Sqoop1.4.6的安装及命令行使用
- 1.Sqoop简介
- 2.下载Sqoop
- 3.安装Sqoop
- 3.1解压
- 3.2将解压后的文件移动到/usr/local/目录下
- 3.3配置sqoop-env.sh
- 3.4配置系统环境变量
- 3.5验证安装是否成功
- 3.6去除警告
- 4.Sqoop的命令使用
- 4.1Windows本机下安装MySQL服务
- 4.2查看所有的数据库
- 4.3列出数据库下所有表
- 4.4数据库表中的数据导入到HDFS
- 4.4.1import
- 4.4.2-m –target-dir
- 4.4.3-z ––append --where
- 4.4.4--null-string --null-non-string
- 4.5HDFS数据导出到数据库表
Sqoop1.4.6的安装及命令行使用
1.Sqoop简介
Sqoop,用来在关系型数据库与Hadoop之间进行数据的导入导出,将数据从数据库中导入到HDFS中进行数据处理,是一种转换工具。
Sqoop分为两大版本sqoop1和sqoop2,两者完全不兼容,1.4.x为sqoop1,1.99.x为sqoop2。
2.下载Sqoop
下载Sqoop,这里选择1.4.6当前稳定版本

选择原生的Sqoop,sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz。
3.安装Sqoop
3.1解压
拷贝到Linux系统/root/Downloads/下并解压
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
3.2将解压后的文件移动到/usr/local/目录下
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ /usr/local/
3.3配置sqoop-env.sh
在目录/usr/local/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/conf下,将sqoop-env-template.sh文件重命名为sqoop-env.sh,mv sqoop-env-template.sh sqoop-env.sh;编辑此文件vi sqoop-env.sh,指定Hadoop的安装路径信息(Hadoop2.6.4伪分布式)
export HADOOP_COMMON_HOME=/usr/local/hadoop-2.6.4
export HADOOP_MAPRED_HOME=/usr/local/hadoop-2.6.43.4配置系统环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop-2.6.4
export SQOOP_HOME=/usr/local/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SQOOP_HOME/binsource /etc/profile使配置立即生效
3.5验证安装是否成功
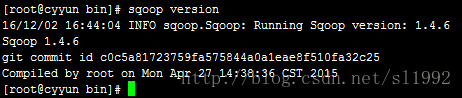
sqoop version

此时Sqoop安装成功了。
3.6去除警告
发现执行命令时出现了警告,因为还没有设置HBASE_HOME,HCAT_HOME等,在/usr/local/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/bin目录下修改configure-sqoop文件,找到echo输出的上述信息,注释掉

再次执行时发现警告没有了,执行sqoop help可以查看所有命令
4.Sqoop的命令使用
4.1Windows本机下安装MySQL服务
下载MySQL,本机使用的是5.5.53版本的,64位和32位都能使用。数据库用户名密码本机设置的是root和root。安装好后启动MySQL服务。
4.2查看所有的数据库
sqoop list-databases --connect jdbc:mysql://192.168.1.97:3306/ --username root \
--password root其中1.97是Windows系统的IP地址(MySQL服务是安装在Windows下的)。
出现找不到驱动包的错误提示
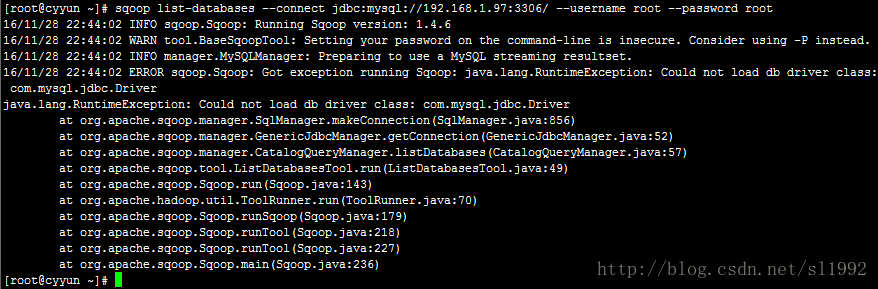
解决:在$SQOOP_HOME/lib目录下放置对应数据库的驱动包,本机连接的是MySQL,下载MySQL和Java的驱动包,本机使用的版本是mysql-connector-java-5.1.36-bin.jar,将其拷贝到$SQOOP_HOME/lib目录下。
再次执行sqoop命令,出现Host 'cyyun' is not allowed to connect to this MySQL server
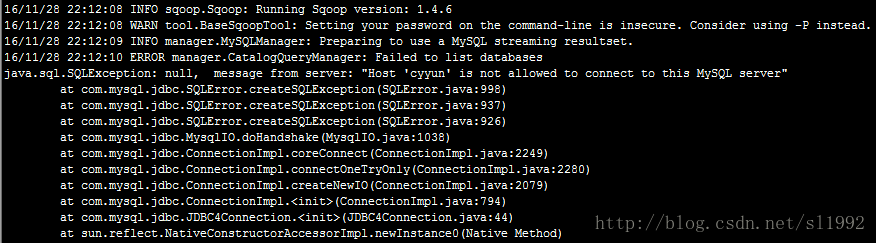
解决:需要开启MySQL的远程帐号
Windows下打开MySQL命令行模式

