Hadoop2.7.6集群搭建
首先,搭建的准备工作:Linux(CentOS)、xshell、至少8G内存。
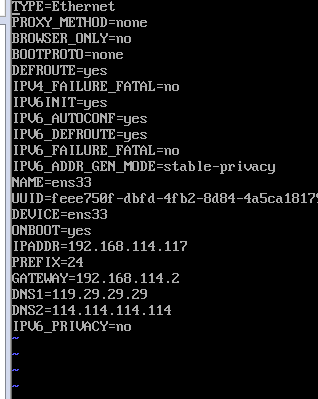
创建几个虚拟机,一主多从,每一个创建的时候,在最后安装前的设置里面,设置网络和主机名的两个地方,一个是IPv4那里,设置好IP地址,端口号和网关;还有一个是在常规那里勾选上第一个。每一个创建完,都要检测是否能够联网。同时检查一下网卡设置,命令为:vi /etc/sysconfig/network-scripts/ifcfg-ens33
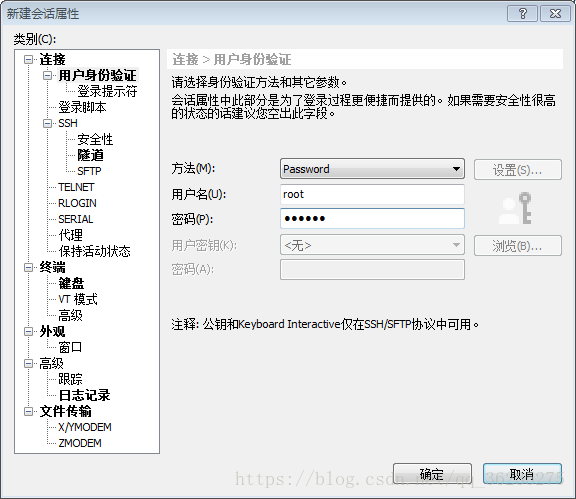
接着在xshell中连接虚拟机,连接成功后,就再也不用管虚拟机了,开在那边就好。创建新的连接,常规设置名称、主机名,还有用户身份验证和虚拟机该用户保持一致。
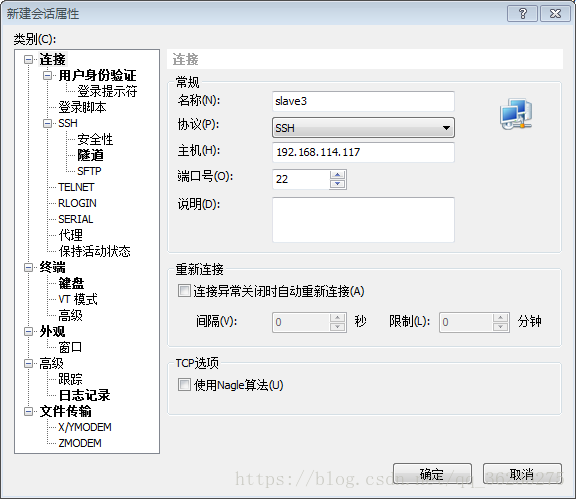
连接后,出现如下图情况,即为连接成功。

以上这些基本准备工作做完后,接下来就开始正式的介绍集群搭建了。
一、首先安装一些方便集群搭建的一些安装包:
1.第一个是openssh的安装,因为主从节点之间需要文件的传递,以及文件的上传等,都依赖这个工具
[root@slave3 ~]# yum -y install openssh-clients2.第二个是文件上传和下载的工具,可以在xshell内部直接下载外部资源,其实这里下载的资源是CentOS一个插件库里面的资源
[root@slave3 ~]# yum -y install lrzsz3.传输文件的时候, 可能会遭遇到系统防火墙的干扰,因此我们需要关闭防火墙
[root@slave3 ~]# systemctl status firewalld //查看防火墙状态[root@slave3 ~]# systemctl stop firewalld //关闭防火墙[root@slave3 ~]# systemctl disable firewalld //禁用防火墙,防止自动开启
还有一些小功能的,需要的自己百度安装:例如时间同步工具ntp、网络资源下载工具wget等
二、配置SSH免密登陆
以下操作,多台主机一起执行:
首先修改hosts文件,作用相当于一个别名
[root@master ~]# vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.114.114 master
192.168.114.115 slave1
192.168.114.116 slave2
192.168.114.117 slave3然后在各个主机都创建一个.ssh文件夹
[root@slave3 ~]# ssh slave3 //别的主机同理,改个名字即可
[root@slave3 ~]# cd ~/.ssh //进入ssh目录[root@slave3 .ssh]# ssh-keygen -t rsa -P '' //产生公钥和私钥接着一直按回车,接着各个主机都有了私钥和公钥。接着将各个主机的公钥放到authorized_keys文件中
[root@slave3 .ssh]# cp id_rsa.pub authorized_keys
然后将各个主机的公钥追加到master中
cat ~/.ssh/id_rsa.pub | ssh root@master 'cat >> ~/.ssh/authorized_keys'最后连接测试各个主机之间的联通。
[root@master ~]# ssh master
[root@master ~]# ssh slave1
[root@slave1 ~]# ssh master
[root@master ~]# ssh slave2
[root@slave2 ~]# ssh master
[root@master ~]# ssh slave3
[root@slave3 ~]# ssh master
三、Java环境的安装和配置(所有主机同样操作)
下载jdk 下载地址:http://www.oracle.com/technetwork/java/javase/archive139210.html
1.下载安装前,首先检查虚拟机系统内是否有残留的jdk等,如果有,要先清理,再安装
2.安装jdk
①创建两个目录,为了之后存放jdk和hadoop的安装包做准备
[root@master ~]# mkdir -p /opt/SoftWare/Java/
[root@master ~]# mkdir -p /opt/SoftWare/Hadoop/②上传jdk安装包,并解压
[root@master ~]# cd /opt/SoftWare/Java //使用rz命令从windows主机上传jdk压缩包到master节点
[root@master Java]# rz
[root@master Java]# tar ‐zxvf jdk‐8u172‐linux‐x64.tar.gz
③接下来开始配置环境变量
[root@master Java]# vi /etc/profile //写在该配置文件最后
export JAVA_HOME=/opt/SoftWare/Java/jdk1.8.0_172
export JRE_HOME=/opt/SoftWare/Java/jdk1.8.0_172/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
④配置完千万要source一下,否贼你的配置将不起效果,出现以下内容,则说明你的配置正确了。
[root@master Java]# source /etc/profile
[root@master Java]# java ‐version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
四、Hadoop的安装和配置(仅在master执行,后面会远程复制给其他从节点)
①上传hadoop安装包,并解压
[root@slave3 Hadoop]# tar -zxvf hadoop-2.7.6.tar.gz
②同样,创建几个目录,方便存储信息,不过这里即使你不创建,系统也会自动创建
[root@slave3 hadoop-2.7.6]# mkdir tmp
[root@slave3 hadoop-2.7.6]# mkdir logs
[root@slave3 hadoop-2.7.6]# mkdir -p hdfs/name
