数据挖掘项目1:泰坦尼克号生存率预测
泰坦尼克号生存率预测
数据来源:Kaggle数据竞赛
写这个博客的目的,之前自己做了几个数据挖掘的项目,现在整理一下,记录一下过程。也希望可以分享出来和大家交流交流。
项目的基本思路:
1.认识数据,看看数据中的类型,数据的格式,是否有缺失值之类的。
2.处理数据,处理数据中的缺失值,异常值,离群点等。
3.特征工程,一个模型好不好,和特征工程做的好不好有很大的联系。
最近在做毕业设计----高速公路事故预测,用了各种模型,神经网络,
做出来的准确率都是百分之八十五左右。所以现在又回头去弄特征工
程,希望可以提高准确率。
4.建立模型(融合模型),比较模型,选择模型。
认识数据:
先来看看数据的基本格式,这里用pandas导入为DataFrame。
train = pd.read_csv("D:/Data mining/taitannikehao/train.csv")
train.head()
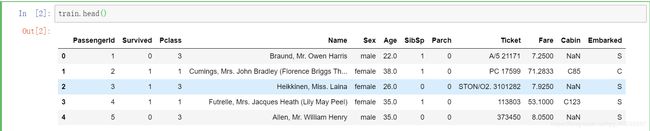
可以看到数据的特征,并且还有些有缺失值。
现在介绍下各个特征的含义:
- PassengerId => 乘客ID
- Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 堂兄弟/妹个数
- Parch => 父母与小孩个数
- Ticket => 船票信息
- Fare => 票价
- Cabin => 客舱
- Embarked => 登船港口
可以看到其实特征不是很多。
接下来具体看看各个特征中的情况:
train.info()
 看到了样本大小是891个。还有各个特征的数据类型。好多数据有缺失值,Age和Cabin缺失比较严重。
看到了样本大小是891个。还有各个特征的数据类型。好多数据有缺失值,Age和Cabin缺失比较严重。
处理数据
处理一下数据中的缺失值:
1.Embarked特征缺失了两个数据,用众数填充。
train.Embarked[train.Embarked.isnull()] = train.Embarked.dropna().mode().values
2.Cabin特征缺失的太多了,先不考虑,赋给U0做个标记。
train["Cabin"] = train["Cabin"].fillna("U0")
3.Age特征比较重要,可以用机器学习来预测缺失值。这里选择随机森林来预测一下。
from sklearn.ensemble import RandomForestRegressor as RFR
#先选取数值特征进行预测
age_df = train[["Age","Survived","Fare","Parch","SibSp","Pclass"]]
age_df_notnull = age_df.loc[(train["Age"].notnull())]
age_df_isnull = age_df.loc[(train["Age"].isnull())]
X = age_df_notnull.values[:,1:]
Y = age_df_notnull.values[:,0]
clf = RFR(n_estimators = 1000,n_jobs = -1)
clf.fit(X,Y)
pred = clf.predict(age_df_isnull.values[:,1:])
train.loc[train["Age"].isnull(),["Age"]] = pred
查看一下处理之后缺失值情况
train.info()

可以看到缺失值处理完全。
分析特征关系
先来看一下整体的生存率。
train["Survived"].value_counts().plot.pie(autopct = "%1.2f%%")
plt.show()

看到大概有38.38%的活下来了。
看看各个特征和存活之间的关系。
1.Sex特征:
sns.countplot(x = "Sex",hue = "Survived",data = train)

比较直观的看到女士的存活率比男士高,哈哈哈,数据证明电影里的绅士风度没有骗人。是个有用的特征。
2.船舱等级Pclass:
sns.countplot(x = "Pclass",hue = "Survived",data = train)

看到船舱等级一定程度上代表了社会地位。高级一点的船舱,获救几率大一些。
4.Age年龄特征:
sns.violinplot(x = "Survived",y = "Age",data = train,split = True)
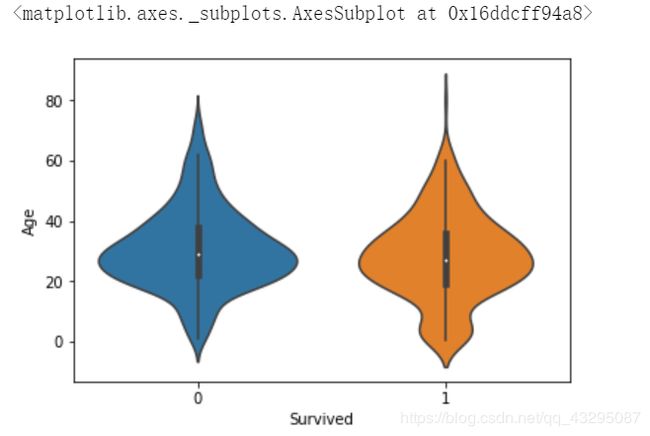
从小提琴图中看到大概16-30左右人的生存率比较低。
因为年龄这个特征比较重要下面还会分析,
不同性别下,年龄
sns.violinplot(x = "Sex",y = "Age",hue = "Survived",data = train,split = True)