输入密码进入mysql命令行后,执行命令
mysql>grant all privileges on *.* to root@'192.168.1.200' identified by 'root';
mysql>flush privileges;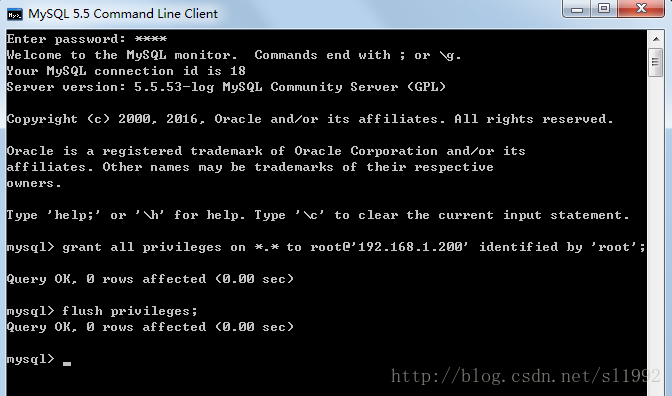
*.*代表全部数据库的全部表授权,也可以指定数据库授权,如test_db.*;
all privileges代表全部权限,也可以insert,update,delete,create,drop等;
允许root用户在192.168.1.200(Linux系统的IP)这个IP进行远程登陆,并设置root用户的密码为root。
flush privileges告诉服务器重新加载授权表。
执行命令后,看到运行结果,可以看到mysql、sakila、test和world数据库
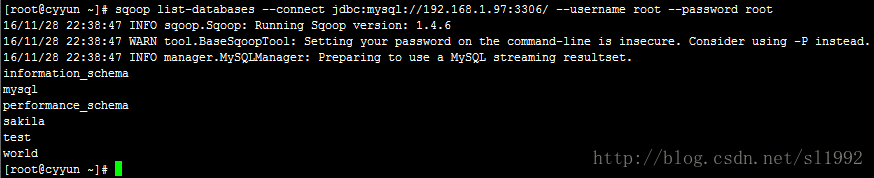
4.3列出数据库下所有表
sqoop list-tables --connect jdbc:mysql://192.168.1.97:3306/sakila --username root \
--password root列出sakila数据库下的所有表,包括视图

