R语言-kNN算法进行乳腺癌诊断
完整代码如下:
wbdc<-read.csv("/Users/wenfeng/Desktop/R&ML/机器学习和R语言/机器学习实验6 KNN/wisc_bc_data.csv",stringsAsFactors = FALSE)
str(wbdc)
wbdc<-wbdc[-1]
table(wbdc$diagnosis)
wbdc$diagnosis<-factor(wbdc$diagnosis,levels = c("B","M"),labels = c("Benign","Malignant"))
round(prop.table(table(wbdc$diagnosis))*100,digits = 1)
summary(wbdc[c("radius_mean","area_mean","smoothness_mean")])
#标准化min-max
normalize<-function(x){
return((x-min(x))/(max(x)-min(x)))
}
normalize(c(1,2,3,4,5))
wbdc_n<-as.data.frame(lapply(wbdc[2:31],normalize))
summary(wbdc_n$area_mean)
#数据准备
wbdc_train<-wbdc_n[1:469,]
wbdc_test<-wbdc_n[470:569,]
wbdc_train_label<-wbdc[1:469,1]
wbdc_test_label<-wbdc[470:569,1]
#训练模型
library(class)
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=21)
library(gmodels)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
#z-score标准化
wbdc_z<-as.data.frame(scale(wbdc[-1]))
summary(wbdc_z$area_mean)
#数据准备
wbdc_train<-wbdc_z[1:469,]
wbdc_test<-wbdc_z[470:569,]
wbdc_train_label<-wbdc[1:469,1]
wbdc_test_label<-wbdc[470:569,1]
#训练模型
library(class)
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=21)
library(gmodels)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
#改变k值
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=10)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=5)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
一、数据处理
wbdc<-read.csv("/Users/wenfeng/Desktop/R&ML/机器学习和R语言/机器学习实验6 KNN/wisc_bc_data.csv",stringsAsFactors = FALSE)
str(wbdc)
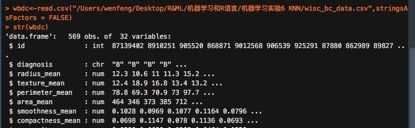
wbdc<-wbdc[-1]
table(wbdc d i a g n o s i s ) w b d c diagnosis) wbdc diagnosis)wbdcdiagnosis<-factor(wbdc d i a g n o s i s , l e v e l s = c ( " B " , " M " ) , l a b e l s = c ( " B e n i g n " , " M a l i g n a n t " ) ) r o u n d ( p r o p . t a b l e ( t a b l e ( w b d c diagnosis,levels = c("B","M"),labels = c("Benign","Malignant")) round(prop.table(table(wbdc diagnosis,levels=c("B","M"),labels=c("Benign","Malignant"))round(prop.table(table(wbdcdiagnosis))*100,digits = 1)
summary(wbdc[c(“radius_mean”,“area_mean”,“smoothness_mean”)])

#标准化min-max
normalize<-function(x){
return((x-min(x))/(max(x)-min(x)))
}
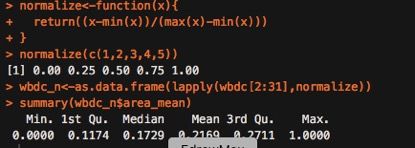
normalize(c(1,2,3,4,5))
wbdc_n<-as.data.frame(lapply(wbdc[2:31],normalize))
summary(wbdc_n$area_mean)
二、建立模型
#数据准备
wbdc_train<-wbdc_n[1:469,]
wbdc_test<-wbdc_n[470:569,]
wbdc_train_label<-wbdc[1:469,1]
wbdc_test_label<-wbdc[470:569,1]
#训练模型
library(class)
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=21)
library(gmodels)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
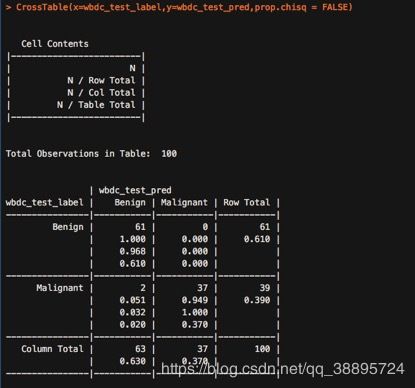
由上图可知:由61个良性患者,knn算法也将其正确预测为良性;而将2个恶性错误地预测为良性。100个肿块,有两个被错误分类。我们可以继续采用其他方法,提高模型的性能并减少错误分类值的数量。
三、提高模型性能
1.z-score标准化
#z-score标准化
wbdc_z<-as.data.frame(scale(wbdc[-1]))
summary(wbdc_z$area_mean)
#数据准备
wbdc_train<-wbdc_z[1:469,]
wbdc_test<-wbdc_z[470:569,]
wbdc_train_label<-wbdc[1:469,1]
wbdc_test_label<-wbdc[470:569,1]
#训练模型
library(class)
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=21)
library(gmodels)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
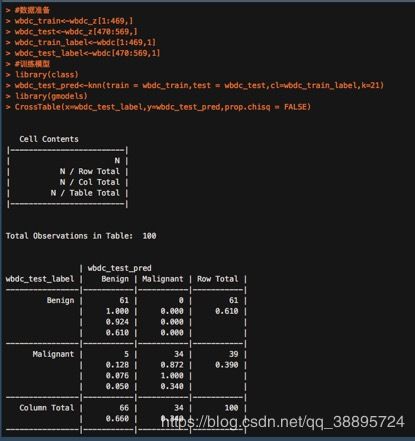
由上图可知,由5个恶性肿块被错误的划分为良性的,比min-max标准化后的建模效果差
2.改变k值(在z-score基础上)
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=10)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
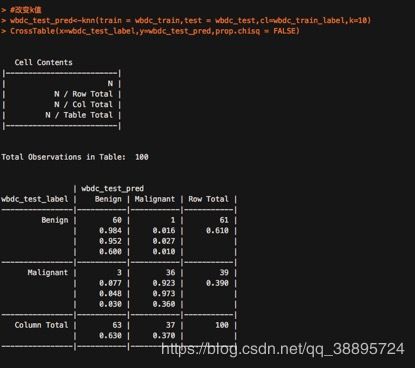
这种情况下,虽然假阴性的情况较k=21有所提高,但有1个被错误的判定为恶性
wbdc_test_pred<-knn(train = wbdc_train,test = wbdc_test,cl=wbdc_train_label,k=5)
CrossTable(x=wbdc_test_label,y=wbdc_test_pred,prop.chisq = FALSE)
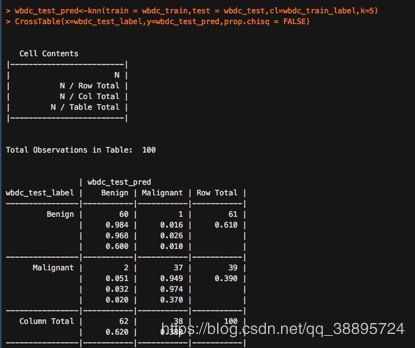
这种情况下,虽然假阳性的情况与k=10一样,但是假阴性的情况有所好转。