[root@slave3 hadoop-2.7.6]# mkdir -p hdfs/data③接下来就是关于hadoop的配置文件的修改了,将这两个路径下的文件的JAVA_HOME都改成如下路径
[root@slave1 hadoop]# vi hadoop-env.sh
[root@slave3 hadoop]# vi yarn-env.sh
export JAVA_HOME=/opt/SoftWare/Java/jdk1.8.0_172
④编辑slaves,将master的所有节点都写在这里,如果下次还有节点加入,直接添加,添加详情如下
[root@slave3 hadoop]# vi slaves
slave1
slave2
slave3 ⑤修改core-site.xml文件,这是核心文件core,很重要
[root@slave3 hadoop-2.7.6]# vi etc/hadoop/core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/opt/SoftWare/Hadoop/hadoop-2.7.6/tmp
io.file.buffer.size
131702
⑥修改hdfs-site.xml文件,这是HDFS的配置文件
[root@slave3 hadoop-2.7.6]# vi etc/hadoop/hdfs-site.xml
dfs.namenode.name.dir
file:/opt/SoftWare/Hadoop/hadoop-2.7.6/hdfs/name
dfs.datanode.data.dir
file:/opt/SoftWare/Hadoop/hadoop-2.7.6/hdfs/data
dfs.replication
2
dfs.namenode.secondary.http-address
master:50090
dfs.namenode.secondary.https-address
192.168.10.250:50091
dfs.webhdfs.enabled
true
⑦修改yarn-site.xml文件
[root@slave3 hadoop-2.7.6]# vi etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
yarn.nodemanager.resource.memory-mb
2048
⑧修改mapred-site.xml文件,需要复制创建
[root@slave3 hadoop-2.7.6]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[root@slave3 hadoop-2.7.6]# vim etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19880
之前说过,以上操作只要在master里面操作即可,然后复制到各个从节点,使用以下命令,其他类似
[root@master hadoop‐2.7.6]# scp ‐r /opt/SoftWare/Hadoop root@slave3:/opt/SoftWare/
⑨修改环境变量,每一个节点都需要添加以下hadoop的环境变量
[root@master hadoop‐2.7.6]# vi /etc/profile
#添加以下内容
export HADOOP_HOME=/opt/SoftWare/Hadoop/hadoop‐2.7.6
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@master hadoop‐2.7.6]# source /etc/profile //上文讲过,修改环境变量需要source 或者.+空格+/etc/profile
⑩格式化Hadoop,当你格式化后能够看到下面的successfully formatted时,即代表格式化成功了
[root@master hadoop‐2.7.5]# bin/hdfs namenode ‐format
18/07/27 22:54:44 INFO util.GSet: capacity = 2^15 = 32768 entries
18/07/27 22:54:44 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1867261898-192.168.114.117-1532703284780
18/07/27 22:54:44 INFO common.Storage: Storage directory /opt/SoftWare/Hadoop/hadoop-2.7.6/hdfs/name has been successfully formatted.
18/07/27 22:54:45 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/SoftWare/Hadoop/hadoop-2.7.6/hdfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/07/27 22:54:45 INFO namenode.FSImageFormatProtobuf: Image file /opt/SoftWare/Hadoop/hadoop-2.7.6/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
18/07/27 22:54:45 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/07/27 22:54:45 INFO util.ExitUtil: Exiting with status 0
18/07/27 22:54:45 INFO namenode.NameNode: SHUTDOWN_MSG:
接着就是令人兴奋地时候了,可以启动集群啦!!
方法一:sbin/start‐dfs.sh
方法二:start‐all.sh //以前的,现在不推荐使用
#然后启动YARN
[root@master hadoop‐2.7.5]# sbin/start‐yarn.sh
显示如下数据,则表明成功一半了,但距离成功就一步之遥了,输入jps查看状态,如果如下就几乎成功了,还需要去检测你的50070和8088网页是否可以打开。如果都打开了,那恭喜你!成功了!!
[root@master hadoop‐2.7.6]# jps
13696 NameNode
14037 ResourceManager
14229 Jps
13887 SecondaryNameNode