4.4数据库表中的数据导入到HDFS
注:要先启动Hadoop的集群
sqoop命令实际上都是转换为map任务,import命令是将DB数据导入HDFS。
本机建了一个数据库mydb,库下有一个user表,数据如下:
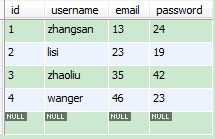
4.4.1import
执行命令
sqoop import --connect jdbc:mysql://192.168.1.97:3306/mydb -username root \
-password root --table user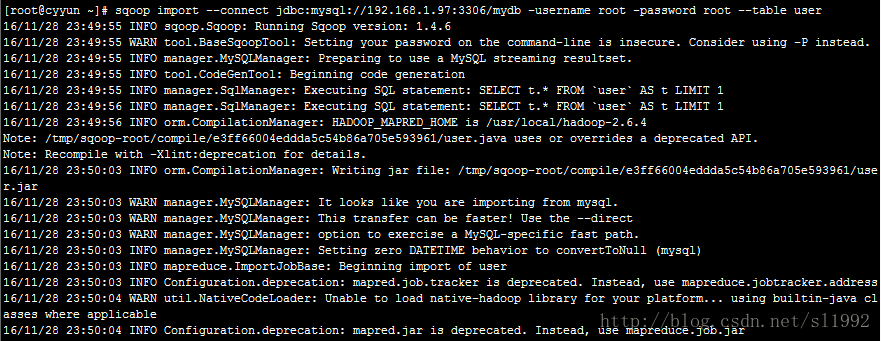
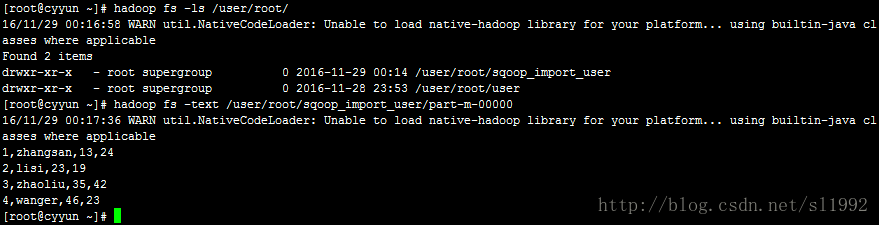
在HDFS的/user/root目录下生成了user目录

Sqoop默认会生成4个文件,一条记录一个文件,大于4条记录则最多生成4个文件。
查看结果:
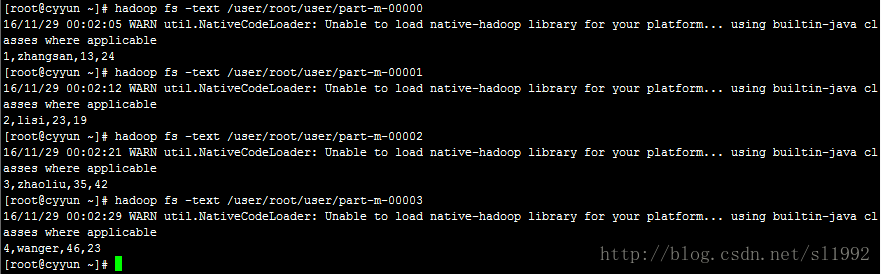
4.4.2-m –target-dir
执行命令
sqoop import --connect jdbc:mysql://192.168.1.97:3306/mydb -username root \
-password root --table user -m 1 --target-dir sqoop_import_user-m 1 表示map任务数
--target-dir sqoop_import_user 表示指定生成文件的名称,在HDFS中的路径为/user/root/sqoop_import_user/part-m-00000
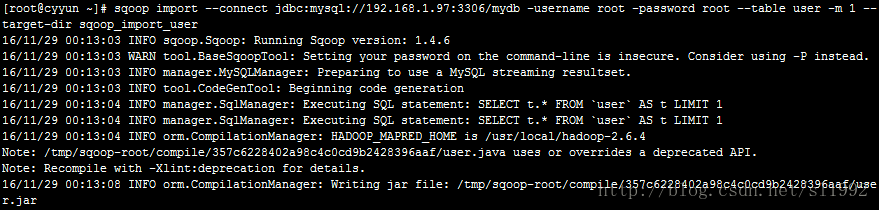
结果查看:
4.4.3-z ––append --where
执行命令
sqoop import --connect jdbc:mysql://192.168.1.97:3306/mydb -username root \
-password root --table user -m 1 --target-dir import_user -z --append --where "id=3"-z 使用压缩格式导入,导入的文件使用-text查看
--append 追加数据,如果指定路径下存在文件part-m-00000则会生成新的文件,如part-m-00001
--where 根据字段过滤,先全部从数据库读出然后再根据条件过滤将符合要求的记录写入HDFS
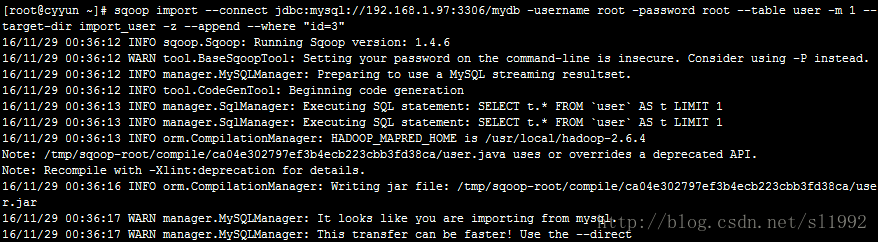
查看结果:

4.4.4--null-string --null-non-string
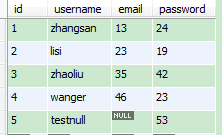
在user表添加一条记录测试null-string
执行命令
sqoop import --connect jdbc:mysql://192.168.1.97:3306/mydb -username root \
-password root --table user -m 1 --target-dir import_user \
--append --null-string "#" --null-non-string "-1"--null-string "#" 表示当varchar字段为null时以#代替
--null-non-string "-1" 表示当非varchar字段为null以-1代替
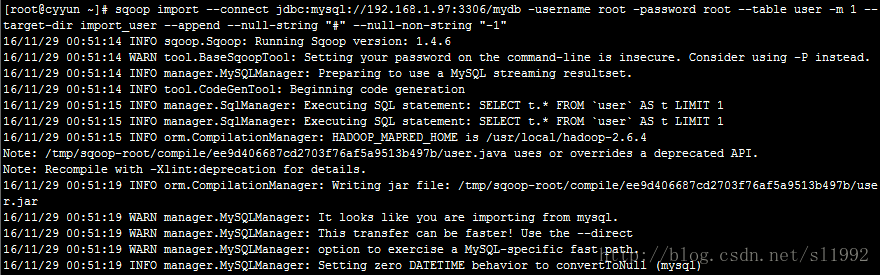
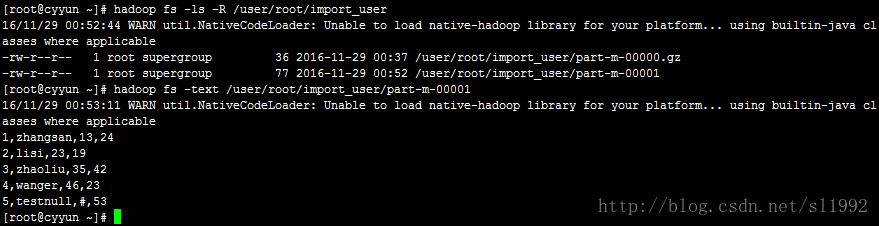
结果查看,第5条null记录用#代替了:
4.5HDFS数据导出到数据库表
在mydb数据库下建空表user2(可复制user表的结构)
从HDFS导出数据到MySQL的表user2中:
sqoop export --connect jdbc:mysql://192.168.1.97:3306/mydb --table user2 \
--username root --password root --export-dir \
hdfs://cyyun:9000/user/root/sqoop_import_user/part-m-00000--export-dir 表示HDFS要导出数据的目录
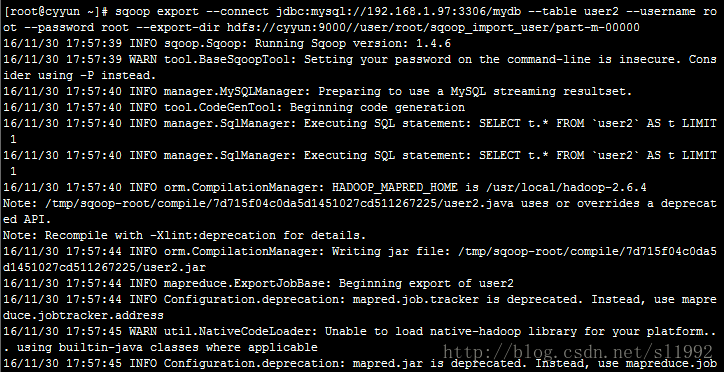
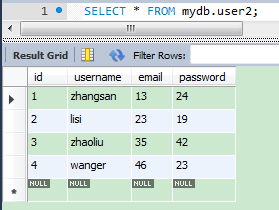
/sqoop_import_user/part-m-00000此文件有四条记录,查看MySQL的user2表数据:
本文参考:
http://blog.csdn.net/ty4315/article/details/53056124
http://blog.csdn.net/ty4315/article/details/53056151