ELK的介绍和搭建
ELK是一整套解决方案,很多公司在使用如:Sina、携程、华为、美团等.
ELK分别代表(都是开源软件)
– Elasticsearch:负责日志检索和储存;
– Logstash:负责日志的收集和分析、处理;
– Kibana:负责日志的可视化.
ELK可以做什么?
ELK组件在海量日志系统的运维中,可用于解决:
– 分布式日志数据集中式查询和管理;
– 系统监控,包含系统硬件和应用各个组件的监控:
– 故障排查:
– 安全信息和事件管理:
– 报表功能.
Elasticsearch是一个基于Lucene的搜索服务器, 它提供了一个分布式多用户能力的全文搜索引擎.
主要特点:
– 实时分析;
– 分布式实时文件存储,并将每一个字段都编入索引;
– 文档导向,所有的对象全部是文档;
– 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas);
– 接口友好,支持JSON.
相关概念:
– Node: 装有一个ES服务器的节点;
– Cluster: 有多个Node组成的集群;
– Document: 一个可被搜索的基础信息单元;
– Index: 拥有相似特征的文档的集合;
– Type: 一个索引中可以定义一种或多种类型;
– Filed: 是ES的最小单位,相当于数据的某一列;
– Shards: 索引的分片,每一个分片就是一个Shard;
– Replicas: 索引的拷贝.
下表为elk的整体机构列表:
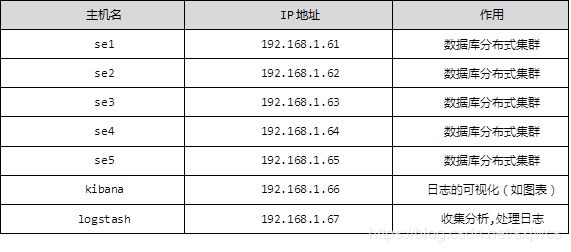
注: se1~se5 下面改为了,es1~es5, IP地址61~67改为了51~57 , 为了测试结果,额外的搭建了一台apache的web服务器(httpd).
整个架构的流程是这样的:
web_httpd: 由于logstash依赖JAVA环境,而且占用资源非常大, 因此使用更轻量的filebeat插件来替代, 这个插件主要用来接收beats类软件发送过来的数据, 然后通过端口:5044将日志信息发送给logstash;
Logstash: 提供数据采集、加工处理以及传输, 将日志数据以正则表达式的方式结构化,定义索引,将数据输出到ES集群中;
ES集群: 界面显示索引列表, 提供了一个分布式多用户能力的全文搜索引擎,能够达到实时搜索;
Kbana: 数据可视化平台工具, 通过ES上的索引调用日志信息, 将数据绘制成图表(柱状图. 图表等).
ELK架构整体主机名和IP地址部署:
ansible: 192.168.1.50 es1:192.168.1.51 es2: 192.168.1.52 es3: 192.168.1.53 es4: 192.168.1.54
es5:192.168.1.55 kibana: 192.168.1.56 logstash: 192.168.1.57 web_server: 192.168.1.58
ES集群的搭建:
首先,准备6台服务器,五台搭建ES集群,一台用于搭建ansible服务器,用来完成五台服务的批量配置:
五台ES服务器,主机名和ip地址如下:
ansible: 192.168.1.50 es1:192.168.1.51 es2: 192.168.1.52 es3: 192.168.1.53 es4: 192.168.1.54
es5:192.168.1.55
我们先来部署一台es1 ,其他的可以是相同的操作,也可以使用ansible批量部署:
<一>设置ip与主机名称对应关系(写上本机的IP地址和主机名):
[root@es1 ~]# vim /etc/hostname
192.168.1.51 es1
<二>准备需要的软件包(这些软件包都在真机上的/ftp/elk/下):
elasticsearch-2.3.4.rpm
kibana-4.5.2-1.x86_64.rpm
logstash-2.3.4-1.noarch.rpm
<三>为了可以在虚拟机上通过yum安装这些软件(通过yum来解决软件直接的依赖关系),我们需要制作一个yum仓库:
[root@room9pc01 ~]# cd /var/ftp/elk
[root@room9pc01 ~]# createrepo . //生成yum依赖的文件repodata,现在可以配置yum了
配置虚拟机es1的yum:
[root@es1 ~]# vim /etc/yum.repos.d/local.repo
[local_repo]
name=CentOS-$releasever - Base
baseurl="ftp://192.168.1.254/centos-1804"
enabled=1
gpgcheck=0
[elk_repo]
name=elk - Base
baseurl="ftp://192.168.1.254/elk"
enabled=1
gpgcheck=0[root@es1 ~]#yum repolist //会发现在原本的软件数量上加了3个
[root@es1 ~]# yum -y install elasticsearch
<四>安装JDK,Elasticsearch要求至少Java 7,一般推荐使用OpenJDK 1.8
[root@es1 ~]#yum list | grep openjdk
[root@es1 ~]#yum install -y java-1.8.0-openjdk
<五>安装ES并修改配置文件
[root@es1 ~]#yum -y install elasticsearch
