Xpath最初被设计用来搜寻XML文档,但它同样适用于HTML文档的搜索。通过简洁明了的路径选择表达式,它提供了强大的选择功能;同时得益于其内置的丰富的函数,它可以匹配和处理字符串、数值、时间等数据格式,几乎所有节点我们都可以通过Xpath来定位。
在Python中,lxml库为我们提供了完整的Xpath选择器,今天我们就用它来学习Xpath的使用,我们的目标是用最少的时间来掌握使用频率最高的核心技能,而这些核心技能基本上可以满足我们网页抓取的需求。
毕竟我们不是单独在使用Xpath,在Python中,很多数据处理和匹配的工作我们可以用更加“Python”、更加通用的方法来解决,没必要为了5%的使用而花费数倍的时间。
我们都知道,在很多领域里,从0到80分只需要花费很少的时间,从80分到95分则可能会花费上一阶段的数倍时间,至于从95分往上,每一分的提高都可能需要巨大的时间成本。我们需要权衡最初的学习诉求、收获和时间成本的匹配度等,以判断我们要到达哪一个水平,并规划出对应的学习方案。
我学习爬虫的目的并不是成为一个精通网络爬虫的大师,而是将它作为一个工具,用来帮助我更好地进行数据挖掘分析的工作。因此,在学习过程中会尽可能地功力,力求以最少的时间掌握最核心的技能。Xpath简直是针对这种学习思路设计的,因为它太容易上手了,核心功能只需要十分钟就可以熟练掌握,而那多达上百的函数对我们来说可能一辈子都用不到几回。
欢迎大家关注我的个人博客【数洞】 【备用站】
一、Xpath常用规则
下表是最常用的Xpath规则,绝大多数的Xpath表达式都由它们构成。
| 表达式 | 描述 |
|---|---|
nodename |
选取此节点的所有子节点 |
/ |
从当前节点直接选取子节点 |
// |
从当前节点选取所有子孙节点 |
. |
选取当前节点 |
.. |
选取当前节点的父节点 |
@ |
选取属性 |
二、抓取赵雷热门作品页面
单纯的罗列简直是耍流氓,实战才是硬道理。正如标题所言,今天我们就使用Xpath来解析网易云音乐的歌手页面。我个人很喜欢赵雷,那我们就先尝试解析一下赵雷的热门作品。
网易云音乐抓取难度较低,没有乱七八糟的验证,抓取的时候我们只需要带上header就可以成功获取我们需要的内容了。
首先,我们打开网易云音乐的首页,搜索并进入赵雷的页面。右键检查并切换到Network选项卡,刷新一下,就看到了一大串网络请求,我们要做的就是从中定位到歌曲列表所在的请求。
我们优先看document类的文件,第一个打开后通过preview可以看到这里是通用内容,包含了一些网易云音乐的信息,那么接下来我们看下边这个红框里的请求,首先请求名称里包含了artist以及一个对应的id,看起来有点像。

接下来我们单击进去看看:

我们成功看到了赵雷的热门作品列表,说明我们找对了位置。我们同样可以通过在response里搜索来确定这一请求是否是我们寻找的那一个。比如我们搜索“成都”、“南方姑娘”等,来看下我们的歌曲列表是不是在这个response中。
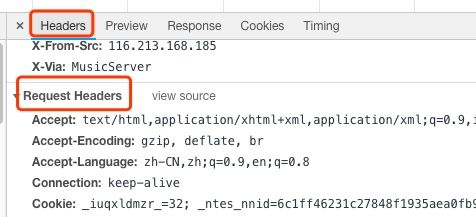
确定了请求之后,我们就需要抓取并解析了。首先我们切换到Headers选项,在General下找到Request URL作为请求连接;然后在Request Headers下找到‘User-Agent’,并将其复制下来用作模拟浏览器发起请求。


接下来我们尝试抓取页面:
import requests
url = 'https://music.163.com/artist?id=6731'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
html = requests.get(url, headers=headers)
print(html.status_code)
结果如下:
200
这说明我们的请求成功了,接下来我们看下html的内容是否符合要求:
print(html.text)
这里打印的结果太长就不贴出来了,我们可以把打印的内容和刚才那个请求返回的结果做一个比对,看是不是一样的内容。通过观察,我们发现这就是我们需要的内容。
三、解析热门作品列表
1. 构建对象
那么接下来就要解析了,解析之前,我们需要先使用lxml构建我们需要的对象:
from lxml import etree
result = etree.HTML(html.text)
print(type(result))
print(result)
输出为:
2. 子节点、子孙节点、属性过滤、文本选取
然后我们观察网页,定位到歌单位置:
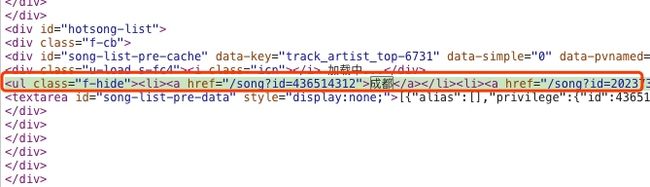
我们发现歌曲列表藏在一个class="f-hide"属性;标签;标签中又嵌套了一个标签,这个标签有个href属性,其值为每首歌的相对链接,而歌曲名称就在标签对应的文本中。
好了,接下来我们构建Xpath路径选择表达式:
song_list = result.xpath('//ul[@class="f-hide"]/li/a/text()')
print(song_list)
看下输出:
['成都', '南方姑娘', '理想', '画', '我们的时光', '少年锦时', '阿刁', '鼓楼', '三十岁的女人', '无法长大', '八十年代的歌', '十九岁', '彩虹下面', '玛丽', '让我偷偷看你', '吉姆餐厅', '朵', '静下来', '家乡', '已是两条路上的人', '未给姐姐递出的信', '北京的冬天', '孤独', '小屋', '再也不会去丽江', '再见北京', '妈妈', '梦中的哈德森', '人家', '背影', '窑上路', '浮游', '不开的唇', '开往北京的火车', '赵小雷', '往事只能回味', '爱人你在哪里', '未给姐姐递出的信 ', 'Over', '民谣', '凭什么说爱你', '逆流而上', '夏天', '米店', '飞来飞去', '朵儿 (Live版)', '何必', '塔吉汗', '月亮粑粑 (Live)']
好,我们成功解析出了歌曲列表。那么接下来我们回头看一下这个表达式:
首先,我们使用.xpath()方法来调用Xpath表达式;//ul[@class="f-hide"]代表我们选取所有拥有class="f-hide"属性的/li代表在上边返回的标签,/a同理,进一步选取子节点中的标签;/text()则是将结果中标签中的文本信息返回为一个列表。
是不是很简单?Xpath使用起来完全符合我们的直观感觉,非常人性化。
3. 父节点
那如果我想查看某个节点的父节点怎么办?很好办,使用/..即可:
temp = result.xpath('//ul[@class="f-hide"]/../@class')
print(temp)
输出为:
['u-slt f-ib']
也就是说,刚才我们定位到的class属性的值为'u-slt f-ib'。这里我们使用..选取了父节点,并使用/@选取了该节点的class属性。
4. 属性选取
关于属性的选取,我们再看一个例子:
link_list = result.xpath('//ul[@class="f-hide"]/li/a/@href')
print(link_list)
输出为:
['/song?id=436514312', '/song?id=202373', '/song?id=29567189', '/song?id=202369', '/song?id=29567193', '/song?id=29567192', '/song?id=447925059', '/song?id=447926067', '/song?id=29567191', '/song?id=437608773', '/song?id=447925066', '/song?id=530995556', '/song?id=1295824647', '/song?id=447925058', '/song?id=33166602', '/song?id=29567187', '/song?id=447926063', '/song?id=517567264', '/song?id=29567188', '/song?id=28111471', '/song?id=202368', '/song?id=29567185', '/song?id=447925063', '/song?id=29567194', '/song?id=34852810', '/song?id=447925067', '/song?id=202377', '/song?id=29567190', '/song?id=202367', '/song?id=202376', '/song?id=447926068', '/song?id=29567186', '/song?id=202370', '/song?id=202375', '/song?id=202371', '/song?id=433018045', '/song?id=433018044', '/song?id=29810320', '/song?id=202374', '/song?id=433018041', '/song?id=432792901', '/song?id=433018046', '/song?id=432792905', '/song?id=31460216', '/song?id=433018047', '/song?id=553546118', '/song?id=432792904', '/song?id=432792903', '/song?id=460628183']
这次我们没有选取歌名,而是通过标签的href属性选取了每首歌的相对链接地址。通过这一地址,我们可以与music.163.com/#一起拼接出每首歌的实际地址。
5. 属性多值情况处理
前边我们通过//ul[@class="f-hide"]尝试了按照属性进行筛选,那么当一个属性有多个取值的时候我们怎么办呢?
