False)
nn.init.kaiming_normal_(self.la2.weight.data)
self.up = nn.ConvTranspose2d(nClasses,nClasses,8,stride=8,padding=0,bias=False)
nn.init.kaiming_normal_(self.up.weight.data)
def getValues(self):
model = p.models.resnet50(pretrained=True)
self.values['top'].append(model.conv1)
self.values['top'].append(model.bn1)
self.values['top'].append(model.relu)
self.values['top'].append(model.maxpool)
self.values['layers1'].append(model.layer1)
self.values['layers2'].append(model.layer2)
self.values['layers3'].append(model.layer3)
self.values['layers4'].append(model.layer4)
def forward(self,x):
x = self.top(x)
layer1 = self.layer1(x)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
x = self.fcn(layer4)
y = self.la1(layer3)
x = y + x
x = self.trans(x)
y = self.la2(layer2)
x = y+x
x = self.up(x)
return x
3、loss
关于loss这里以简单的多分类损失函数,标签label类型要为long,这是要值得注意的:
cost = nn.CrossEntropyLoss(weight=None,ignore_index=255,reduction='mean')采用SGD进行优化:
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.9,weight_decay=1e-5)
#动态修改lr
def adjust_lr(optimizer,epoch):
if epoch ==20 :
lr = 0.001
for param_gram in optimizer.param_groups:
param_gram["lr"] = lr
elif epoch ==40:
lr = 0.0001
for param_gram in optimizer.param_groups:
param_gram["lr"] = lr
elif epoch == 60:
lr = 0.00001
for param_gram in optimizer.param_groups:
param_gram["lr"] = lr4、训练与评价指标:
我训练是将其记录在tensorboardX中的,没有在打印出来,这是print的IO操作其实很花费训练时间,
writer = SummaryWriter("./data/run_fcn",comment='FCN')
# 记录下它的损失和验证
writer.add_scalar("loss",loss,global_step=i)
for param_gram in optimizer.param_groups:
lr = param_gram["lr"]
writer.add_scalar("optimizer",lr,global_step=i)MeanIoU与PixelACC
def batch_pix_accuracy(output, target):
_, predict = torch.max(output, 1)
predict = predict.int() + 1
target = target.int() + 1
pixel_labeled = (target > 0).sum()
pixel_correct = ((predict == target)*(target > 0)).sum()
assert pixel_correct <= pixel_labeled, "Correct area should be smaller than Labeled"
return pixel_correct.cpu().numpy(), pixel_labeled.cpu().numpy()
def batch_intersection_union(output, target, num_class):
_, predict = torch.max(output, 1)
predict = predict + 1
target = target + 1
predict = predict * (target > 0).long()
intersection = predict * (predict == target).long()
area_inter = torch.histc(intersection.float(), bins=num_class, max=num_class, min=1)
area_pred = torch.histc(predict.float(), bins=num_class, max=num_class, min=1)
area_lab = torch.histc(target.float(), bins=num_class, max=num_class, min=1)
area_union = area_pred + area_lab - area_inter
assert (area_inter <= area_union).all(), "Intersection area should be smaller than Union area"
return area_inter.cpu().numpy(), area_union.cpu().numpy()
def eval_metrics(output, target, num_classes):
correct, labeled = batch_pix_accuracy(output.data, target)
inter, union = batch_intersection_union(output.data, target, num_classes)
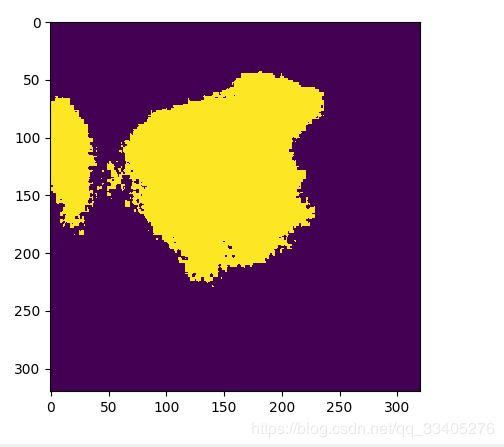
return [np.round(correct, 5), np.round(labeled, 5), np.round(inter, 5), np.round(union, 5)]5、实验测试效果: