pandas处理泰坦尼克号数据集(1)基础处理
数据集描述
Survived:0代表死亡,1代表存活
Pclass:乘客所持票类,有三种值(1,2,3)
Name:乘客姓名
Sex:乘客性别
Age:乘客年龄(有缺失)
SibSp:乘客兄弟姐妹/配偶的个数(整数值)
Parch:乘客父母/孩子的个数(整数值)
Ticket:票号(字符串)
Fare:乘客所持票的价格(浮点数,0-500不等)
Cabin:乘客所在船舱(有缺失)
Embark:乘客登船港口:S、C、Q(有缺失)
import pandas as pd
import numpy as np
titanic_df = pd.read_csv("titanic_train.csv")
titanic_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
# 查看某一列缺失值
age = titanic_df.Age
age_is_null = pd.isnull(age)
# print(age_is_null)
age_null_true = age[age_is_null]
# print(age_null_true)
age_null_count = len(age_null_true)
print(age_null_count)
177
# 求平均年龄
mean_age = sum(titanic_df.Age) / len(titanic_df.Age)
mean_age
nan
# 显然,我们必须去掉缺失值
mean_age = titanic_df['Age'][age_is_null == False]
correct_mean_age = sum(mean_age) / len(mean_age)
print(correct_mean_age)
# pandas 中内置函数
mean_age2 = titanic_df.Age.mean()
print(mean_age2)
29.69911764705882
29.69911764705882
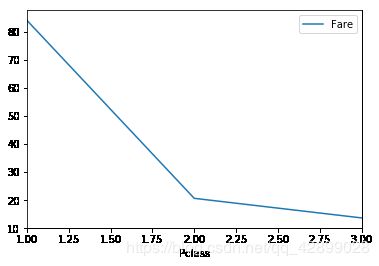
# 计算每个舱位的票价平均值
pclass = [1, 2, 3]
mean_fares_by_class = {}
for c in pclass:
pclass_rows = titanic_df[titanic_df.Pclass == c]
pclass_fares = pclass_rows.Fare.mean()
mean_fares_by_class[c] = pclass_fares
mean_fares_by_class
{1: 84.15468749999992, 2: 20.66218315217391, 3: 13.675550101832997}
# 使用数据透视表的方式计算每个舱位的票价平均值
mean_fares_by_class = titanic_df.pivot_table(
index="Pclass", values="Fare", aggfunc=np.mean)
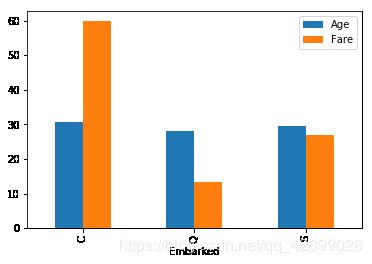
# 同理,计算多个变量之间的关系, 默认求平均值
port_stats = titanic_df.pivot_table(index="Embarked", values=["Age", "Fare"])
port_stats.plot(kind="bar")
# 指定行或列,去除缺失值
print(titanic_df.shape)
drop_na_columns = titanic_df.dropna(axis='columns')
print(drop_na_columns.shape)
new_titanic_df = titanic_df.dropna(axis=0, subset=['Age', 'Sex'])
print(new_titanic_df.shape)
(891, 12)
(891, 9)
(714, 12)
# 提取某一 “单元格” 的值
row_index_99_age = titanic_df.loc[99,'Age']
print(row_index_99_age)
34.0
# 年龄从大到小排序
new_titanic_df = titanic_df.sort_values("Age", ascending=False)
print(new_titanic_df[:10])
# 重置索引
reset_index = titanic_df.reset_index(drop=True)
print(reset_index[:10])
PassengerId Survived Pclass Name \
630 631 1 1 Barkworth, Mr. Algernon Henry Wilson
851 852 0 3 Svensson, Mr. Johan
493 494 0 1 Artagaveytia, Mr. Ramon
96 97 0 1 Goldschmidt, Mr. George B
116 117 0 3 Connors, Mr. Patrick
672 673 0 2 Mitchell, Mr. Henry Michael
745 746 0 1 Crosby, Capt. Edward Gifford
33 34 0 2 Wheadon, Mr. Edward H
54 55 0 1 Ostby, Mr. Engelhart Cornelius
280 281 0 3 Duane, Mr. Frank
Sex Age SibSp Parch Ticket Fare Cabin Embarked
630 male 80.0 0 0 27042 30.0000 A23 S
851 male 74.0 0 0 347060 7.7750 NaN S
493 male 71.0 0 0 PC 17609 49.5042 NaN C
96 male 71.0 0 0 PC 17754 34.6542 A5 C
116 male 70.5 0 0 370369 7.7500 NaN Q
672 male 70.0 0 0 C.A. 24580 10.5000 NaN S
745 male 70.0 1 1 WE/P 5735 71.0000 B22 S
33 male 66.0 0 0 C.A. 24579 10.5000 NaN S
54 male 65.0 0 1 113509 61.9792 B30 C
280 male 65.0 0 0 336439 7.7500 NaN Q
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
5 6 0 3
6 7 0 1
7 8 0 3
8 9 1 3
9 10 1 2
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
5 Moran, Mr. James male NaN 0
6 McCarthy, Mr. Timothy J male 54.0 0
7 Palsson, Master. Gosta Leonard male 2.0 3
8 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) female 27.0 0
9 Nasser, Mrs. Nicholas (Adele Achem) female 14.0 1
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
5 0 330877 8.4583 NaN Q
6 0 17463 51.8625 E46 S
7 1 349909 21.0750 NaN S
8 2 347742 11.1333 NaN S
9 0 237736 30.0708 NaN C
自定义函数使用
def row_100(column):
"""提取第100行"""
return column.iloc[99]
titanic_df.apply(row_100)
PassengerId 100
Survived 0
Pclass 2
Name Kantor, Mr. Sinai
Sex male
Age 34
SibSp 1
Parch 0
Ticket 244367
Fare 26
Cabin NaN
Embarked S
dtype: object
# 查看不含空值的列
def not_null_count(column):
column_null = pd.isnull(column)
null = column[column_null]
return len(null)
column_null_count = titanic_df.apply(not_null_count)
column_null_count
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
def which_class(row):
pclass = row['Pclass']
if pd.isnull(pclass):
return "Unknown"
elif pclass == 1:
return "First Class"
elif pclass == 2:
return "Second class"
elif pclass == 3:
return "Third Class"
classes = titanic_df.apply(which_class, axis=1)
classes
0 Third Class
1 First Class
2 Third Class
3 First Class
4 Third Class
5 Third Class
6 First Class
7 Third Class
8 Third Class
9 Second class
10 Third Class
11 First Class
12 Third Class
13 Third Class
14 Third Class
15 Second class
16 Third Class
17 Second class
18 Third Class
19 Third Class
20 Second class
21 Second class
22 Third Class
23 First Class
24 Third Class
25 Third Class
26 Third Class
27 First Class
28 Third Class
29 Third Class
...
861 Second class
862 First Class
863 Third Class
864 Second class
865 Second class
866 Second class
867 First Class
868 Third Class
869 Third Class
870 Third Class
871 First Class
872 First Class
873 Third Class
874 Second class
875 Third Class
876 Third Class
877 Third Class
878 Third Class
879 First Class
880 Second class
881 Third Class
882 Third Class
883 Second class
884 Third Class
885 Third Class
886 Second class
887 First Class
888 Third Class
889 First Class
890 Third Class
Length: 891, dtype: object
def is_minor(row):
if row["Age"] < 18:
return True
else:
return False
minors = titanic_df.apply(is_minor, axis=1)
# print(minors)
# 制作年龄标签
def generate_age_label(row):
age = row["Age"]
if pd.isnull(age):
return "unknown"
elif age < 18:
return "minor"
else:
return "adult"
age_labels = titanic_df.apply(generate_age_label, axis=1)
age_labels
0 adult
1 adult
2 adult
3 adult
4 adult
5 unknown
6 adult
7 minor
8 adult
9 minor
10 minor
11 adult
12 adult
13 adult
14 minor
15 adult
16 minor
17 unknown
18 adult
19 unknown
20 adult
21 adult
22 minor
23 adult
24 minor
25 adult
26 unknown
27 adult
28 unknown
29 unknown
...
861 adult
862 adult
863 unknown
864 adult
865 adult
866 adult
867 adult
868 unknown
869 minor
870 adult
871 adult
872 adult
873 adult
874 adult
875 minor
876 adult
877 adult
878 unknown
879 adult
880 adult
881 adult
882 adult
883 adult
884 adult
885 adult
886 adult
887 adult
888 unknown
889 adult
890 adult
Length: 891, dtype: object
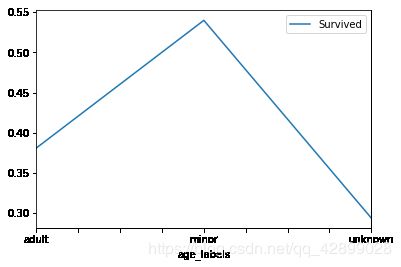
titanic_df['age_labels'] = age_labels
age_group_survival = titanic_df.pivot_table(index="age_labels", values="Survived")
age_group_survival
| Survived | |
|---|---|
| age_labels | |
| adult | 0.381032 |
| minor | 0.539823 |
| unknown | 0.293785 |
age_group_survival.plot()