[root@es1 ~]#rpm -qc elasticsearch //这条命令可以看到所有的elasticsearch配置文件[root@es1 ~]#vim /etc/elasticsearch/elasticsearch.yml
cluster.name: myelk //设置ES集群的名字,必须都一样
node.name: es1 //当前节点的名字
network.host: 0.0.0.0 //网络中的所有主机都可以访问
discovery.zen.ping.unicast.hosts: [“es1", “es2", “es3"] //discovery为集群节点机器,不需要全部配置<六>启动服务
– 启动服务并设开机自启
[root@es1 ~]#systemctl start elasticsearch
[root@es1 ~]#systemctl enable elasticsearch
<七>验证
[root@es1 ~]#netstat -ntulp //能够看到9200,9300被监听
下面我是通过ansible来对ES集群进行批量部署:
进入ansible服务器(ansible的配置,和创建工作目录):
[root@room9pc01 ~]#ssh [email protected]
<一>创建秘钥对,将公钥发送给其他服务器:
[root@ansible ~]#ssh-keygen -N ' ' -f /root/.ssh/id_rsa //其中' '这个是单引,里面没有空格,是为了让大家好识别
[root@ansible ~]#for i in {51..55};do scp-copy-id [email protected].$i;done //这个是群发,也可以单个发送
<二>安装ansible自动.批处理工具
[root@ansible ~]#yum -y install ansible
<三>创建和配置工作目录
[root@ansible ~]#mkdir /opt/xxoo //在ansible中,我们一般不会更改原始配置文件,它的工作机制使我们可以自己创建文件夹,只需在相同的配置文件中写入必须的配置项即可
[root@ansible ~]#cd /opt/xxoo
[root@ansible xxoo]#vim ansible.cfg
[defaults]
inventory = /opt/xxoo/hosts //inventory 指定主机列表的名字和位置
host_key_checking = False //ansible在每台服务器上执行的时候都会提示,我们不让提示[root@ansible xxoo]#vim hosts //配置主机列表
[es] //集合名字自己定义
es1
es2
es3
es4
es5
[root@ansible xxoo]#ansible es -m ping //绿色字体,出现Pang,则成功部署
[root@ansible xxoo]#vim es.yml
---
- hosts: es
remote_user: root
tasks:
- copy:
src: local.repo
dest: /etc/yum.repos.d/local.repo
owner: root
group: root
mode: 0644
- name: install the latest version of Apache
yum:
name: elasticsearch
state: installed
- name: install java-1.8.0-openjdk.x86_64
yum:
name: java-1.8.0-openjdk.x86_64
state: installed
tags: openjdk
notify:
restart es
- template: //es的配置文件中有变量,此模块支持变量
src: elasticsearch.yml
dest: /etc/elasticsearch/elasticsearch.yml
owner: root
group: root
mode: 0644
tags: es_change //打标记,使可以单个调用此模块
notify: //若此模块执行,就通知handlers执行
- restart es
handlers:
- name: restart es
service:
name: elasticsearch
state: restarted
enabled: yes[root@ansible xxoo]#ansible-playbook es.yml //ansible 执行yml实现批量部署
<三>验证集群, 使用ES内置字段 _cluster/health
[root@ansible xxoo]#curl http://192.168.1.51:9200/_cluster/health?pretty //也可以在firefox浏览器中输入
我的输出结果如下:
{
"cluster_name" : "nsd1902",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 5,
"number_of_data_nodes" : 5,
"active_primary_shards" : 40,
"active_shards" : 85,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
这里有一点需要说明,如果有的服务器没有起来,我们需要把所有ES服务器都停掉,先开启其中一台,再开启其他的,你先开启的就是主服务器.