从这个图中就比较能看出刚刚那个结论。
不同船舱下的,年龄
sns.violinplot(x = "Pclass",y = "Age",hue = "Survived",data = train,split = True)

年龄的总体分布
train.boxplot(column = "Age")

看到年龄分布,大部分人都是20-40岁。60岁以上的人很少。
不同年龄下的存活率
plt.figure(figsize = (20,5))
train["Age_int"] = train["Age"].astype(int)
av_age = train[["Age_int","Survived"]].groupby(["Age_int"],as_index = False).mean()
sns.barplot(x = "Age_int",y = "Survived",data = av_age)

从这幅图更可以看到年龄和存活率的关系,依据这幅图,一会对年龄特征做分箱处理。
分箱处理
bins = [0,10,20,30,40,50,60,70,80]
train["Age-Cut"] = pd.cut(train["Age"],bins)
5.称呼与存活关系 Name
提取称呼
train["Title"] = train["Name"].str.extract(' ([A-Za-z]+)\.',expand = False)
#观察下称呼,和社会地位有关
pd.crosstab(train["Title"],train["Sex"])
plt.figure(figsize = (20,5))
sns.countplot(x = "Title",hue = "Survived",data = train)

称呼一定程度上可以看出一个的性别和社会地位,所以还是有些用的。
观察下名字的长度与生存率的关系
plt.figure(figsize = (20,5))
train["Name-Len"] = train["Name"].apply(len)
sns.countplot(x = "Name-Len",hue = "Survived",data = train)
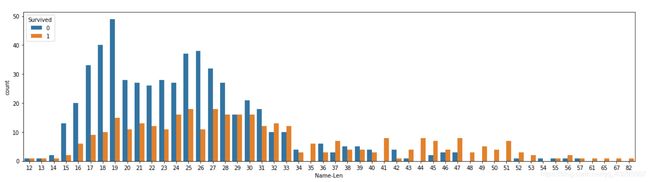
可以看到好像名字越长,存活率好像越大啊。是不是玄学啊。仔细想一下,好像社会地位越高的人,名字越长。
6.兄弟姐妹
sns.countplot(x = "SibSp", hue = "Survived",data = train)

好像有那么一点关系,我们把它分为有无兄弟姐妹看看。
#用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
#用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
sibsp_df = train[train["SibSp"] != 0]
no_sibsp_df = train[train["SibSp"] == 0]
sibsp_df["Survived"].value_counts().plot.pie(labels = ["N","Y"],autopct = "%1.2f%%")
plt.xlabel("有兄弟姐妹")
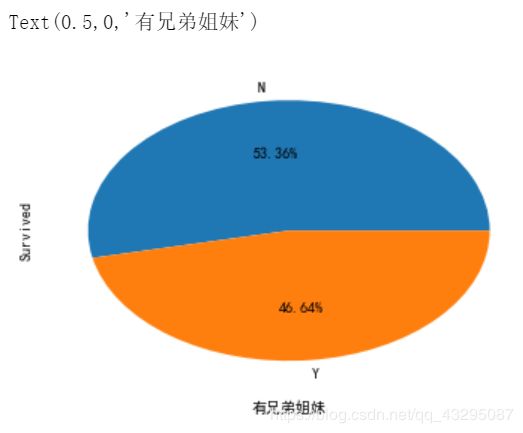
no_sibsp_df["Survived"].value_counts().plot.pie(labels = ["N","Y"],autopct = "%1.2f%%")
plt.xlabel("没有兄弟姐妹")

有兄弟姐妹一起存活率要高一点,可以互帮互助嘛。
7.有无父母子女
sns.countplot(x = "Parch",hue = "Survived",data = train)