观察网页,有这么一个 输出为: 我们成功通过 那么还有一种常见的情况,就是假如我需要通过多个属性来定位一个标签的时候,应该怎么办呢?注意,这里是多个属性,上边一种情况是一个属性的多个取值。 针对多个属性的情况,我们可以通过and运算符来连接,Xpath支持一系列的运算符,包括 以上边这个例子来说,他有 输出为: 可以看到,由于我设置了 输出为: 我们使用 Xpath有一系列的轴选择方法,如下表所示: 这些轴选择有一些跟上边提到的方法是一样的,大部分都能通过前边提到的 好了,今天我们演示了如何通过Xpath解析网页数据,上述内容基本涵盖了爬取网页过程中的绝大多数解析需求,我们只需多加练习,能够在不同场景下灵活组合这些基本技能,就可以顺畅地从HTML文本中获取我们所需要的信息了。class属性有三个取值,假如我们想选取拥有class="sltbtn"属性的contains()函数就该出马了:
temp2 = result.xpath('//div[contains(@class, "sltbtn")]/@class')
print(temp2)
['u-btn2 u-btn2-1 sltbtn']class属性的一个取值定位到了这个标签,并选取了它的class属性的所有取值。6. 多属性过滤处理
and、or、|、加减乘除以及大小判断等。
class、data-res-type等属性,下面我们来看如何同时过滤他的两个属性值:temp3 = result.xpath('//li[@class="choose" and @data-res-type>1]/text()')
print(temp3)
['作词作品', '作曲作品']@data-res-type>1,所以出来了两条记录,因为有两个标签的@data-res-type属性的取值分别为2和3。7. 按顺序选择
best_song = result.xpath('//ul[@class="f-hide"]/li/a[1]/text()')
last_song = result.xpath('//ul[@class="f-hide"]/li/a[last()]/text()')
last_3_song = result.xpath('//ul[@class="f-hide"]/li/a[last()-2]/text()')
best_3_songs = result.xpath('//ul[@class="f-hide"]/li/a[position()<4]/text()')
print(best_song)
print(last_song)
print(last_3_song)
print(best_3_songs)
['成都'] ['月亮粑粑 (Live)'] ['何必'] ['成都', '南方姑娘', '理想'][1]选取了第一个标签,使用[last()]选取了最后一个标签,使用[last()-2]选取了倒数第三个标签,使用[position()<4]选取了前三个标签。8. 节点轴选择
轴名称
结果
ancestor
选取当前节点的所有先辈(父、祖父等)
ancestor-or-self
选取当前节点的所有先辈(父、祖父等)以及当前节点本身
attribute
选取当前节点的所有属性
child
选取当前节点的所有子元素
descendant
选取当前节点的所有后代元素(子、孙等)
descendant-or-self
选取当前节点的所有后代元素(子、孙等)以及当前节点本身
following
选取文档中当前节点的结束标签之后的所有节点
namespace
选取当前节点的所有命名空间节点
parent
选取当前节点的父节点
preceding
选取文档中当前节点的开始标签之前的所有节点
preceding-sibling
选取当前节点之前的所有同级节点
self
选取当前节点
/、//、..等组合而来。但很多情况下,直接使用这些轴会更加快捷。轴选择的使用方法如下,以刚才的父节点为例,我们将..替换为parent::*,*代表选取父节点中的所有节点,当然,事实上这里只有1个节点,不过在::之后必须要选择至少一个节点,这是语法的要求,所以我们用*作为后缀加在parent::后边。temp = result.xpath('//ul[@class="f-hide"]/parent::/@class')
print(temp)