为了可以清晰的管理,我们需要使用ES插件:(可以在web页面中通过图形化界面管理log日志)
ES常用插件:
• head插件
– 它展现ES集群的拓扑结构,并且可以通过它来进行索引(Index)和节点(Node)级别的操作
– 它提供一组针对集群的查询API,并将结果以json和表格形式返回
– 它提供一些快捷菜单,用以展现集群的各种状态
• kopf插件
– 是一个ElasticSearch的管理工具
– 它提供了对ES集群操作的API
• bigdesk插件
– 是elasticsearch的一个集群监控工具
– 可以通过它来查看es集群的各种状态,如:cpu、内存
使用情况,索引数据、搜索情况,http连接数等
<三>安装插件:
elasticsearch-head-master.zip
elasticsearch-kopf-master.zip
bigdesk-master.zip
插件在任意一台主机上都可以安装:(这里需要用plugin的绝对路径来安装)
[root@es5 ~]#/usr/share/elasticsearch/bin/plugin list //查看安装的插件
[root@es5 ~]#/usr/share/elasticsearch/bin/plugin install elasticsearch-head-master.zip
[root@es5 ~]#usr/share/elasticsearch/bin/plugin install elasticsearch-kopf-master.zip
[root@es5 ~]#usr/share/elasticsearch/bin/plugin install bigdesk-master.zip这里必须使用 url 的方式进行安装,如果文件在本地,我们也需要使用 file:// 的方式指定路径,例如文件在/tmp/xxx下面,我们要写成 file:///tmp/xxx , 删除使用remove 指令.
[root@es5 ~]#/usr/share/elasticsearch/bin/plugin list //查看三个插件是否都安装成功
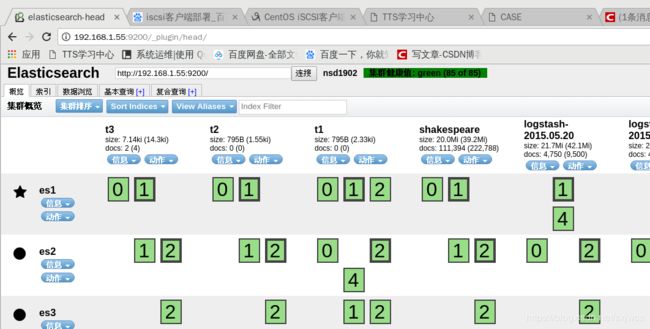
<四>测试
firefox地址栏输入:192.168.1.55:9200/_plugin/head/
Kibana的安装与配置:[192.168.1.56]
kibana是一个数据可视化平台工具
特点:
– 灵活的分析和可视化平台
– 实时总结流量和数据的图表
– 为不同的用户显示直观的界面
– 即时分享和嵌入的仪表板
[root@kibana ~]# yum -y install kibana //安装kibana,通过下载的rpm包
kibana 默认安装在 /opt/kibana下面,配置文件在/opt/kibana/config/kibana.yml
[root@kibana ~]#rpm -qc kibana //也可以通过这条命令,列出kibana的配置文件
[root@kibana ~]#vim /opt/kibana/config/kibana.yml //修改配置文件
server.port: 5601 //服务器端口
server.host: "0.0.0.0" //任何主机都可以访问到kibana
elasticsearch.url: "http://es3:9200" //设置连接哪一台elasticsearch服务器,任意一台都可以
kibana.index: ".kibana" //kibana的索引,它会在elasticsearch页面中显示
kibana.defaultAppId: "discover" //kibana的默认显示页面
elasticsearch.pingTimeout: 1500 //elasticsearch的ping超时时间,超过则表示连接断开
elasticsearch.requestTimeout: 30000 //elasticsearch的访问超时时间
elasticsearch.startupTimeout: 5000 //elasticsearch的启动超时时间[root@kibana ~]#systemctl start kibana //启动服务
[root@kibana ~]#systemctl enable kibana //设置开机自启动
[root@kibana ~]# ss -ntulp //查看5601端口是否启动
打开浏览器,输入192.168.1.56:5601
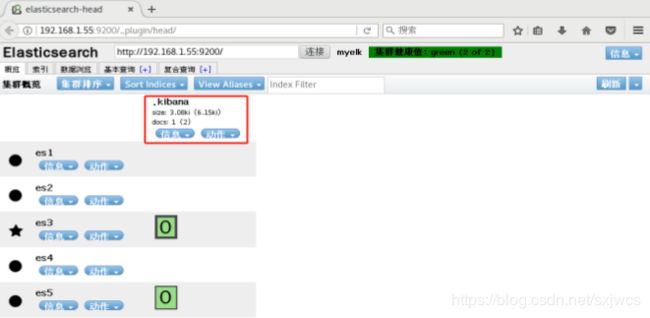
修改Kibana的配置文件后启动Kibana,然后查看ES集群,如果出现.kibana Index表示Kibana与ES集群
连接成功.