其实也可以从图中看出,有父母子女在存活率会大一点。
8.票价分布
来看看不同船舱等级的票价
train.boxplot(column = "Fare",by = "Pclass")
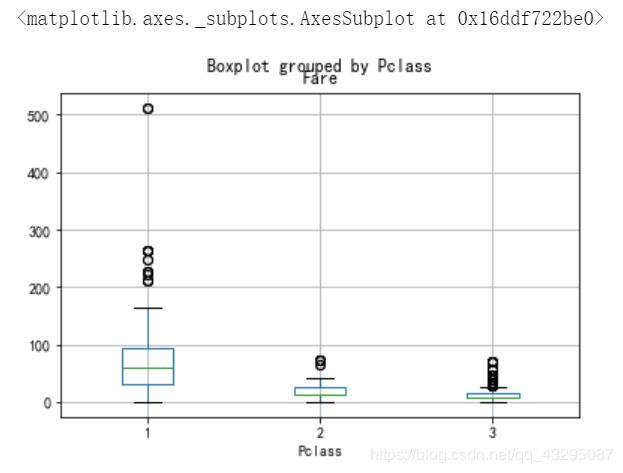
船舱等级1果然是最贵的。
将票价分箱处理一下
bins = [0,50,100,200,300,500]
train["Fare-Cut"] = pd.cut(train["Fare"],bins)
sns.countplot(x = "Fare-Cut",hue = "Survived",data = train)

看到票价越高,存活率越高,很直觉。
9.船舱类型
由于缺失值较多,就按有无类型划分数据类别
train["Cabin"] = train["Cabin"].apply(lambda x:0 if x == "U0" else 1)
sns.countplot(x = "Cabin",hue = "Survived",data = train)
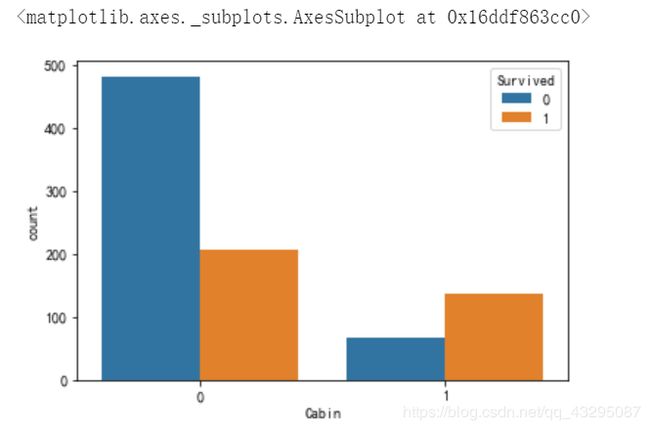
看到有船舱类型的存活率会高一点。我大胆猜测一下,是不是一般工作人员只记录了达官显贵们的船舱类型。
10.港口
sns.factorplot('Embarked', 'Survived', data=train, size=3, aspect=2)

看到在C港口上船存活率高一点,可能就像是贵宾通道一样的意思。
特征分析告一段落,基本清楚各个特征对存活率的影响。
接下来可以删除,提取,构造特征。
labels = train["Survived"]
features = train.drop(["Survived","PassengerId","Name","Age","Age-1","Ticket"],axis = 1)
因为有些特征不是数值类型的,这里可以对非数值类型的特征进行对热编码处理。
features = pd.get_dummies(features)
encoded = list(features.columns)
对测试集也处理一下。
test["Age"] = test["Age"].fillna(float(27))
bins = [0,10,20,30,40,50,60,70,80]
test["Age-Cut"] = pd.cut(test["Age"],bins)
test['SibSp']=test['SibSp'].map(lambda x: 'small' if x<1 else 'middle' if x<3 else 'large')
test['Parch']=test['Parch'].map(lambda x: 'small' if x<1 else 'middle' if x<4 else 'large')
test['Fare']=test['Fare'].map(lambda x: 'poor' if x<2.5 else 'rich')
test["Cabin"] = np.where(test["Cabin"].isnull(),"no","yes")
test = test.drop(["PassengerId","Name","Ticket","Age"],axis = 1)
test = pd.get_dummies(test)
模型构建
这里我选择了好几个模型,支持向量机,决策树,随机森林,
AdaBoost,KNN,xgboost。最后进行了简单的模型融合。
导入相关的库。
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.metrics import accuracy_score,roc_auc_score
from time import time
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from xgboost.sklearn import XGBClassifier
这里使用的网格搜索自动调参
先编写一个函数
def fit_model(alg,parameters):
X = np.array(features)
y = np.array(labels)
scorer = make_scorer(roc_auc_score) #评分标准
grid = GridSearchCV(alg,parameters,scoring = scorer,cv = 5)
start = time() #计时
grid = grid.fit(X,y)
end = time()
t = round(end - start,3)
print("搜索时间:",t)
print(grid.best_params_) #输出最佳参数
return grid
定义初始化模型
alg1 = DecisionTreeClassifier(random_state = 15)
alg2 = SVC(probability = True,random_state = 15) #使用roc_auc_score作为评分标准要把probability打开
alg3 = RandomForestClassifier(random_state = 15)
alg4 = AdaBoostClassifier(random_state = 15)
alg5 = KNeighborsClassifier(n_jobs = -1)
alg6 = XGBClassifier(random_state = 15,n_jobs = -1)
列出需要调整的参数
parameters1={'max_depth':range(1,10),'min_samples_split':range(2,10)}
parameters2 = {"C":range(1,20), "gamma": [0.05,0.1,0.15,0.2,0.25]}
parameters3_1 = {'n_estimators':range(10,200,10)}
parameters3_2 = {'max_depth':range(1,10),'min_samples_split':range(2,10)}
parameters4 = {'n_estimators':range(10,200,10),'learning_rate':[i/10.0 for i in range(5,15)]}
parameters5 = {'n_neighbors':range(2,10),'leaf_size':range(10,80,20)}
parameters6_1 = {'n_estimators':range(10,200,10)}
parameters6_2 = {'max_depth':range(1,10),'min_child_weight':range(1,10)}
parameters6_3 = {'subsample':[i/10.0 for i in range(1,10)], 'colsample_bytree':[i/10.0 for i in range(1,10)]}#搜索空间太大,分三次调整参数
参数比较多的,可以分几次调参。
下面开始调参:
决策树模型
clf1 = fit_model(alg1,parameters1)

SVM模型
clf2 = fit_model(alg2,parameters2)

随机森林模型
第一次调参
clf3_m1 = fit_model(alg3,parameters3_1)

第二次调参
alg3=RandomForestClassifier(random_state=15,n_estimators=50)
clf3=fit_model(alg3,parameters3_2)

AdaBoost模型
clf4 = fit_model(alg4,parameters4)

KNN模型
clf5 = fit_model(alg5,parameters5)

Xgboost模型
第一次调参
clf6_m1 = fit_model(alg6,parameters6_1)
 第二次调参
第二次调参
alg6 = XGBClassifier(n_estimators=100,random_state=15,n_jobs=-1)
clf6_m2 = fit_model(alg6,parameters6_2)

第三次调参
alg6=XGBClassifier(n_estimators=100,max_depth=3,min_child_weight=1,random_state=15,n_jobs=-1)
clf6 = fit_model(alg6,parameters6_3)

以上模型训练完全。可以去看看预测的结果。上传到Kaggle,去看看准确率。或者自己之前在train数据集中可以留一部分数据做验证集,来观察模型的效果,也能进一步画ROC曲线来分析模型的效果。
这里我写了一个保存各个模型预测结果的函数,方便一会进行简单的模型融合(投票).
def save(clf,i):
pred = clf.predict(np.array(test))
sub = pd.DataFrame({"Survived":pred})
sub.to_csv("D:/Data mining/taitannikehao/res_tan_{}.csv".format(i),index = False)
i = 1
for clf in [clf1,clf2,clf3,clf4,clf5,clf6]:
save(clf,i)
i += 1
定义一个投票函数
def major(i):
vote = 0
for clf in [clf1,clf2,clf3,clf4,clf5,clf6]:
pred = clf.predict(np.array(test)[i:i+1])
vote += pred
if vote > 3:
result = 1
else:
result = 0
return result
#进行投票
pred = []
for i in range(len(test)):
pred.append(major(i))
sub_1 = pd.DataFrame({'Survived': pred})
sub_1.to_csv("D:/Data mining/taitannikehao/res_tan_7.csv")
好了现在一个小项目就告一段落了。
如你所见,其实我们花了大部分时间在数据处理,特征构建上,花在模型上的时间要少一些。的确是这样。大概7:3的时间花费把。
本文讲的很宏观,一些细节上可能没有写。模型的构建,也可以进一步优化。
关于以后更加细节的东西我会整理整理,和大家交流。比如:各种机器学习的算法,使用场景,如何模型调参,特征工程怎么去做等等。
如果有小伙伴对这个项目,感兴趣,想要数据集或者源代码,可以给我留言。因为源代码是在jupyter notebook所以不太方便直接,复制粘贴分享上来。有兴趣的话也可以加我的QQ:1251640350.大家可以交流交流。