部署web_httpd:[192.168.1.58]
[root@httpds ~]# yum -y install httpd //部署web服务器
[root@httpds ~]# systemctl restart httpd //重启服务
[root@httpds ~]# systemctl enable httpd //设置开机自启
[root@httpds ~]# echo "hello world" > /var/www/html/index.html //写一个简单的测试页面
安装与配置filebeat:
[root@httpds ~]# yum –y install filebeat
[root@httpds ~]#vim etc/filebeat/filebeat.yml
paths:
15 - /var/log/httpd/access_log #设置http的日志文件路径
31 input_type: log #输入的文件格式是日志文件
72 document_type: apache_log #这是一个文件索引,会在logstash中调用
278 logstash:
279 # The Logstash hosts
280 hosts: ["192.168.1.58:5044"] #设置要监听logstash的主机名和端口号[root@httpds ~]#systemctl restart filebeat //重启服务
[root@httpds ~]#systemctl enable filebeat //设置开机自启
部署Logstash:[192.168.1.57]
• 是一个数据采集、加工处理以及传输的工具
• 特点:
– 所有类型的数据集中处理
– 不同模式和格式数据的正常化
– 自定义日志格式的迅速扩展
– 为自定义数据源轻松添加插件
Logstash安装:
[root@logstash ~]#yum -y install java-1.8.0-openjdk //logstash依赖java环境,需要安装openjdk
[root@logstash ~]#yum –y install logstash //Logstash默认安装在/opt/logstash目录下
由于Logstash没有默认的配置文件,需要手动配置:
[root@logstash ~]#mkdir /etc/logstash
[root@logstash ~]#vim /etc/logstash/logstash.confinput{
# file { #file指名进入的数据是文件类型
# path => ["/var/log/a.log"] #本机的服务日志文件路径,因为web服务在web_httpd上搭建的,所一这一段注释掉
# start_position => "beginning" #设置logstash从日志的哪个位置开始读取
# sincedb_path => "/dev/null" #logstash默认会从上次读取的位置继续读,将存储读取位置的文件路径设置为黑洞,会始终从头开始读取日志信息
# type => "testlog" #给日志打一个标记
# }
beats { #打开5044端口,通过filebeat从web_http服务器上获取日志信息
port => 5044
}
}
filter{ #filter是对数据进行处理的过程
grok { #grok正则分组匹配,利用正则表达式将日志机构化,可以自己写,也可以直接调用软件的宏
match => {"message" => "%{COMBINEDAPACHELOG}"}
}
}
output{ #将处理过的数据传输给ES集群
if [type] == "apache_log" { #判断语句,apache_log是在filebeat中定义的: document_type: apache_log (72行)
elasticsearch {
hosts => ["es1:9200","es2:9200","es3:9200"] #主机名多定义几台,备用
index => "weblog" #定义这个日志的索引名
flush_size => 2000
idle_flush_time => 10
}
}
}[root@logstash ~]#/opt/logstash/bin/logstash -f /etc/logstash/logstash.conf #启动logstash服务图像 小部件
然后进入kibana界面中,输入索引weblog,就可以开始绘制图表了